1. Introduction
Dans les articles précédents, j'ai présenté comment analyser le code source Python pour blogs d'exploration, InfoBox Wikipédia et images, le lien de l'article est le suivant :
[Apprentissage Python] Exploration simple de la boîte de message du langage de programmation Wikipédia
[Apprentissage Python] Analyse simple des articles de blog par un robot d'exploration Web et introduction d'idées
[Apprentissage Python] Exploration simple des images dans la galerie d'images du site Web
Le code de base est le suivant :
# coding=utf-8
import urllib
import re
#下载静态HTML网页
url='http://www.csdn.net/'
content = urllib.urlopen(url).read()
open('csdn.html','w+').write(content)
#获取标题
title_pat=r'(?<=<title>).*?(?=</title>)'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, content)
title=title_obj.group()
print title
#获取超链接内容
href = r'<a href=.*?>(.*?)</a>'
m = re.findall(href,content,re.S|re.M)
for text in m:
print unicode(text,'utf-8')
break #只输出一个urlCopier après la connexion
Le résultat de sortie est le suivant :
>>>
CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台
登录
>>>
Copier après la connexion
Le code de base pour le téléchargement d'images est le suivant :
import os
import urllib
class AppURLopener(urllib.FancyURLopener):
version = "Mozilla/5.0"
urllib._urlopener = AppURLopener()
url = "http://creatim.allyes.com.cn/imedia/csdn/20150228/15_41_49_5B9C9E6A.jpg"
filename = os.path.basename(url)
urllib.urlretrieve(url , filename)Copier après la connexion
Mais la méthode ci-dessus d'analyse HTML pour explorer le contenu d'un site Web présente de nombreux inconvénients, tels que :
1. Les expressions régulières sont contraint par le code source HTML, et non Dépend de la structure plus abstraite ; de petits changements dans la structure de la page Web peuvent entraîner un arrêt du programme.
2. Le programme doit analyser le contenu en fonction du code source HTML réel. Il peut rencontrer des fonctionnalités HTML telles que des entités de caractères telles que &, et doit spécifier un traitement tel que , hyperliens d’icônes, indices, etc. Contenu différent.
3. Les expressions régulières ne sont pas entièrement lisibles et les codes HTML et expressions de requête plus complexes deviendront compliqués.
Comme "Python Basics Tutorial (2nd Edition)" adopte deux solutions : la première consiste à utiliser le programme Tidy (bibliothèque Python) et l'analyse XHTML ; la seconde est pour utiliser la bibliothèque BeautifulSoup.
2. Installation et introduction Bibliothèque Beautiful Soup
Beautiful Soup est un analyseur HTML/XML écrit en Python , qui peut gérez bien les balises irrégulières et générez des arbres d’analyse. Il fournit des opérations simples et couramment utilisées pour naviguer, rechercher et modifier les arbres d'analyse. Cela peut considérablement économiser votre temps de programmation.
Comme le dit le livre : "Vous n'avez pas écrit ces mauvaises pages Web, vous avez simplement essayé d'en obtenir des données. Maintenant, vous vous en fichez". à quoi ressemble le code HTML, l'analyseur vous aide à y parvenir."
