

Introduction détaillée et analyse du modèle d'exception Java (photo)

1. Introduction et bases des exceptions
Le moment idéal pour trouver les erreurs est pendant la phase de compilation, c'est-à-dire avant d'essayer d'exécuter le programme. Cependant, le compilateur ne peut pas trouver toutes les erreurs lors de la compilation. Les erreurs restantes ne peuvent être découvertes et résolues que pendant l'exécution. Ce type d'erreur est Throwable. Cela nécessite que la source de l'erreur transmette les informations appropriées à un récepteur d'une manière ou d'une autre, et le récepteur saura comment gérer le problème correctement. Il s'agit du Rapport d'erreurMécanisme—— Mécanisme anormal. . Ce mécanisme permet au programme de séparer le code pour ce qu'il faut faire pendant l'exécution normale du code pour quoi faire si quelque chose ne va pas.
En termes de gestion des exceptions, Java utilise le modèle termination. Dans ce modèle, on supposera que l'erreur est si critique que le programme ne peut pas revenir au point où l'exception s'est produite pour poursuivre l'exécution. Une fois qu'une exception est levée, cela indique que l'erreur est irréversible et que l'exécution ne peut pas être poursuivie. Par rapport au modèle de terminaison, un autre modèle de gestion des exceptions est le modèle de récupération , qui permet au programme de continuer à s'exécuter une fois l'exception traitée. Bien que ce modèle soit attrayant, il n'est pas très pratique, principalement à cause du couplage qu'il provoque : le gestionnaire de récupération a besoin de savoir où l'exception a été levée, qui contient nécessairement du code non générique qui dépend de l'emplacement de lancement, augmentant ainsi considérablement la difficulté d’écriture et de maintenance du code.
Dans une situation d'exception, le lancement d'une exception s'accompagne des trois choses suivantes :
Tout d'abord, la même chose que les autres objets en Java Comme pour la création, l'objet d'exception sera créé sur le tas en utilisant new
Deuxièmement ; , Le chemin d'exécution actuel est terminé et la référence à l'objet d'exception est extraite de l'environnement actuel
- Enfin,
Le mécanisme de gestion des exceptions prend en charge le programme et commence à rechercher le gestionnaire d'exceptions correspondant et récupère le programme de l'erreur état .
2. Exceptions standard Java1.
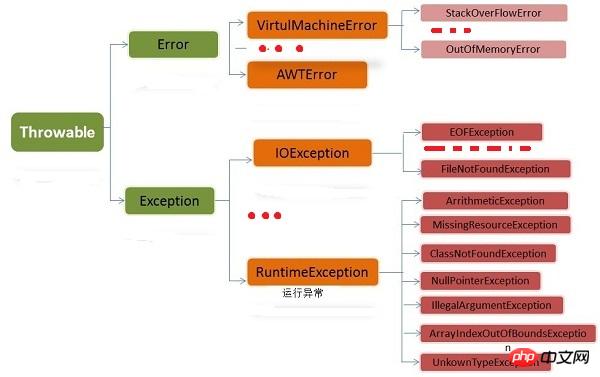
Exemple de hiérarchie de classes d'exception
-
Throwable : La classe racine de tous les types d'exceptions
Throwable est la classe racine de tous les types d'exceptions. Throwable a deux sous-classes directes : Exception et Erreur. Les deux sont des sous-classes importantes de la gestion des exceptions Java et chacune contient un grand nombre de sous-classes.
-
Erreur : une erreur qui ne peut pas être gérée par le programme lui-même
Une erreur est une erreur qui ne peut pas être gérée par le programme, indiquant un problème sérieux lors de l'exécution du application. La plupart de ces erreurs n'ont rien à voir avec les opérations effectuées par le rédacteur de code, mais sont liées à la JVM, aux ressources, etc. lorsque le code est en cours d'exécution. Par exemple, Java Virtual Machine Runtime Error (Virtual MachineError), une OutOfMemoryError se produira lorsque la JVM ne dispose plus des ressources mémoire nécessaires pour continuer à exécuter l'opération. Lorsque ces exceptions se produisent, la machine virtuelle Java (JVM) choisit généralement de mettre fin au thread. Ces erreurs sont incontrôlables et échappent aux capacités de contrôle et de traitement de l'application. En Java, les erreurs sont décrites par des sous-classes d'Erreur.
