

Une brève introduction au cluster distribué MySQL MyCAT (1)

Après un long moment, j'ai pensé à mettre à jour mon blog. Récemment, j'ai changé la base de données d'Oracle en MySQL Après l'avoir étudiée pendant un moment, j'ai l'impression que la version communautaire de MySQL est inférieure à Oracle en tout. aspects. Oracle est vraiment pratique !
D'accord, pas de bêtises, cette fois je vais enregistrer quelque chose sur la construction d'un cluster distribué MySQL, MyCAT, je le comprends comme un agent MySQL.
-------------------------------------------------------------- -- ------------------CONSEILS importants---------------------- - ----------------------------------------
L'équipe MyCAT a publié la version 1.4Alpha, qui a corrigé de nombreux bugs et ajouté de nouvelles fonctionnalités
Le blogueur a utilisé la version 1.3 pour les tests, le test est donc avec la dernière version. Les résultats peuvent être incohérents !
-------------------------------------- --- ----------------Présentation générale------------- -------------------------------------------------- ---
L'introduction en arrière-plan de MyCAT est simplement ignorée, ce qui est inutile. Bien sûr, c'est quelque chose développé par JAVA, qui doit être compris ~.
------------------------------------------------------ ------ --------------Le prédécesseur de MyCAT-------------- --------------- ------------------------------------ -----------
Le prédécesseur de MyCAT est Alibaba a officiellement open source le middleware de base de données Cobar le 19 juin 2012. Cobar Le prédécesseur est Amoeba, qui est depuis longtemps open source. Cependant, après le départ de son auteur Chen Siru pour se rendre à Shanda, Alibaba a pris en compte en interne la stabilité d'Amoeba, les performances et le support fonctionnel, ainsi que d'autres facteurs, ont rétabli une équipe de projet et remplacé le nom est Cobar. Cobar est fabriqué par
Le middleware de traitement distribué MySQL open source d'Alibaba peut fournir des services de données massifs dans un environnement distribué, tout comme une base de données traditionnelle.
Cobar est recherché par les programmeurs depuis sa naissance, mais depuis 2013, il n'y a eu quasiment plus de mises à jour ultérieures. Dans cette situation, MyCAT a vu le jour. Il a été développé sur la base du produit open source Cobar d'Alibaba, la stabilité, la fiabilité, l'excellente architecture et les performances, ainsi que de nombreux cas d'utilisation matures, ont fait de MyCAT un bon produit dès le début. , debout sur les épaules de géants, MyCAT peut voir plus loin. ------------------------------------------------------ ------ ------------------Comment utiliser MyCAT---------------- ------- ---------------------------------- . Par exemple, dans cette configuration fichier, il est configuré Deux bases de données, weixin et yixin, contiennent chacune une table utilisateur.
-------------------------------- ----------------------------Fonctionnalités importantes de MyCAT------------ --- ----------------------------------------------- --- ---
Prend en charge la norme SQL 92
Prend en charge le cluster MySQL et peut être utilisé comme proxy
Prend en charge Connexion JDBC à ORACLE et DB2, SQL Server, simulez-le en tant que serveur MySQL ;
Prend en charge Galera pour le cluster mysql, le cluster percona ou le cluster mariadb, fournissant un cluster de partage de données haute disponibilité
Basculement automatique, haute disponibilité ;
prend en charge la séparation en lecture-écriture, prend en charge le mode MySQL double maître et plusieurs esclaves, ainsi que le mode un maître et plusieurs esclaves ; prend en charge les tables globales, les données sont automatiquement partagées sur plusieurs nœuds pour des requêtes de corrélation de tables efficaces
prend en charge une stratégie de partitionnement unique basée sur les relations E-R, réalisant des requêtes de corrélation de tables efficaces
Support multiplateforme, déploiement et mise en œuvre simples.
-------------------------------------- --- -----------------------L'architecture de MyCAT
---------------- -- ------------------------------------------------ --
Il est généralement divisé en trois parties. Le front-end est le connecteur. La gestion des threads utilise les pools de ressources et utilise AIO par défaut (ces informations de base sont visibles). dans le journal de démarrage) ; Avec la présence de
SQL Executor, cela ressemble plus à un SQL
Les éléments de processus, DataNode et la détection du rythme cardiaque sont deux composants implémentés par la couche intermédiaire 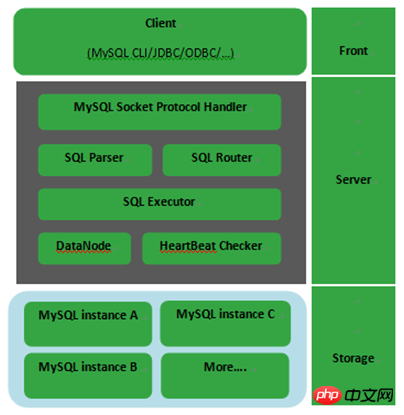