Adresse de téléchargement :
http://www .php.cn/
setup.py installer
 Il est recommandé de se référer au chinois pour les méthodes d'utilisation spécifiques : http://www.php.cn/
Il est recommandé de se référer au chinois pour les méthodes d'utilisation spécifiques : http://www.php.cn/
Parmi elles, l'utilisation de BeautifulSoup est brièvement expliqué, en utilisant l'exemple officiel de "Alice au pays des merveilles":
Contenu de sortie
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#获取BeautifulSoup对象并按标准缩进格式输出
soup = BeautifulSoup(html_doc)
print(soup.prettify())
Copier après la connexion
Sortie selon la structure de format indenté standard
Comme suit : Ce qui suit est une introduction simple et rapide à la bibliothèque BeautifulSoup : (Référence : Documentation officielle)
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>Copier après la connexion
Si vous souhaitez obtenir tout le contenu textuel dans l'article, le code est le suivant :
'''获取title值'''
print soup.title
# <title>The Dormouse's story</title>
print soup.title.name
# title
print unicode(soup.title.string)
# The Dormouse's story
'''获取<p>值'''
print soup.p
# <p class="title"><b>The Dormouse's story</b></p>
print soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
'''从文档中找到<a>的所有标签链接'''
print soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
for link in soup.find_all('a'):
print(link.get('href'))
# http://www.php.cn/
# http://www.php.cn/
# http://www.php.cn/
print soup.find(id='link3')
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>Copier après la connexion
'''从文档中获取所有文字内容'''
print soup.get_text()
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
Copier après la connexion
同时在这过程中你可能会遇到两个典型的错误提示:
1.ImportError: No module named BeautifulSoup
当你成功安装BeautifulSoup 4库后,“from BeautifulSoup import BeautifulSoup”可能会遇到该错误。
其中的原因是BeautifulSoup 4库改名为bs4,需要使用“from bs4 import BeautifulSoup”导入。
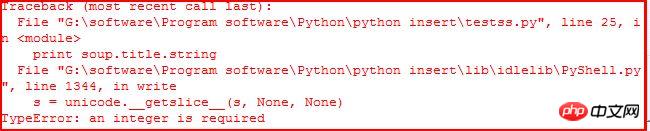
2.TypeError: an integer is required
当你使用“print soup.title.string”获取title的值时,可能会遇到该错误。如下:
它应该是IDLE的BUG,当使用命令行Command没有任何错误。参考:stackoverflow。同时可以通过下面的代码解决该问题:
print unicode(soup.title.string)
print str(soup.title.string)
三. Beautiful Soup常用方法介绍
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment|
1.Tag标签
tag对象与XML或HTML文档中的tag相同,它有很多方法和属性。其中最重要的属性name和attribute。用法如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id="start"><b>The Dormouse's story</b></p>
"""
soup = BeautifulSoup(html)
tag = soup.p
print tag
# <p class="title" id="start"><b>The Dormouse's story</b></p>
print type(tag)
# <class 'bs4.element.Tag'>
print tag.name
# p 标签名字
print tag['class']
# [u'title']
print tag.attrs
# {u'class': [u'title'], u'id': u'start'}Copier après la connexion
使用BeautifulSoup每个tag都有自己的名字,可以通过.name来获取;同样一个tag可能有很多个属性,属性的操作方法与字典相同,可以直接通过“.attrs”获取属性。至于修改、删除操作请参考文档。
2.NavigableString
字符串常被包含在tag内,Beautiful Soup用NavigableString类来包装tag中的字符串。一个NavigableString字符串与Python中的Unicode字符串相同,并且还支持包含在遍历文档树和搜索文档树中的一些特性,通过unicode()方法可以直接将NavigableString对象转换成Unicode字符串。
print unicode(tag.string)
# The Dormouse's story
print type(tag.string)
# <class 'bs4.element.NavigableString'>
tag.string.replace_with("No longer bold")
print tag
# <p class="title" id="start"><b>No longer bold</b></p>Copier après la connexion
这是获取“The Dormouse's story
”中tag = soup.p的值,其中tag中包含的字符串不能编辑,但可通过函数replace_with()替换。
NavigableString 对象支持遍历文档树和搜索文档树 中定义的大部分属性, 并非全部。尤其是一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法。
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
3.Beautiful Soup对象
该对象表示的是一个文档的全部内容,大部分时候可以把它当做Tag对象,它支持遍历文档树和搜索文档树中的大部分方法。
注意:因为BeautifulSoup对象并不是真正的HTML或XML的tag,所以它没有name和 attribute属性,但有时查看它的.name属性可以通过BeautifulSoup对象包含的一个值为[document]的特殊实行.name实现——soup.name。
Beautiful Soup中定义的其它类型都可能会出现在XML的文档中:CData , ProcessingInstruction , Declaration , Doctype 。与 Comment 对象类似,这些类都是 NavigableString 的子类,只是添加了一些额外的方法的字符串独享。
4.Command注释
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有些特殊对象容易让人担心——注释。Comment对象是一个特殊类型的NavigableString对象。
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
print type(comment)
# <class 'bs4.element.Comment'>
print unicode(comment)