-
Exception : Erreur que le programme lui-même peut gérer
L'exception préoccupe généralement les programmeurs Java. Elle peut être générée dans la bibliothèque de classes Java, les méthodes utilisateur et les échecs d'exécution. Il se compose de deux branches : exceptions d'exécution (exceptions dérivées de RuntimeException) et autres exceptions . Les règles pour diviser ces deux exceptions sont : causées par des erreurs de programme (généralement des erreurs logiques, telles qu'une conversion de type incorrecte, un tableau hors limites, etc., ce qui devrait être évité) L'exception appartient à RuntimeException ; le programme lui-même n'a aucun problème, mais l'exception provoquée par des erreurs telles que des E/S (par exemple : essayer d'ouvrir un fichier inexistant) appartient à d'autres exceptions.
De plus, les exceptions Java (y compris les exceptions et les erreurs) peuvent généralement être divisées en
exceptions vérifiées (exceptions vérifiées) Là Il existe deux types : et exceptions non cochées .
-
Exceptions non vérifiées : toutes les exceptions dérivées d'une erreur ou d'une RuntimeException
Les exceptions non vérifiées ne sont pas détectées par le compilateur. Les exceptions qui nécessitent une gestion obligatoire incluent les exceptions d'exécution (RuntimeException et ses sous-classes) et les erreurs (Error). C'est-à-dire que lorsqu'une telle exception peut se produire dans le programme, même si elle n'est pas interceptée avec une instruction try-catch ou déclarée comme étant levée à l'aide d'une clause throws, le compilateur la passera.
-
Exceptions vérifiées : toutes les exceptions, à l'exception des exceptions non vérifiées
Les exceptions vérifiées sont requises par le compilateur. Exception gérée. Il existe deux méthodes de traitement ici : détecter et gérer les exceptions et déclarer lancer des exceptions . C'est-à-dire que lorsqu'une telle exception peut se produire dans le programme, utilisez soit une instruction try-catch pour l'attraper, soit une clause throws pour déclarer qu'elle est levée, sinon la compilation ne réussira pas.
Ligne directrice : Si une RuntimeException se produit dans le programme, cela doit être le problème du programmeur
La différence entre les exceptions et les erreurs : Les exceptions peuvent être gérées par le programme lui-même, mais les erreurs ne peuvent pas être gérées
3. Mécanisme de gestion des exceptions Java
- Gestion des exceptions Dans les applications Java, le mécanisme de gestion des exceptions est :
Lancer une exception et Attraper les exceptions.
Lève une exception : Lorsqu'une erreur se produit dans une méthode et qu'une exception est levée, la méthode crée un objet d'exception et le transmet au système d'exécution. L'objet d'exception contient le type d'exception. et l'état du programme lorsque l'exception se produit, etc. Informations sur l'exception. Le système d'exécution est chargé de trouver le code permettant de gérer l'exception et de l'exécuter.Capturer les exceptions : Une fois que la méthode a généré une exception, le système d'exécution se tournera pour trouver un gestionnaire d'exceptions approprié (exception handler). Un gestionnaire d'exceptions potentiel est un ensemble de méthodes qui restent dans la pile d'appels en séquence lorsqu'une exception se produit. Lorsque le type d'exception que le gestionnaire d'exceptions peut gérer correspond au type d'exception émis par la méthode, il s'agit d'un gestionnaire d'exceptions approprié. Le système d'exécution démarre à partir de la méthode où l'exception s'est produite et vérifie les méthodes dans la pile d'appels jusqu'à ce qu'il trouve la méthode contenant le gestionnaire d'exception approprié et l'exécute. Lorsque le système d'exécution parcourt la pile d'appels sans trouver de gestionnaire d'exceptions approprié, le système d'exécution se termine. En même temps, cela signifie la fin du programme Java.
