
 base de données
tutoriel mysql
Explication détaillée du code de schéma du cluster distribué MySQL MyCAT (2)
base de données
tutoriel mysql
Explication détaillée du code de schéma du cluster distribué MySQL MyCAT (2)
Explication détaillée du code de schéma du cluster distribué MySQL MyCAT (2)

Dans la première partie, il y a une brève introduction à la situation de base des fichiers de construction et de configuration MyCAT. Cet article détaille certains paramètres spécifiques du schéma et sa fonction réelle
Post. en premier Dans le fichier de schéma pour mes propres tests, la barre oblique inverse avant le guillemet double ne sera pas éliminée. Faisons comme si elle n'existait pas...
<?xml version=\"1.0\"?>
<!DOCTYPE mycat:schema SYSTEM \"schema.dtd\">
<mycat:schema xmlns:mycat=\"http://org.opencloudb/\">
<schema name=\"mycat\" checkSQLschema=\"false\" sqlMaxLimit=\"100\">
<!-- auto sharding by id (long) -->
<table name=\"students\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule1\" />
<table name=\"log_test\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule2\" />
<!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<!--<table name=\"company\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3\" />
<table name=\"goods\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2\" />
-->
<table name=\"item_test\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3,dn4\" />
<!-- random sharding using mod sharind rule -->
<!-- <table name=\"hotnews\" primaryKey=\"ID\" dataNode=\"dn1,dn2,dn3\"
rule=\"mod-long\" /> -->
<!--
<table name=\"worker\" primaryKey=\"ID\" dataNode=\"jdbc_dn1,jdbc_dn2,jdbc_dn3\" rule=\"mod-long\" />
-->
<!-- <table name=\"employee\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\" />
<table name=\"customer\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\">
<childTable name=\"orders\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\">
<childTable name=\"order_items\" joinKey=\"order_id\"
parentKey=\"id\" />
<ildTable>
<childTable name=\"customer_addr\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\" /> -->
</schema>
<!-- <dataNode name=\"dn\" dataHost=\"localhost\" database=\"test\" /> -->
<dataNode name=\"dn1\" dataHost=\"localhost\" database=\"test1\" />
<dataNode name=\"dn2\" dataHost=\"localhost\" database=\"test2\" />
<dataNode name=\"dn3\" dataHost=\"localhost\" database=\"test3\" />
<dataNode name=\"dn4\" dataHost=\"localhost\" database=\"test4\" />
<!--
<dataNode name=\"jdbc_dn1\" dataHost=\"jdbchost\" database=\"db1\" />
<dataNode name=\"jdbc_dn2\" dataHost=\"jdbchost\" database=\"db2\" />
<dataNode name=\"jdbc_dn3\" dataHost=\"jdbchost\" database=\"db3\" />
-->
<dataHost name=\"localhost\" maxCon=\"100\" minCon=\"10\" balance=\"1\"
writeType=\"1\" dbType=\"mysql\" dbDriver=\"native\">
<heartbeat>select user()<beat>
<!-- can have multi write hosts -->
<writeHost host=\"localhost\" url=\"localhost:3306\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS1\" url=\"localhost:3307\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
<writeHost host=\"localhost1\" url=\"localhost:3308\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS11\" url=\"localhost:3309\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
</dataHost>
<!-- <writeHost host=\"hostM2\" url=\"localhost:3316\" user=\"root\" password=\"123456\"/> -->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"1\" balance=\"0\" writeType=\"0\" dbType=\"mongodb\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM\" url=\"mongodb://192.168.0.99/test\" user=\"admin\" password=\"123456\" ></writeHost>
</dataHost>
-->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"10\" balance=\"0\"
dbType=\"mysql\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM1\" url=\"jdbc:mysql://localhost:3306\"
user=\"root\" password=\"123456\">
</writeHost>
</dataHost>
-->
</mycat:schema>- .