# Hey, buddy. Want to buy a used parser?
Copier après la connexion
介绍完这四个对象后,下面简单介绍遍历文档树和搜索文档树及常用的函数。
5.遍历文档树
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点。BeautifulSoup提供了许多操作和遍历子节点的属性。引用官方文档中爱丽丝例子:
操作文档最简单的方法是告诉你想获取tag的name,如下:
soup.head# <head><title>The Dormouse's story</title></head>soup.title# <title>The Dormouse's story</title>soup.body.b# <b>The Dormouse's story</b>
Copier après la connexion
注意:通过点取属性的放是只能获得当前名字的第一个Tag,同时可以在文档树的tag中多次调用该方法如soup.body.b获取标签中第一个标签。
如果想得到所有的标签,使用方法find_all(),在前面的Python爬取维基百科等HTML中我们经常用到它+正则表达式的方法。
soup.find_all('a')# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Copier après la connexion
子节点:在分析HTML过程中通常需要分析tag的子节点,而tag的 .contents 属性可以将tag的子节点以列表的方式输出。字符串没有.contents属性,因为字符串没有子节点。
head_tag = soup.head
head_tag
# <head><title>The Dormouse's story</title></head>
head_tag.contents
[<title>The Dormouse's story</title>]
title_tag = head_tag.contents[0]
title_tag
# <title>The Dormouse's story</title>
title_tag.contents
# [u'The Dormouse's story']
Copier après la connexion
通过tag的 .children 生成器,可以对tag的子节点进行循环:
for child in title_tag.children:
print(child)
# The Dormouse's storyCopier après la connexion
子孙节点:同样 .descendants 属性可以对所有tag的子孙节点进行递归循环:
for child in head_tag.descendants:
print(child)
# <title>The Dormouse's story</title>
# The Dormouse's storyCopier après la connexion
父节点:通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,标签是标签的父节点,换句话就是增加一层标签。<br/> <span style="color:#ff0000">注意:文档的顶层节点比如<html>的父节点是 BeautifulSoup 对象,BeautifulSoup 对象的 .parent 是None。</span><br/></span></strong></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">title_tag = soup.titletitle_tag# <title>The Dormouse's story</title>title_tag.parent# <head><title>The Dormouse's story</title></head>title_tag.string.parent# <title>The Dormouse's story</title></pre><div class="contentsignin">Copier après la connexion</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">兄弟节点</span>:因为<b>标签和<c>标签是同一层:他们是同一个元素的子节点,所以<b>和<c>可以被称为兄弟节点。一段文档以标准格式输出时,兄弟节点有相同的缩进级别.在代码中也可以使用这种关系。</span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>")print(sibling_soup.prettify())# <html># <body># <a># <b># text1# </b># <c># text2# </c># </a># </body># </html></pre><div class="contentsignin">Copier après la connexion</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点。<b>标签有.next_sibling 属性,但是没有.previous_sibling 属性,因为<b>标签在同级节点中是第一个。同理<c>标签有.previous_sibling 属性,却没有.next_sibling 属性:</span></span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup.b.next_sibling# <c>text2</c>sibling_soup.c.previous_sibling# <b>text1</b></pre><div class="contentsignin">Copier après la connexion</div></div><p><strong><span style="font-size:18px"> 介绍到这里基本就可以实现我们的BeautifulSoup库爬取网页内容,而网页修改、删除等内容建议大家阅读文档。下一篇文章就再次爬取维基百科的程序语言的内容吧!希望文章对大家有所帮助,如果有错误或不足之处,还请海涵!建议大家阅读官方文档和《Python基础教程》书。</span><br><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px"> </span><span style="font-size:18px; font-family:Arial; line-height:26px"><span style="color:#ff0000"> (By:Eastmount 2015-3-25 下午6点</span></span><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px">
</span>http://www.php.cn/<span style="font-family:Arial; color:#ff0000"><span style="font-size:18px; line-height:26px">)</span></span></strong><br></p>
<p></p>
<p><br></p>
<p class="pmark"><br></p>
<p>
</p><p>Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!</p>
</div>
</div>
<div class="wzconShengming_sp">
<div class="bzsmdiv_sp">Déclaration de ce site Web</div>
<div>Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn</div>
</div>
</div>
<ins class="adsbygoogle"
style="display:block"
data-ad-format="autorelaxed"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="2507867629"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="AI_ToolDetails_main4sR">
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="3653428331"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<!-- <div class="phpgenera_Details_mainR4">
<div class="phpmain1_4R_readrank">
<div class="phpmain1_4R_readrank_top">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/hotarticle2.png" alt="" />
<h2>Article chaud</h2>
</div>
<div class="phpgenera_Details_mainR4_bottom">
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/1796780570.html" title="R.E.P.O. Crystals d'énergie expliqués et ce qu'ils font (cristal jaune)" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Crystals d'énergie expliqués et ce qu'ils font (cristal jaune)</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>3 Il y a quelques semaines</span>