Pour les exceptions d'exécution, les erreurs ou les exceptions vérifiées, les méthodes de gestion des exceptions requises par la technologie Java sont différentes :
- Puisque
les exceptions d'exécution ne sont pas cochées, Java stipule : les exceptions d'exécution seront automatiquement levées par le système d'exécution Java, permettant aux applications d'ignorer l'exception d'exécution
; - Pour l'erreur
pouvant survenir lors de l'exécution de la méthode , lorsque la méthode en cours d'exécution ne veut pas l'attraper, Java permet à la méthode de ne rien faire en lançant une instruction . Parce que la plupart des erreurs sont irrécupérables et constituent des exceptions que les applications raisonnables ne devraient pas détecter
- Pour
toutes les exceptions vérifiées, Java stipule que les exceptions doivent être attrapé ou expliqué. Autrement dit, lorsqu'une méthode choisit de ne pas intercepter les exceptions vérifiables, elle doit déclarer qu'elle lancera une exception ;
Tout code Java peut générer des exceptions, comme du code écrit par vous-même, du code du package de l'environnement de développement Java ou du système d'exécution Java. N'importe qui peut lever une exception via l'instruction throw de Java.
En général, Java stipule que les exceptions vérifiables doivent être interceptées ou déclarées comme étant levées. Permet d'ignorer les RuntimeException et les erreurs non vérifiables.
2. Description de l'exception
Pour les exceptions vérifiées , Java fournit les exceptions correspondantes. syntaxe qui vous permet d'indiquer au programmeur client le type d'exception qu'une certaine méthode peut lever, et le programmeur client peut ensuite le gérer en conséquence. Il s'agit de la description de l'exception , qui fait partie de la déclaration de la méthode, immédiatement après la liste des paramètres formels, comme indiqué dans le code suivant :
void f() throws TooBig, TooSmall, pZero { ... }représente la méthode f peut lever trois exceptions : TooBig, TooSmall et pZero, tandis que
void g() { ... ... }signifie que la méthode g ne lèvera aucune exception.
Le code doit être cohérent avec la description de l'exception. Si le code de la méthode génère une exception vérifiée mais ne la gère pas, le compilateur découvrira ce problème et vous rappellera : Soit gérer l'exception, soit indiquer dans la description de l'exception que cette méthode générera une exception . Cependant, nous pouvons déclarer qu'une méthode lancera une exception sans la lancer réellement.
3. Capturer les exceptions
Zone de surveillance : C'est un morceau de code qui peut générer des exceptions, et est suivi d'un code pour les gérer. les exceptions, comme indiqué dans la clause try…catch… sont implémentées.
(1) clause try
Si une exception est levée à l'intérieur de la méthode, cette méthode se terminera par le processus de levée de l'exception. Si vous ne souhaitez pas que la méthode se termine ici, vous pouvez définir un bloc spécial dans la méthode pour intercepter l'exception. Parmi eux, dans ce bloc, la partie qui tente d'appeler diverses méthodes est appelée le bloc try :
try {
// Code that might generate exceptions } (2) clause catch – gestionnaire d'exceptions
L'exception levée doit être interceptée Gestion, et pour chaque exception à intercepter, un gestionnaire d'exception correspondant doit être préparé. Le gestionnaire d'exceptions doit suivre le bloc try , représenté par le mot-clé catch :
try {
// Code that might generate exceptions } catch(Type1 id1)|{
// Handle exceptions of Type1 } catch(Type2 id2) {
// Handle exceptions of Type2 } catch(Type3 id3) {
// Handle exceptions of Type3 } Le gestionnaire d'exceptions ne peut pas utiliser l'identifiant (id1, id2,. ..), car le type d'exception lui-même a fourni suffisamment d'informations pour gérer l'exception, mais l'identifiant ne peut pas être omis. Lorsqu'une exception est levée, le mécanisme de gestion des exceptions sera chargé de rechercher le premier gestionnaire dont les paramètres correspondent au type d'exception. Saisissez ensuite le catch correspondant et exécutez-le automatiquement. A ce moment, l'exception est considérée comme gérée. Une fois la clause catch terminée, la recherche du gestionnaire se termine (contrairement à switch…case…).
Une attention particulière doit être portée à :
Principe de correspondance des exceptions : Lorsqu'une exception est levée, gestion des exceptions Le système trouvera le gestionnaire correspondant le plus proche (un objet d'une classe dérivée peut correspondre à un gestionnaire de sa classe de base) dans l'ordre dans lequel le code est écrit. Une fois trouvé, il suppose que l'exception sera gérée et arrête de chercher ; La clause catch doit être placée après la clause catch qui capture les exceptions de sa classe dérivée, sinon la compilation ne réussira pas
la clause catch doit être utilisée avec la clause try ; .