Première ligne de paramètres<nom du schéma ="mycat" checkSQLschema="false" sqlMaxLimit= "100"/>
Dans cette ligne de paramètres, le nom du schéma définit le nom de la base de données logique qui peut être affiché sur le front-end de MyCAT ,
Lorsque le paramètre checkSQLschema est False, cela indique que MyCAT ignorera automatiquement le nom de la base de données avant le nom de la table. , mydatabase1.test1 sera considéré comme test1;
sqlMaxLimit spécifie la limite du nombre de lignes renvoyées par l'instruction SQL;
🎜>
À titre de capture d'écran, cette limite permettra à mycat d'ajouter automatiquement une LIMIT lors de la distribution de l'instruction SQL, limit Comme vous pouvez le voir dans le coin supérieur droit, MyCAT lui-même est mis en cache
; Donc, si l'instruction que nous exécutons renvoie plus de lignes de données, que fera MyCAT sans modifier cette limite ? >, Ainsi, si une grande quantité de données doit être renvoyée dans l'application réelle, vous devrez peut-être le faire manuellement changer la logique
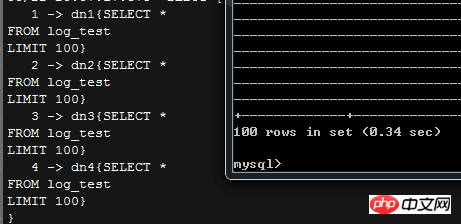 Dans la version 1.4 de mycat, le paramètre Limit de l'utilisateur couvrira le paramètre MyCAT par défaut
Dans la version 1.4 de mycat, le paramètre Limit de l'utilisateur couvrira le paramètre MyCAT par défaut
> ----- ------------------------------------------------ ------- ------------------------------------------------ ------- ------------------------------------------------ ------- --------------------------- >tableau
nom
="étudiants" dataNode
=
"dn1,dn2,dn3,dn4" règle="rule1" /> Cette ligne représente laquelle les noms de table seront affichés sur le front-end de MyCAT ? Les lignes similaires signifient toutes la même chose. L'accent est mis ici sur la table, et MyCAT ne définit pas la structure de la table dans le fichier de configuration Si vous utilisez show create table sur. le front-end, MyCAT affichera normalement les informations sur la structure de la table, observez le journal de débogage, On peut voir que MyCAT distribue la commande à la base de données représentée par dn1, puis renvoie le résultat de la requête de dn1 au front-end
On peut juger que certaines instructions de requête similaires au niveau de la base de données peuvent être distribuées à un certain nœud séparément.Renvoyez ensuite les informations d'un certain nœud au front-end;dents Stratégie de segmentation spécifique, actuellement MyCAT ne prend en charge que la segmentation selon une colonne spéciale et en suivant certaines règles spéciales, telles que modulo, énumération, etc. plus tard
---------- -------------------------------------- ------------ -------------------------------------- ------------ -------------------------------------- ------------ ----------
nom
=
"item_test" clé primaire="ID" type ="global" dataNode="dn1,dn2,dn3,dn4" /> Cette ligne représente la table globale, ce qui signifie que la table item_test aura des copies complètes des données dans les quatre dataNodes, puis sera-t-elle distribuée à toutes les bases de données lors de la requête ? La requête de la table ne sera distribuée qu'à un certain nœud La clé primaire configurée n'est pas utilisée, alors ignorez-la pour l'instant, je l'ajouterai si je la trouve plus tard ---------- ------------------------------------------ ------------- ----------------------------------------- ------------- ----------------------------------------- ------------- -------------Je n'ai pas réellement utilisé childtable dans le test, mais il a été mentionné dans le document de conception de MyCAT que childtable est une structure qui dépend de la table parent
Cela signifie que la clé de jointure de childtable suivra la stratégie parentKey de la. table parent. Divisez-les ensemble. Lorsque la table parent est connectée à la table enfant et que la condition de connexion est childtable.joinKey=parenttable.parentKey, la connexion entre bases de données ne sera pas effectuée. --------------------------------------------- ---------- --------------------------------------------- ---------- --------------------------------------------- ---------- -------------
Les paramètres de dataNode ont été introduits dans le chapitre précédent, alors passez ici~
--------- ----------------------------------------- --------- ----------------------------------------- --------- ----------------------------------------- --------- -----------------
dataHost configure le cluster de base de données back-end réel. La plupart des paramètres sont simples et faciles à comprendre. Voici ce que je ne présenterai pas. les un par un. Je ne présenterai que les deux paramètres les plus importants, writeType et balance. Configuration du cluster à partir de
Le processus de test ici est plus compliqué, je publierai donc la conclusion directement :
)
2. Lorsque balance=1, les opérations de lecture seront dispersées de manière aléatoire sur localhost1 et deux hôtes de lecture (lorsque localhost échoue, les opérations d'écriture seront sur
localhost1, si
Si localhost1 échoue à nouveau, les opérations d'écriture ne seront pas possibles
) 3. Lorsque balance=2, les opérations d'écriture seront sur localhost et les opérations de lecture seront dispersées aléatoirement sur LocalHost1, LocalHost1 et deux Readhost (les mêmes ci-dessus)
4.writeType = 0, les opérations d'écriture seront sur LocalHost Passer à localhost1 Après. localhost est restauré, il ne reviendra pas à localhost pour les opérations d'écriture Sur
localhost et localhost1, le point de défaillance unique n'affectera pas l'opération d'écriture du cluster. Cependant, la bibliothèque esclave back-end ne pourra pas obtenir les mises à jour de la bibliothèque principale défaillante et échouera en cas d'incohérence de lecture des données
. , mais la bibliothèque esclave de localhost ne peut pas obtenir de mises à jour de localhost. cohérence avec d'autres bibliothèques -------- ----- --------------------------------------------- ----- --------------------------------------------- ----- --------------------------------------------- ----- -------------En fait, La séparation en lecture et en écriture de MyCAT elle-même est basée sur la synchronisation du cluster back-end, et MyCAT elle-même fournit des fonctions de distribution d'instructions. La restriction sqlLimit amène également MyCAT à avoir un certain impact sur la logique de la couche d'application frontale
La configuration du schéma à la table montre que la structure logique de MyCAT elle-même inclut la fonctionnalité de sous-base de données et de sous-table (peut Spécifiez que différentes tables existent dans différentes bases de données sans avoir à les diviser dans toutes les bases de données)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
La construction d'une base de données SQL comprend 10 étapes: sélectionner des SGBD; Installation de SGBD; créer une base de données; créer une table; insérer des données; récupération de données; Mise à jour des données; supprimer des données; gérer les utilisateurs; sauvegarde de la base de données.