L'un est lié à la bibliothèque MySQL (notez, pas l'instance
), et l'autre est une surveillance commune. mécanisme.Module de fonction ; Le niveau de stockage le plus bas est le cluster de MySQL~ Comment utiliser le cluster MySQL dépend de nous╰(?? ▽ ??)╯ .
MyCAT utilise actuellement des fichiers de configuration Méthode pour définir les bibliothèques logiques et les configurations associées, comprenant principalement trois fichiers :
MYCAT_HOME/conf/schema.xml définit les bibliothèques logiques, les tables, les nœuds de partition, etc. ;
Définissez les règles de partitionnement dans MYCAT_HOME/conf/rule.xml ; définissez les variables liées à l'utilisateur et au système, telles que les ports, etc., dans MYCAT_HOME/conf/server.xml .
Ne vous inquiétez pas, cet article présentera brièvement les fonctions de ces fichiers de configuration et la signification de certains paramètres.
Allons-y un par un, regardons d'abord
schema.xml, qui est un exemple de modèle extrait d'Internet
", L'effet de cette configuration est que lorsque le client MySQL se connecte à MyCAT, via la commande Show DATABASE, vous pouvez voir le nom de la base de données, <?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<schema name="weixin" checkSQLschema="false" sqlMaxLimit="100" dataNode="weixin" >
<schema name="yixin" checkSQLschema="false" sqlMaxLimit="100" dataNode="yixin" />
<dataNode name="dn1" dataHost="localhost0" database="weixin" />
<dataNode name="dn2" dataHost="localhost0" database="yixin" />
<dataHost name="localhost0" maxCon="450" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456" />
<readHost host="hostS1" url="localhost:3307" user="test" password="123456" />
</dataHost>
</mycat:schema>
Remarque : La base de données affichée par MyCAT à l'extrémité externe et les tables de la base de données sont toutes configurées dans le schéma. Il n'y a aucune table ou bibliothèque écrite dans celui-ci, même si elles existent à l'arrière. -fin MySQL, ils ne peuvent pas accéder via MyCAT, mais MyCAT ne définira pas la structure de la table spécifique.
Vient ensuite le datanode. Cet attribut spécifie la table de schéma et la base de données dans laquelle il est stocké. Par exemple, dans cette configuration, le nœud de données de dn1 est spécifié pour être situé sur localhost0, et le le nom de cette instance de base de données est la base de données weixin, il en va de même pour dn2.
datahost répertorie les informations spécifiques du cluster MySQL back-end réel. writehost est l'instance MySQL responsable de l'écriture des données, et writehost est l'instance MySQL responsable de la lecture des informations spécifiques des deux. les instances sont écrites de la même manière, ce qui signifie que le backend utilise une seule instance. S'il est configuré comme des instances différentes, configurez la synchronisation maître-esclave entre les deux instances, puis utilisez MyCAT pour obtenir une séparation en lecture-écriture
vers la base de données La segmentation verticale se fait principalement par schema.xml, qui sera présenté en détail plus tard.
rule.xml comme exemple
D'autres stratégies de segmentation seront présentées en détail ultérieurement<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://org.opencloudb/">
<tableRule name="rule">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<function name="func1" class="org.opencloudb.route.function.PartitionByLong">
<property name="partitionCount">2</property>
<property name="partitionLength">512</property>
</function>
</mycat:rule>
server.xml à titre d'exemple
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/">
<system>
<property name="sequnceHandlerType">0</property>
</system>
<user name="test">
<property name="password">test</property>
<property name="schemas">weixin,yixin</property>
</user>
</mycat:server>
server.xml里面配置MyCAT的逻辑库参数,如示例,配置的就是逻辑库weixin和yixin的登录用户名和密码
这个XML里面其实还有一些有关于MyCAT性能调整的参数,不过略去了,东西太多,以后再详细介绍
----------------------------------------------------------------------华丽的分割线-------------------------------------------------------------
简单的MyCAT搭建大致上就包括这些内容,现在讲讲使用一段时间以后,对MyCAT的一些总结;
1.MyCAT的性能表现还是不错的,这几天一直对MyCAT的各方面进行测试,发现MyCAT作为一个代理,虽然是在JAVA虚拟机上面运行,但是面对接近9K的QPS的峰值的时候,本身并没有出现无响应或者丢失连接的问题;
2.MyCAT对前端显示的所有的库,表,全部由schema来配置,但是本身不定义表结构,这使得后端的表结构如果出现不一致,MyCAT前端是察觉不到的,不太方便吧;
3.第二点的不方便,也反映了一点,没有配置到schema的表,完全无法通过MyCAT去操作,这也算是安全性良好的一个表现吧;
4.之前说SQL Executor没感觉到,也是因为在一些测试中,发现MyCAT更像一个提供转发和结果合并功能的代理,只是对SQL和结果进行了process,不过这个需要去看源代码才知晓细节了。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1209
24
52
1209
24

 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