(3) finalclause ly
The finally block always executes when the try block exits. This ensures that the finally block is executed even if an unexpected exception occurs. But finally is useful for more than just exception handling — it allows the programmer to avoid having cleanup code accidentally bypassed by a return,continue, or break. Putting cleanup code in a finally block is always a good practice, even when no exceptions are anticipated.
Note: If the JVM exits while the try or catch code is being executed, then the finally block may not execute. Likewise, if the thread executing the try or catch code is interrupted or killed, the finally block may not execute even though the application as a whole continues.
finally 子句 总会被执行(前提:对应的 try子句 执行)
下面代码就没有执行 finally 子句:
public class Test {
public static void main(String[] args) {
System.out.println("return value of test(): " + test());
}
public static int test() {
int i = 1;
System.out.println("the previous statement of try block");
i = i / 0;
try {
System.out.println("try block");
return i;
}finally {
System.out.println("finally block");
}
}
}/* Output:
the previous statement of try block
Exception in thread "main" java.lang.ArithmeticException: / by zero
at com.bj.charlie.Test.test(Test.java:15)
at com.bj.charlie.Test.main(Test.java:6)
*///:~当代码抛出一个异常时,就会终止方法中剩余代码的执行,同时退出该方法的执行。如果该方法获得了一些本地资源,并且这些资源(eg:已经打开的文件或者网络连接等)在退出方法之前必须被回收,那么就会产生资源回收问题。这时,就会用到finally子句,示例如下:
InputStream in = new FileInputStream(...);try{
...
}catch (IOException e){
...
}finally{
in.close();
}finally 子句与控制转移语句的执行顺序
A finally clause can also be used to clean up for break, continue and return, which is one reason you will sometimes see a try clause with no catch clauses. When any control transfer statement is executed, all relevant finally clauses are executed. There is no way to leave a try block without executing its finally clause.
先看四段代码:
// 代码片段1
public class Test {
public static void main(String[] args) {
try {
System.out.println("try block");
return ;
} finally {
System.out.println("finally block");
}
}
}/* Output:
try block
finally block
*///:~// 代码片段2public class Test {
public static void main(String[] args) {
System.out.println("reture value of test() : " + test());
}
public static int test(){
int i = 1;
try {
System.out.println("try block");
i = 1 / 0;
return 1;
}catch (Exception e){
System.out.println("exception block");
return 2;
}finally {
System.out.println("finally block");
}
}
}/* Output:
try block
exception block
finally block
reture value of test() : 2
*///:~// 代码片段3public class ExceptionSilencer {
public static void main(String[] args) {
try {
throw new RuntimeException();
} finally {
// Using ‘return’ inside the finally block
// will silence any thrown exception.
return;
}
}
} ///:~// 代码片段4class VeryImportantException extends Exception {
public String toString() {return "A very important exception!"; }
}
class HoHumException extends Exception {
public String toString() {
return "A trivial exception";
}
}
public class LostMessage {
void f() throws VeryImportantException {
throw new VeryImportantException();
}
void dispose() throws HoHumException {
throw new HoHumException();
}
public static void main(String[] args) {
try {
LostMessage lm = new LostMessage();
try {
lm.f();
} finally {
lm.dispose();
}
} catch(Exception e) {
System.out.println(e);
}
}
} /* Output:
A trivial exception
*///:~从上面的四个代码片段,我们可以看出,finally子句 是在 try 或者 catch 中的 return 语句之前执行的。更加一般的说法是,finally子句 应该是在控制转移语句之前执行,控制转移语句除了 return 外,还有 break 和 continue。另外,throw 语句也属于控制转移语句。虽然 return、throw、break 和 continue 都是控制转移语句,但是它们之间是有区别的。其中 return 和 throw 把程序控制权转交给它们的调用者(invoker),而 break 和 continue 的控制权是在当前方法内转移。
下面,再看两个代码片段:
// 代码片段5public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
try {
return 0;
} finally {
return 1;
}
}
}/* Output:
return value of getValue(): 1
*///:~// 代码片段6public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
int i = 1;
try {
return i;
} finally {
i++;
}
}
}/* Output:
return value of getValue(): 1
*///:~ 利用我们上面分析得出的结论:finally子句 是在 try子句 或者 catch子句 中的 return 语句之前执行的。 由此,可以轻松的理解代码片段 5 的执行结果是 1。因为 finally 中的 return 1;语句要在 try 中的 return 0;语句之前执行,那么 finally 中的 return 1;语句执行后,把程序的控制权转交给了它的调用者 main()函数,并且返回值为 1。
那为什么代码片段 6 的返回值不是 2,而是 1 呢? 按照代码片段 5 的分析逻辑,finally 中的 i++;语句应该在 try 中的 return i;之前执行啊? i 的初始值为 1,那么执行 i++;之后为 2,再执行 return i;那不就应该是 2 吗?怎么变成 1 了呢?