<span>By 尊渡假赌尊渡假赌尊渡假赌</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/1796780641.html" title="R.E.P.O. Meilleurs paramètres graphiques" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Meilleurs paramètres graphiques</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>3 Il y a quelques semaines</span>
<span>By 尊渡假赌尊渡假赌尊渡假赌</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/1796785841.html" title="Assassin's Creed Shadows: Solution d'énigmes de coquille" class="phpgenera_Details_mainR4_bottom_title">Assassin's Creed Shadows: Solution d'énigmes de coquille</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>2 Il y a quelques semaines</span>
<span>By DDD</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/1796780520.html" title="R.E.P.O. Comment réparer l'audio si vous n'entendez personne" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Comment réparer l'audio si vous n'entendez personne</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>3 Il y a quelques semaines</span>
<span>By 尊渡假赌尊渡假赌尊渡假赌</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/1796779766.html" title="WWE 2K25: Comment déverrouiller tout dans Myrise" class="phpgenera_Details_mainR4_bottom_title">WWE 2K25: Comment déverrouiller tout dans Myrise</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>4 Il y a quelques semaines</span>
<span>By 尊渡假赌尊渡假赌尊渡假赌</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3_more">
<a href="https://www.php.cn/fr/article.html">Afficher plus</a>
</div>
</div>
</div> -->
<div class="phpgenera_Details_mainR3">
<div class="phpmain1_4R_readrank">
<div class="phpmain1_4R_readrank_top">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/hottools2.png" alt="" />
<h2>Outils d'IA chauds</h2>
</div>
<div class="phpgenera_Details_mainR3_bottom">
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/fr/ai/undresserai-undress" title="Undresser.AI Undress" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411540686492.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Undresser.AI Undress" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/fr/ai/undresserai-undress" title="Undresser.AI Undress" class="phpmain_tab2_mids_title">
<h3>Undresser.AI Undress</h3>
</a>
<p>Application basée sur l'IA pour créer des photos de nu réalistes</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/fr/ai/ai-clothes-remover" title="AI Clothes Remover" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411552797167.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="AI Clothes Remover" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/fr/ai/ai-clothes-remover" title="AI Clothes Remover" class="phpmain_tab2_mids_title">
<h3>AI Clothes Remover</h3>
</a>
<p>Outil d'IA en ligne pour supprimer les vêtements des photos.</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/fr/ai/undress-ai-tool" title="Undress AI Tool" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173410641626608.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Undress AI Tool" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/fr/ai/undress-ai-tool" title="Undress AI Tool" class="phpmain_tab2_mids_title">
<h3>Undress AI Tool</h3>
</a>
<p>Images de déshabillage gratuites</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/fr/ai/clothoffio" title="Clothoff.io" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411529149311.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Clothoff.io" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/fr/ai/clothoffio" title="Clothoff.io" class="phpmain_tab2_mids_title">
<h3>Clothoff.io</h3>
</a>
<p>Dissolvant de vêtements AI</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/fr/ai/ai-hentai-generator" title="AI Hentai Generator" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173405034393877.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="AI Hentai Generator" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/fr/ai/ai-hentai-generator" title="AI Hentai Generator" class="phpmain_tab2_mids_title">
<h3>AI Hentai Generator</h3>
</a>
<p>Générez AI Hentai gratuitement.</p>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3_more">
<a href="https://www.php.cn/fr/ai">Afficher plus</a>
</div>
</div>
</div>
<script src="https://sw.php.cn/hezuo/cac1399ab368127f9b113b14eb3316d0.js" type="text/javascript"></script>
<div class="phpgenera_Details_mainR4">
<div class="phpmain1_4R_readrank">
<div class="phpmain1_4R_readrank_top">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/hotarticle2.png" alt="" />
<h2>Article chaud</h2>
</div>
<div class="phpgenera_Details_mainR4_bottom">
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/1796780570.html" title="R.E.P.O. Crystals d'énergie expliqués et ce qu'ils font (cristal jaune)" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Crystals d'énergie expliqués et ce qu'ils font (cristal jaune)</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>3 Il y a quelques semaines</span>
