
 base de données
tutoriel mysql
MySQL - Explication détaillée de la haute disponibilité sur deux machines basée sur Keepalived (image et texte)
base de données
tutoriel mysql
MySQL - Explication détaillée de la haute disponibilité sur deux machines basée sur Keepalived (image et texte)
MySQL - Explication détaillée de la haute disponibilité sur deux machines basée sur Keepalived (image et texte)

1. Description de l'environnement :
OS : CentOS6.5_X64
MAÎTRE : 192.168.0.202
SAUVEGARDE : 192.168.0.203
VIP : 192.168.0.204
2. Configurer deux Mysqlsynchronisation maître-maître
Concernant l'installation de MySQL, vous pouvez également vous référer à "MySQL - CentOS6.5 Compile and Install MySQL5.6.16" , La synchronisation maître principal configure le serveur esclave en tant que maître du serveur maître précédent sur la base de la synchronisation maître-esclave, ce qui équivaut à définir l'esclave d'origine comme maître du maître d'origine en fonction de la synchronisation maître-esclave d'origine. reportez-vous à "MySQL - — Implémentation de la réplication maître-esclave MS (séparation lecture-écriture)"
, après avoir défini A comme maître de B et B comme esclave de A, puis défini B comme maître de A et A comme esclave de B.
[root@masterr ~]# yum install mysql-server mysql -y [root@masterr ~]# service mysqld start [root@masterr ~]# mysqladmin -u root proot [root@masterr ~]# vi /etc/my.cnf #开启二进制日志,设置id [mysqld] server-id = 1 #backup这台设置2 log-bin = mysql-bin binlog-ignore-db = mysql,information_schema #忽略写入binlog日志的库 auto-increment-increment = 2 #字段变化增量值 auto-increment-offset = 1 #初始字段ID为1 slave-skip-errors = all #忽略所有复制产生的错误 [root@masterr ~]# service mysqld restart
# Vérifiez d'abord le journal de la corbeille et l'emplacement de la valeur pos
La configuration principale est la suivante :
[root@ master ~]# mysql -u root -proot
mysql> GRANT REPLICATION SLAVE ON *.* TO 'replication'@'192.168.0.%' IDENTIFIED BY 'replication';
mysql> flush privileges;
mysql> change master to
-> master_host='192.168.0.203',
-> master_user='replication',
-> master_password='replication',
-> master_log_file='mysql-bin.000002',
-> master_log_pos=106; #对端状态显示的值
mysql> start slave; #启动同步La configuration de sauvegarde est la suivante :
[root@backup ~]# mysql -u root -proot
mysql> GRANT REPLICATION SLAVE ON *.* TO 'replication'@'192.168.0.%' IDENTIFIED BY 'replication';
mysql> flush privileges;
mysql> change master to
-> master_host='192.168.0.202',
-> master_user='replication',
-> master_password='replication',
-> master_log_file='mysql-bin.000002',
-> master_log_pos=106;
mysql> start slave;#La configuration de synchronisation maître-maître est terminée Vérifiez l'état de synchronisation Slave_IO et Slave_SQL s'il est OUI, ce qui signifie que le maître-. la synchronisation principale est réussie. 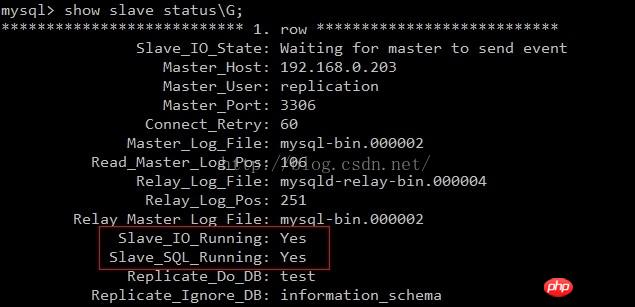
Insérer les données dans le maître En cours de test :
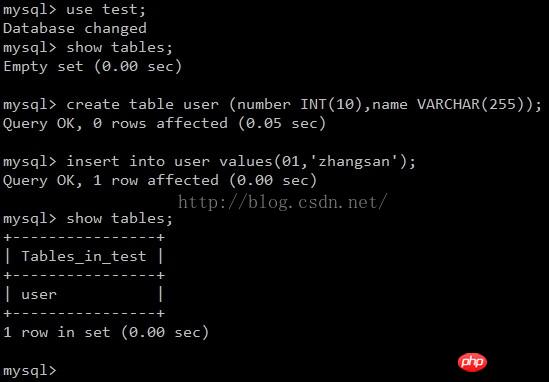
dans Sauvegarde pour vérifier si la synchronisation a réussi :
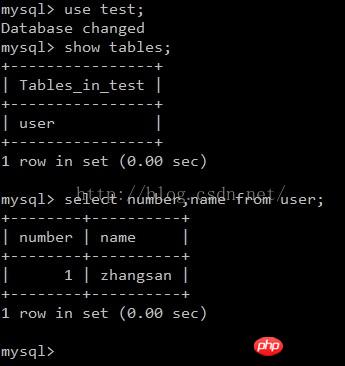
Vous pouvez voir que la synchronisation a réussi. Les données sont également insérées dans la table utilisateur dans. la sauvegarde et synchronisée de la même manière. Double maître Cela a été fait avec succès.