关于 Java 虚拟机是如何编译 finally 子句的问题,有兴趣的读者可以参考《 The JavaTM Virtual Machine Specification, Second Edition 》中 7.13 节 Compiling finally。那里详细介绍了 Java 虚拟机是如何编译 finally 子句。实际上,Java 虚拟机会把 finally 子句作为 subroutine 直接插入到 try 子句或者 catch 子句的控制转移语句之前。但是,还有另外一个不可忽视的因素,那就是在执行 subroutine(也就是 finally 子句)之前,try 或者 catch 子句会保留其返回值到本地变量表(Local Variable Table)中。待 subroutine 执行完毕之后,再恢复保留的返回值到操作数栈中,然后通过 return 或者 throw 语句将其返回给该方法的调用者(invoker)。
请注意,前文中我们曾经提到过 return、throw 和 break、continue 的区别,对于这条规则(保留返回值),只适用于 return 和 throw 语句,不适用于 break 和 continue 语句,因为它们根本就没有返回值。
下面再看最后三个代码片段:
// 代码片段7public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
@SuppressWarnings("finally")
public static int getValue() {
int i = 1;
try {
i = 4;
} finally {
i++;
return i;
}
}
}/* Output:
return value of getValue(): 5
*///:~// 代码片段8public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
int i = 1;
try {
i = 4;
} finally {
i++;
}
return i;
}
}/* Output:
return value of getValue(): 5
*///:~// 代码片段9public class Test {
public static void main(String[] args) {
System.out.println(test());
}
public static String test() {
try {
System.out.println("try block");
return test1();
} finally {
System.out.println("finally block");
}
}
public static String test1() {
System.out.println("return statement");
return "after return";
}
}/* Output:
try block
return statement
finally block
after return
*///:~请注意,最后个案例的唯一一个需要注意的地方就是,return test1(); 这条语句等同于 :
String tmp = test1(); return tmp;
因而会产生上述输出。
特别需要注意的是,在以下4种特殊情况下,finally子句不会被(完全)执行:
1)在 finally 语句块中发生了异常;
2)在前面的代码中用了 System.exit()【JVM虚拟机停止】退出程序;
3)程序所在的线程死亡;
4)关闭 CPU;
四. 异常的限制
当覆盖方法时,只能抛出在基类方法的异常说明里列出的那些异常。这意味着,当基类使用的代码应用到其派生类对象时,一样能够工作。
class BaseballException extends Exception {}
class Foul extends BaseballException {}
class Strike extends BaseballException {}
abstract class Inning {
public Inning() throws BaseballException {}
public void event() throws BaseballException {
// Doesn’t actually have to throw anything
}
public abstract void atBat() throws Strike, Foul;
public void walk() {} // Throws no checked exceptions }
class StormException extends Exception {}
class RainedOut extends StormException {}
class PopFoul extends Foul {}
interface Storm {
public void event() throws RainedOut;
public void rainHard() throws RainedOut;
}
public class StormyInning extends Inning implements Storm {
// OK to add new exceptions for constructors, but you must deal with the base constructor exceptions:
public StormyInning() throws RainedOut, BaseballException {}
public StormyInning(String s) throws Foul, BaseballException {}
// Regular methods must conform to base class:
void walk() throws PopFoul {} //Compile error
// Interface CANNOT add exceptions to existing methods from the base class:
public void event() throws RainedOut {}
// If the method doesn’t already exist in the base class, the exception is OK:
public void rainHard() throws RainedOut {}
// You can choose to not throw any exceptions, even if the base version does:
public void event() {}
// Overridden methods can throw inherited exceptions:
public void atBat() throws PopFoul {}
public static void main(String[] args) {
try {
StormyInning si = new StormyInning();
si.atBat();
} catch(PopFoul e) {
System.out.println("Pop foul");
} catch(RainedOut e) {
System.out.println("Rained out");
} catch(BaseballException e) {
System.out.println("Generic baseball exception");
}
// Strike not thrown in derived version.