<span>By 尊渡假赌尊渡假赌尊渡假赌</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/1796780641.html" title="R.E.P.O. Meilleurs paramètres graphiques" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Meilleurs paramètres graphiques</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>3 Il y a quelques semaines</span>
<span>By 尊渡假赌尊渡假赌尊渡假赌</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/1796785841.html" title="Assassin's Creed Shadows: Solution d'énigmes de coquille" class="phpgenera_Details_mainR4_bottom_title">Assassin's Creed Shadows: Solution d'énigmes de coquille</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>2 Il y a quelques semaines</span>
<span>By DDD</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/1796780520.html" title="R.E.P.O. Comment réparer l'audio si vous n'entendez personne" class="phpgenera_Details_mainR4_bottom_title">R.E.P.O. Comment réparer l'audio si vous n'entendez personne</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>3 Il y a quelques semaines</span>
<span>By 尊渡假赌尊渡假赌尊渡假赌</span>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/1796779766.html" title="WWE 2K25: Comment déverrouiller tout dans Myrise" class="phpgenera_Details_mainR4_bottom_title">WWE 2K25: Comment déverrouiller tout dans Myrise</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<span>4 Il y a quelques semaines</span>
<span>By 尊渡假赌尊渡假赌尊渡假赌</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3_more">
<a href="https://www.php.cn/fr/article.html">Afficher plus</a>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3">
<div class="phpmain1_4R_readrank">
<div class="phpmain1_4R_readrank_top">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/hottools2.png" alt="" />
<h2>Outils chauds</h2>
</div>
<div class="phpgenera_Details_mainR3_bottom">
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/fr/toolset/development-tools/92" title="Bloc-notes++7.3.1" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab96f0f39f7357.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="Bloc-notes++7.3.1" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/fr/toolset/development-tools/92" title="Bloc-notes++7.3.1" class="phpmain_tab2_mids_title">
<h3>Bloc-notes++7.3.1</h3>
</a>
<p>Éditeur de code facile à utiliser et gratuit</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/fr/toolset/development-tools/93" title="SublimeText3 version chinoise" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab97a3baad9677.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="SublimeText3 version chinoise" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/fr/toolset/development-tools/93" title="SublimeText3 version chinoise" class="phpmain_tab2_mids_title">
<h3>SublimeText3 version chinoise</h3>
</a>
<p>Version chinoise, très simple à utiliser</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/fr/toolset/development-tools/121" title="Envoyer Studio 13.0.1" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab97ecd1ab2670.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="Envoyer Studio 13.0.1" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/fr/toolset/development-tools/121" title="Envoyer Studio 13.0.1" class="phpmain_tab2_mids_title">
<h3>Envoyer Studio 13.0.1</h3>
</a>
<p>Puissant environnement de développement intégré PHP</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/fr/toolset/development-tools/469" title="Dreamweaver CS6" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58d0e0fc74683535.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="Dreamweaver CS6" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/fr/toolset/development-tools/469" title="Dreamweaver CS6" class="phpmain_tab2_mids_title">
<h3>Dreamweaver CS6</h3>
</a>
<p>Outils de développement Web visuel</p>
</div>
</div>
<div class="phpmain_tab2_mids_top">
<a href="https://www.php.cn/fr/toolset/development-tools/500" title="SublimeText3 version Mac" class="phpmain_tab2_mids_top_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58d34035e2757995.png?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="SublimeText3 version Mac" />
</a>
<div class="phpmain_tab2_mids_info">
<a href="https://www.php.cn/fr/toolset/development-tools/500" title="SublimeText3 version Mac" class="phpmain_tab2_mids_title">
<h3>SublimeText3 version Mac</h3>
</a>
<p>Logiciel d'édition de code au niveau de Dieu (SublimeText3)</p>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3_more">
