

Cette section est principalement destinée à certains types spécifiques de requêtes d'optimisation :
(1) optimisation des requêtes de comptage
(2) Requête associée
(3) Sous-requête
(4) Optimisation GROUP BY et DISTINCT
(5) Optimisation de la pagination LIMIT
Le rôle de la fonction d'agrégation COUNT() :
(1) Compter le nombre de valeurs dans un certain colonne, et vous pouvez également compter le nombre de lignes. Il convient de noter que lors du comptage des valeurs de colonne, la valeur de la colonne doit être non vide (NULL n'est pas compté)
(2) Comptez le nombre de lignes dans l'ensemble de résultats. Lorsque la valeur de la colonne ne peut pas être vide, le nombre de lignes du tableau est compté. Mais pour vous assurer que vous devez utiliser COUNT() pour obtenir le nombre de lignes dans le jeu de résultats. Le caractère générique ignorera directement toutes les valeurs de colonne et calculera directement le nombre de lignes pour l'optimisation.
Pour le moteur de stockage MyISAM, COUNT(*) est très rapide lorsque les conditions de requête Where ne sont pas limitées dans une seule table, car MyISAM lui-même a déjà stocké le nombre total de lignes. Lorsqu'il existe des conditions de qualification, des statistiques de requête sont également requises.
Ce qui suit est un exemple d'optimisation simple :
(1) Optimisation 1 :
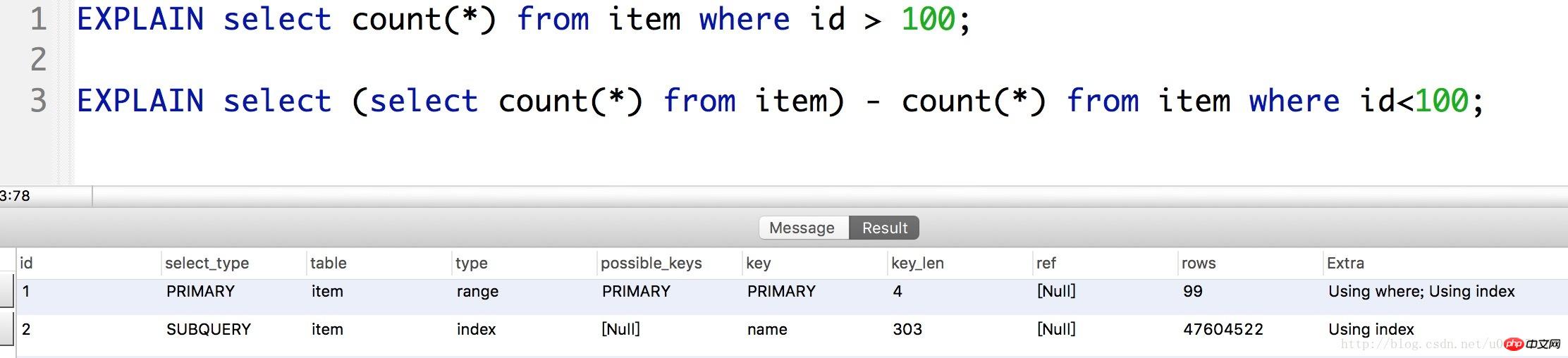
On peut voir que si l'on vérifie directement l'enregistrement de id>100 , impliquant l'analyse de plus de 20 millions de lignes d'enregistrements. Mais grâce à la fonctionnalité COUNT(), nous pouvons utiliser count() - (id
(2) Optimisation 2 :
De plus, une autre méthode d'optimisation consiste à utiliser un index de couverture.
(1) Assurez-vous qu'il y a un index sur la colonne de la clause ON ou USING. Lors de la création d'un index, vous devez considérer l'ordre d'association. Lorsque la table A et la table B sont associées à la colonne c, si l'ordre d'association de l'optimiseur est B, A, il vous suffit de créer un index sur la table A. Les index inutilisés occuperont du stockage
(2) Assurez-vous que l'expression dans toute opération Group by et order by n'implique que les colonnes d'une seule table. De cette façon, il est possible pour MySQL d'utiliser l'optimisation d'index
Utilisez le moins possible les sous-requêtes, car les sous-requêtes généreront des tables temporaires à moins que ; like count(*) La table temporaire est très petite.
Le moyen le plus efficace d'optimiser GROUP BY et DISTINCT est d'utiliser des index.
Lorsque l'index ne peut pas être utilisé, le group by est complété à l'aide de deux stratégies : table temporaire ou tri de fichiers pour le regroupement.
Toutes les colonnes à regrouper doivent être indexées. Par exemple :
select product, count(*) from orders group by product;
Une telle requête doit créer un index pour le produit.
Lors de l'exécution d'opérations de pagination, certaines données sont généralement interrogées via des décalages. Ensuite couplée à l'ordre expliqué par, les performances sont généralement bonnes.
Assurez-vous d'ajouter un index à l'ordre par colonne.
Mais pour la limite 10 000, 10, pour récupérer les 10 enregistrements cibles, vous devez d'abord interroger les 10 000 enregistrements précédents. Le coût est très élevé. Dans ce cas, le moyen le plus simple d’optimiser est d’utiliser un indice de couverture.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