3. Configurez keepalived pour réaliser une sauvegarde à chaud
[root@backup ~]# yum install -y pcre-devel openssl-devel popt-devel #安装依赖包
[root@masterr ~]# wget http://www.php.cn/ [root@masterr ~]# tar zxvf keepalived-1.2.7.tar.gz [root@masterr ~]# cd keepalived-1.2.7 [root@masterr ~]#./configure --prefix=/usr/local/keepalived make
#Configurez keepalived en tant que service système
[root@masterr ~]# cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/ [root@masterr ~]# cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/ [root@masterr ~]# mkdir /etc/keepalived/ [root@masterr ~]# cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/ [root@masterr ~]# cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
[root@masterr ~]# vi /etc/keepalived/keepalived.conf
! Configuration File forkeepalived
global_defs {
notification_email {
test@sina.com
}
notification_email_from admin@test.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MYSQL_HA #标识,双主相同
}
vrrp_instance VI_1 {
state BACKUP #两台都设置BACKUP
interface eth0
virtual_router_id 51 #主备相同
priority 100 #优先级,backup设置90
advert_int 1
nopreempt #不主动抢占资源,只在master这台优先级高的设置,backup不设置
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.204
}
}
virtual_server 192.168.0.204 3306 {
delay_loop 2
#lb_algo rr #LVS算法,用不到,我们就关闭了
#lb_kind DR #LVS模式,如果不关闭,备用服务器不能通过VIP连接主MySQL
persistence_timeout 50 #同一IP的连接60秒内被分配到同一台真实服务器
protocol TCP
real_server 192.168.0.202 3306 { #检测本地mysql,backup也要写检测本地mysql
weight 3
notify_down /usr/local/keepalived/mysql.sh #当mysq服down时,执行此脚本,杀死keepalived实现切换
TCP_CHECK {
connect_timeout 3 #连接超时
nb_get_retry 3 #重试次数
delay_before_retry 3 #重试间隔时间
}
}[root@masterr ~]# vi /usr/local/keepalived/mysql.sh #!/bin/bash pkill keepalived [root@masterr ~]# chmod +x /usr/local/keepalived/mysql.sh [root@masterr ~]# /etc/init.d/keepalived start
#Le serveur de sauvegarde modifie uniquement la priorité à 90, nopreempt n'est pas défini et real_server définit l'adresse IP locale.
#Autorisez deux serveurs Mysql pour autoriser la connexion à distance root pour des tests sur d'autres serveurs !
mysql> grant all on *.* to'root'@'192.168.0.%' identified by 'root'; mysql> flush privileges;
4. Testez la haute disponibilité
1) Connectez-vous via VIP via le client Mysql pour voir si la connexion réussit.
2) Arrêtez le service maître mysql et vérifiez s'il peut y être basculé normalement. Vous pouvez utiliser la commande ip addr pour vérifier sur quel serveur se trouve le VIP. 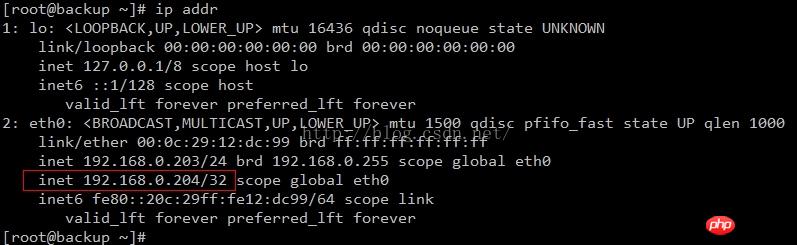
3) Vous pouvez voir le processus de commutation maître/sauvegarde en vérifiant le journal /var/log/messges
4) Une fois le serveur maître récupéré d'une panne, s'il saisit activement les ressources et devient un serveur actif .
Remarque : L'ordre de démarrage du service : démarrez d'abord MySQL, puis Keepalived.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
La récupération des lignes supprimées directement de la base de données est généralement impossible à moins qu'il n'y ait un mécanisme de sauvegarde ou de retour en arrière. Point clé: Rollback de la transaction: Exécutez Rollback avant que la transaction ne s'engage à récupérer les données. Sauvegarde: la sauvegarde régulière de la base de données peut être utilisée pour restaurer rapidement les données. Instantané de la base de données: vous pouvez créer une copie en lecture seule de la base de données et restaurer les données après la suppression des données accidentellement. Utilisez la déclaration de suppression avec prudence: vérifiez soigneusement les conditions pour éviter la suppression accidentelle de données. Utilisez la clause WHERE: Spécifiez explicitement les données à supprimer. Utilisez l'environnement de test: testez avant d'effectuer une opération de suppression.