<a href="https://www.php.cn/fr/ai">Afficher plus</a>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR4">
<div class="phpmain1_4R_readrank">
<div class="phpmain1_4R_readrank_top">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/hotarticle2.png" alt="" />
<h2>Sujets chauds</h2>
</div>
<div class="phpgenera_Details_mainR4_bottom">
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/gmailyxdlrkzn" title="Où se trouve l'entrée de connexion pour la messagerie Gmail ?" class="phpgenera_Details_mainR4_bottom_title">Où se trouve l'entrée de connexion pour la messagerie Gmail ?</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/eyess.png" alt="" />
<span>7474</span>
</div>
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/tiezi.png" alt="" />
<span>15</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/cakephp-tutor" title="Tutoriel CakePHP" class="phpgenera_Details_mainR4_bottom_title">Tutoriel CakePHP</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/eyess.png" alt="" />
<span>1377</span>
</div>
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/tiezi.png" alt="" />
<span>52</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/steamdzhmcssmgs" title="Quel est le format du nom de compte de Steam" class="phpgenera_Details_mainR4_bottom_title">Quel est le format du nom de compte de Steam</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/eyess.png" alt="" />
<span>77</span>
</div>
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/tiezi.png" alt="" />
<span>11</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/winactivationkeyper" title="Clé d&amp;amp;amp;amp;amp;amp;#39;activation Win11 permanent" class="phpgenera_Details_mainR4_bottom_title">Clé d&amp;amp;amp;amp;amp;amp;#39;activation Win11 permanent</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/eyess.png" alt="" />
<span>49</span>
</div>
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/tiezi.png" alt="" />
<span>19</span>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR4_bottoms">
<a href="https://www.php.cn/fr/faq/newyorktimesdailybrief" title="NYT Connexions Indices et réponses" class="phpgenera_Details_mainR4_bottom_title">NYT Connexions Indices et réponses</a>
<div class="phpgenera_Details_mainR4_bottoms_info">
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/eyess.png" alt="" />
<span>19</span>
</div>
<div class="phpgenera_Details_mainR4_bottoms_infos">
<img src="/static/imghw/tiezi.png" alt="" />
<span>31</span>
</div>
</div>
</div>
</div>
<div class="phpgenera_Details_mainR3_more">
<a href="https://www.php.cn/fr/faq/zt">Afficher plus</a>
</div>
</div>
</div>
</div>
</div>
<div class="Article_Details_main2">
<div class="phpgenera_Details_mainL4">
<div class="phpmain1_2_top">
<a href="javascript:void(0);" class="phpmain1_2_top_title">Related knowledge<img
src="/static/imghw/index2_title2.png" alt="" /></a>
</div>
<div class="phpgenera_Details_mainL4_info">
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/fr/faq/1796792956.html" title="MySQL doit-il payer" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/202412/27/2024122710314954443.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="MySQL doit-il payer" />
</a>
<a href="https://www.php.cn/fr/faq/1796792956.html" title="MySQL doit-il payer" class="phphistorical_Version2_mids_title">MySQL doit-il payer</a>
<span class="Articlelist_txts_time">Apr 08, 2025 pm 05:36 PM</span>
<p class="Articlelist_txts_p">MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/fr/faq/1796792845.html" title="Comment utiliser MySQL après l'installation" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/000/887/227/174124098373422.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Comment utiliser MySQL après l'installation" />
</a>
<a href="https://www.php.cn/fr/faq/1796792845.html" title="Comment utiliser MySQL après l'installation" class="phphistorical_Version2_mids_title">Comment utiliser MySQL après l'installation</a>
<span class="Articlelist_txts_time">Apr 08, 2025 am 11:48 AM</span>
<p class="Articlelist_txts_p">L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/fr/faq/1796792826.html" title="MySQL ne peut pas être installé après le téléchargement" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/000/465/014/174125286330709.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="MySQL ne peut pas être installé après le téléchargement" />
</a>
<a href="https://www.php.cn/fr/faq/1796792826.html" title="MySQL ne peut pas être installé après le téléchargement" class="phphistorical_Version2_mids_title">MySQL ne peut pas être installé après le téléchargement</a>
<span class="Articlelist_txts_time">Apr 08, 2025 am 11:24 AM</span>