try {
// What happens if you upcast? ----印证“编译器的类型检查是静态的,是针对引用的!!!”
Inning i = new StormyInning();
i.atBat();
// You must catch the exceptions from the base-class version of the method:
} catch(Strike e) {
System.out.println("Strike");
} catch(Foul e) {
System.out.println("Foul");
} catch(RainedOut e) {
System.out.println("Rained out");
} catch(BaseballException e) {
System.out.println("Generic baseball exception");
}
}
} ///:~异常限制对构造器不起作用
子类构造器不必理会基类构造器所抛出的异常。然而,因为基类构造器必须以这样或那样的方式被调用(这里默认构造器将自动被调用),派生类构造器的异常说明必须包含基类构造器的异常说明。
派生类构造器不能捕获基类构造器抛出的异常
因为 super() 必须位于子类构造器的第一行,而若要捕获父类构造器的异常的话,则第一行必须是 try 子句,这样会导致编译不会通过。
派生类所重写的方法抛出的异常列表不能大于父类该方法的异常列表,即前者必须是后者的子集
通过强制派生类遵守基类方法的异常说明,对象的可替换性得到了保证。需要指出的是,派生类方法可以不抛出任何异常,即使基类中对应方法具有异常说明。也就是说,一个出现在基类方法的异常说明中的异常,不一定会出现在派生类方法的异常说明里。
异常说明不是方法签名的一部分
尽管在继承过程中,编译器会对异常说明做强制要求,但异常说明本身并不属于方法类型的一部分,方法类型是由方法的名字及其参数列表组成。因此,不能基于异常说明来重载方法。
五. 自定义异常
使用Java内置的异常类可以描述在编程时出现的大部分异常情况。除此之外,用户还可以自定义异常。用户自定义异常类,只需继承Exception类即可。
在程序中使用自定义异常类,大体可分为以下几个步骤:
(1)创建自定义异常类;
(2)在方法中通过throw关键字抛出异常对象;
(3)如果在当前抛出异常的方法中处理异常,可以使用try-catch语句捕获并处理;否则在方法的声明处通过throws关键字指明要抛出给方法调用者的异常,继续进行下一步操作;
(4)在出现异常方法的调用者中捕获并处理异常。
六. 异常栈与异常链
1、栈轨迹
printStackTrace() 方法可以打印Throwable和Throwable的调用栈轨迹。调用栈显示了由异常抛出点向外扩散的所经过的所有方法,即方法调用序列(main方法 通常是方法调用序列中的最后一个)。
2、重新抛出异常
catch(Exception e) {
System.out.println("An exception was thrown");
throw e;
} 既然已经得到了对当前异常对象的引用,那么我们就可以像上面一样将其重新抛出。重新抛出的异常会把异常抛给上一级环境中的异常处理程序,同一个try子句的后续catch子句将被忽略。此外,如果只是把当前异常对象重新抛出,那么printStackTrace() 方法显示的仍是原来异常抛出点的调用栈信息,而并非重新抛出点的信息。要想更新这个信息,可以调用fillInStackTrace() 方法,这将返回一个Throwable对象,它是通过把当前调用栈信息填入原来那个异常对象而建立的。
看下面示例:
public class Rethrowing {
public static void f() throws Exception {
System.out.println("originating the exception in f()");
throw new Exception("thrown from f()");
}
public static void g() throws Exception {
try {
f();
} catch(Exception e) {
System.out.println("Inside g(),e.printStackTrace()");
e.printStackTrace(System.out);
throw e;
}
}
public static void h() throws Exception { try {
f();
} catch(Exception e) {
System.out.println("Inside h(),e.printStackTrace()");
e.printStackTrace(System.out);
throw (Exception)e.fillInStackTrace();
}
}
public static void main(String[] args) {
try {
g();
} catch(Exception e) {
System.out.println("main: printStackTrace()");
e.printStackTrace(System.out);
}
try {
h();
} catch(Exception e) {
System.out.println("main: printStackTrace()");
e.printStackTrace(System.out);
}
}
} /* Output:
originating the exception in f()
Inside g(),e.printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.g(Rethrowing.java:11)
at Rethrowing.main(Rethrowing.java:29)
main: printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.g(Rethrowing.java:11)
at Rethrowing.main(Rethrowing.java:29)
originating the exception in f()
Inside h(),e.printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.h(Rethrowing.java:20)
at Rethrowing.main(Rethrowing.java:35)
main: printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.h(Rethrowing.java:24)
at Rethrowing.main(Rethrowing.java:35)
*///:~3、异常链
异常链:在捕获一个异常后抛出另一个异常,并且希望把原始异常的信息保存下来。