<p class="Articlelist_txts_p">Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/fr/faq/1796792821.html" title="Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/000/887/227/174125358798898.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution" />
</a>
<a href="https://www.php.cn/fr/faq/1796792821.html" title="Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution" class="phphistorical_Version2_mids_title">Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution</a>
<span class="Articlelist_txts_time">Apr 08, 2025 am 11:21 AM</span>
<p class="Articlelist_txts_p">Le fichier de téléchargement mysql est corrompu, que dois-je faire? Hélas, si vous téléchargez MySQL, vous pouvez rencontrer la corruption des fichiers. Ce n'est vraiment pas facile ces jours-ci! Cet article expliquera comment résoudre ce problème afin que tout le monde puisse éviter les détours. Après l'avoir lu, vous pouvez non seulement réparer le package d'installation MySQL endommagé, mais aussi avoir une compréhension plus approfondie du processus de téléchargement et d'installation pour éviter de rester coincé à l'avenir. Parlons d'abord de la raison pour laquelle le téléchargement des fichiers est endommagé. Il y a de nombreuses raisons à cela. Les problèmes de réseau sont le coupable. L'interruption du processus de téléchargement et l'instabilité du réseau peut conduire à la corruption des fichiers. Il y a aussi le problème avec la source de téléchargement elle-même. Le fichier serveur lui-même est cassé, et bien sûr, il est également cassé si vous le téléchargez. De plus, la numérisation excessive "passionnée" de certains logiciels antivirus peut également entraîner une corruption des fichiers. Problème de diagnostic: déterminer si le fichier est vraiment corrompu</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/fr/faq/1796792841.html" title="Comment optimiser les performances de la base de données après l'installation de MySQL" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/000/887/227/174124566531558.png?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Comment optimiser les performances de la base de données après l'installation de MySQL" />
</a>
<a href="https://www.php.cn/fr/faq/1796792841.html" title="Comment optimiser les performances de la base de données après l'installation de MySQL" class="phphistorical_Version2_mids_title">Comment optimiser les performances de la base de données après l'installation de MySQL</a>
<span class="Articlelist_txts_time">Apr 08, 2025 am 11:36 AM</span>
<p class="Articlelist_txts_p">L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/fr/faq/1796792888.html" title="MySQL a-t-il besoin d'Internet" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/202501/09/2025010911214941664.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="MySQL a-t-il besoin d'Internet" />
</a>
<a href="https://www.php.cn/fr/faq/1796792888.html" title="MySQL a-t-il besoin d'Internet" class="phphistorical_Version2_mids_title">MySQL a-t-il besoin d'Internet</a>
<span class="Articlelist_txts_time">Apr 08, 2025 pm 02:18 PM</span>
<p class="Articlelist_txts_p">MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/fr/faq/1796792966.html" title="Comment optimiser les performances MySQL pour les applications de haute charge?" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/001/246/273/173518851168623.png?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Comment optimiser les performances MySQL pour les applications de haute charge?" />
</a>
<a href="https://www.php.cn/fr/faq/1796792966.html" title="Comment optimiser les performances MySQL pour les applications de haute charge?" class="phphistorical_Version2_mids_title">Comment optimiser les performances MySQL pour les applications de haute charge?</a>
<span class="Articlelist_txts_time">Apr 08, 2025 pm 06:03 PM</span>
<p class="Articlelist_txts_p">Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.</p>
</div>
<div class="phphistorical_Version2_mids">
<a href="https://www.php.cn/fr/faq/1796792815.html" title="Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL" class="phphistorical_Version2_mids_img">
<img onerror="this.onerror=''; this.src='/static/imghw/default1.png'"
src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/000/000/164/174125574360343.png?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL" />
</a>
<a href="https://www.php.cn/fr/faq/1796792815.html" title="Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL" class="phphistorical_Version2_mids_title">Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL</a>
<span class="Articlelist_txts_time">Apr 08, 2025 am 11:18 AM</span>
<p class="Articlelist_txts_p">MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration</p>
</div>
</div>
<a href="https://www.php.cn/fr/be/" class="phpgenera_Details_mainL4_botton">
<span>See all articles</span>
<img src="/static/imghw/down_right.png" alt="" />
</a>
</div>
</div>
</div>
</main>
<footer>
<div class="footer">
<div class="footertop">
<img src="/static/imghw/logo.png" alt="">
<p>Formation PHP en ligne sur le bien-être public,Aidez les apprenants PHP à grandir rapidement!</p>
</div>
<div class="footermid">
<a href="https://www.php.cn/fr/about/us.html">À propos de nous</a>
<a href="https://www.php.cn/fr/about/disclaimer.html">Clause de non-responsabilité</a>
<a href="https://www.php.cn/fr/update/article_0_1.html">Sitemap</a>
</div>
<div class="footerbottom">
<p>
© php.cn All rights reserved
</p>
</div>
</div>
</footer>
<input type="hidden" id="verifycode" value="/captcha.html">
<script>layui.use(['element', 'carousel'], function () {var element = layui.element;$ = layui.jquery;var carousel = layui.carousel;carousel.render({elem: '#test1', width: '100%', height: '330px', arrow: 'always'});$.getScript('/static/js/jquery.lazyload.min.js', function () {$("img").lazyload({placeholder: "/static/images/load.jpg", effect: "fadeIn", threshold: 200, skip_invisible: false});});});</script>
<script src="/static/js/common_new.js"></script>
<script type="text/javascript" src="/static/js/jquery.cookie.js?1744462780"></script>
<script src="https://vdse.bdstatic.com//search-video.v1.min.js"></script>
<link rel='stylesheet' id='_main-css' href='/static/css/viewer.min.css?2' type='text/css' media='all' />
<script type='text/javascript' src='/static/js/viewer.min.js?1'></script>
<script type='text/javascript' src='/static/js/jquery-viewer.min.js'></script>
<script type="text/javascript" src="/static/js/global.min.js?5.5.53"></script>
<script>
var _paq = window._paq = window._paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function () {
var u = "https://tongji.php.cn/";
_paq.push(['setTrackerUrl', u + 'matomo.php']);
_paq.push(['setSiteId', '9']);
var d = document,
g = d.createElement('script'),
s = d.getElementsByTagName('script')[0];
g.async = true;
g.src = u + 'matomo.js';
s.parentNode.insertBefore(g, s);
})();
</script>
<script>
// top
layui.use(function () {
var util = layui.util;
util.fixbar({
on: {
mouseenter: function (type) {
layer.tips(type, this, {
tips: 4,
fixed: true,
});
},
mouseleave: function (type) {
layer.closeAll("tips");
},
},
});
});
document.addEventListener("DOMContentLoaded", (event) => {
// 定义一个函数来处理滚动链接的点击事件
function setupScrollLink(scrollLinkId, targetElementId) {
const scrollLink = document.getElementById(scrollLinkId);
const targetElement = document.getElementById(targetElementId);
if (scrollLink && targetElement) {
scrollLink.addEventListener("click", (e) => {
e.preventDefault(); // 阻止默认链接行为
targetElement.scrollIntoView({
behavior: "smooth"
}); // 平滑滚动到目标元素
});
} else {
console.warn(
`Either scroll link with ID '${scrollLinkId}' or target element with ID '${targetElementId}' not found.`
);
}
}
// 使用该函数设置多个滚动链接
setupScrollLink("Article_Details_main1L2s_1", "article_main_title1");
setupScrollLink("Article_Details_main1L2s_2", "article_main_title2");
setupScrollLink("Article_Details_main1L2s_3", "article_main_title3");
setupScrollLink("Article_Details_main1L2s_4", "article_main_title4");
setupScrollLink("Article_Details_main1L2s_5", "article_main_title5");
setupScrollLink("Article_Details_main1L2s_6", "article_main_title6");
// 可以继续添加更多的滚动链接设置
});
window.addEventListener("scroll", function () {
var fixedElement = document.getElementById("Article_Details_main1Lmain");
var scrollTop = window.scrollY || document.documentElement.scrollTop; // 兼容不同浏览器
var clientHeight = window.innerHeight || document.documentElement.clientHeight; // 视口高度
var scrollHeight = document.documentElement.scrollHeight; // 页面总高度
// 计算距离底部的距离
var distanceToBottom = scrollHeight - scrollTop - clientHeight;
// 当距离底部小于或等于300px时,取消固定定位
if (distanceToBottom <= 980) {
fixedElement.classList.remove("Article_Details_main1Lmain");
fixedElement.classList.add("Article_Details_main1Lmain_relative");
} else {
// 否则,保持固定定位
fixedElement.classList.remove("Article_Details_main1Lmain_relative");
fixedElement.classList.add("Article_Details_main1Lmain");
}
});
</script>
</body>
</html>

 développement back-end
développement back-end

 Il est recommandé de se référer au chinois pour les méthodes d'utilisation spécifiques : http://www.php.cn/
Il est recommandé de se référer au chinois pour les méthodes d'utilisation spécifiques : http://www.php.cn/