这可以使用带有cause参数的构造器(在Throwable的子类中,只有Error,Exception和RuntimeException三个类提供了带有cause的构造器)或者使用initcause()方法把原始异常传递给新的异常,使得即使在当前位置创建并抛出了新的异常,也能通过这个异常链追踪到异常最初发生的位置,例如:
class DynamicFieldsException extends Exception {}
...
DynamicFieldsException dfe = new DynamicFieldsException();
dfe.initCause(new NullPointerException());
throw dfe;
...//捕获该异常并打印其调用站轨迹为:/**
DynamicFieldsException
at DynamicFields.setField(DynamicFields.java:64)
at DynamicFields.main(DynamicFields.java:94)
Caused by: java.lang.NullPointerException
at DynamicFields.setField(DynamicFields.java:66)
... 1 more
*/以 RuntimeException 及其子类NullPointerException为例,其源码分别为:
RuntimeException 源码包含四个构造器,有两个可接受cause:
public class RuntimeException extends Exception {
static final long serialVersionUID = -7034897190745766939L;
/** Constructs a new runtime exception with <code>null</code> as its
* detail message. The cause is not initialized, and may subsequently be
* initialized by a call to {@link #initCause}.
*/
public RuntimeException() { super();
} /** Constructs a new runtime exception with the specified detail message.
* The cause is not initialized, and may subsequently be initialized by a
* call to {@link #initCause}.
*
* @param message the detail message. The detail message is saved for
* later retrieval by the {@link #getMessage()} method.
*/
public RuntimeException(String message) { super(message);
} /**
* Constructs a new runtime exception with the specified detail message and
* cause. <p>Note that the detail message associated with
* <code>cause</code> is <i>not</i> automatically incorporated in
* this runtime exception's detail message.
*
* @param message the detail message (which is saved for later retrieval
* by the {@link #getMessage()} method).
* @param cause the cause (which is saved for later retrieval by the
* {@link #getCause()} method). (A <tt>null</tt> value is
* permitted, and indicates that the cause is nonexistent or
* unknown.)
* @since 1.4
*/
public RuntimeException(String message, Throwable cause) { super(message, cause);
} /** Constructs a new runtime exception with the specified cause and a
* detail message of <tt>(cause==null ? null : cause.toString())</tt>
* (which typically contains the class and detail message of
* <tt>cause</tt>). This constructor is useful for runtime exceptions
* that are little more than wrappers for other throwables.
*
* @param cause the cause (which is saved for later retrieval by the
* {@link #getCause()} method). (A <tt>null</tt> value is
* permitted, and indicates that the cause is nonexistent or
* unknown.)
* @since 1.4
*/
public RuntimeException(Throwable cause) { super(cause);
}
}NullPointerException 源码仅包含两个构造器,均不可接受cause:
public class NullPointerException extends RuntimeException {
/**
* Constructs a <code>NullPointerException</code> with no detail message.
*/
public NullPointerException() { super();
} /**
* Constructs a <code>NullPointerException</code> with the specified
* detail message.
*
* @param s the detail message.
*/
public NullPointerException(String s) { super(s);
}
}注意:
所有的标准异常类都有两个构造器:一个是默认构造器;另一个是接受字符串作为异常说明信息的构造器。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
