

Pour les bases de données hautes performances : l'optimisation de la structure des tables de bibliothèque, l'optimisation de l'index et l'optimisation des requêtes doivent aller de pair
Les requêtes sont en fait composées d'une série de sous-tâches. Optimiser les requêtes signifie en fait : soit éliminer certaines sous-tâches, soit réduire le nombre de sous-tâches exécutées.
1) Les données inutiles sont interrogées :
Par exemple, nous interrogeons un grand nombre de résultats via select, et fermons l'ensemble de résultats après avoir obtenu les N premières lignes. En fait, MySQL interrogera tous les résultats. . Set, le client reçoit une partie des données puis supprime les données restantes. Il y a ici une redondance des requêtes. Il nous suffit donc d’interroger les n enregistrements précédents, en utilisant le mot-clé limit limit.
2) Renvoie toutes les colonnes lorsque plusieurs tables sont associées
Lorsque nous effectuons des requêtes multi-tables, nous rencontrons souvent
mysql>select * from …….
Une telle requête est en fait It. Cela affecte beaucoup les performances. Des noms de champs spécifiques doivent être utilisés à la place des caractères génériques *
3) Supprimez toujours toutes les colonnes
et interdisez l'écriture d'instructions telles que select *.
Après avoir confirmé que la requête ne renvoie que les données requises (c'est-à-dire, n'utilisez pas de caractères génériques dans les champs spécifiques du requête personnalisée * )
La prochaine chose à laquelle il faut faire attention est de savoir si les résultats renvoyés ont analysé trop de données. Les trois indicateurs les plus simples pour MySQL sont les suivants :
(1) Temps de réponse
(2) Nombre de lignes analysées
(3) Nombre de lignes renvoyées.
Temps de réponse
Temps de réponse : y compris le temps de service (temps de requête réel) et le temps d'attente (temps d'attente bloquant).
Nombre de lignes analysées et nombre de lignes renvoyées
Lors de l'analyse d'une requête, il est très utile d'afficher le nombre de lignes analysées par la requête, ce qui indique dans une certaine mesure si la requête est efficace ou non.
Nombre de lignes analysées et type d'accès
MySQL dispose de plusieurs méthodes d'accès pour rechercher et renvoyer une ligne de résultats : analyse de table complète, analyse d'index, analyse de plage, requête d'index unique, Références constantes, etc.
Le rôle de l'ajout d'un index apparaît ici. L'index permet à MySQL de trouver des enregistrements de la manière la plus efficace avec le moins de lignes analysées.
Le but est de trouver une manière plus optimale d'obtenir les résultats réels requis.
(1) Une requête complexe ou plusieurs requêtes simples
Une question que nous devons souvent considérer lors de l'écriture de SQL est la suivante : devons-nous diviser une requête complexe en plusieurs requêtes simples ?
Pour MySQL, la connexion et la déconnexion sont très légères et très efficaces pour renvoyer un petit résultat de requête. Bien qu’il soit préférable d’avoir le moins de requêtes possible, il est parfois nécessaire de diviser les requêtes volumineuses en requêtes plus petites après avoir mesuré si la charge de travail est considérablement réduite.
(2) Requête segmentée
L'idée de diviser pour régner. Parfois, nous devons diviser une requête volumineuse en morceaux, les exécuter en plusieurs parties et définir un délai entre les étapes, afin d'éviter de verrouiller beaucoup de données pendant une longue période.
Par exemple, lorsque nous supprimons des données, si nous supprimons toutes les données qui doivent être supprimées en même temps, elles peuvent occuper la transaction pendant une longue période. Cependant, nous pouvons fragmenter et diviser une suppression importante en plusieurs. supprimer les exécutions via des restrictions conditionnelles, ce qui peut améliorer l'efficacité.
(3) Décomposer les requêtes associées
De nombreuses applications hautes performances diviseront les requêtes associées, par exemple :
mysql>select * from tag left join tag_post on tag_post.tag_id=tag.id left join post on tag_post.post_id = post.idwhere tag.tag='mysql';
peut être décomposé en
mysql>select * from tag where tag='mysql';mysql>select * from tag_post where tag_id=1234; mysql>select * from post where post.id in (123,345,456,8933);
Quelle est la raison d’une telle décomposition ?
(1) Rendre le cache plus efficace ; (Par exemple, la balise interrogée ci-dessus a été mise en cache, l'application peut alors ignorer la première requête.)
( 2) Après la rupture en bas de la requête, l'exécution d'une seule requête peut réduire les conflits de verrouillage.
(3) Dans certains cas, l'efficacité sera plus élevée. Par exemple, l'utilisation de la requête par mot-clé in après décomposition ci-dessus est plus efficace.
Tout d'abord, jetons un coup d'œil au diagramme schématique du chemin d'exécution des requêtes : 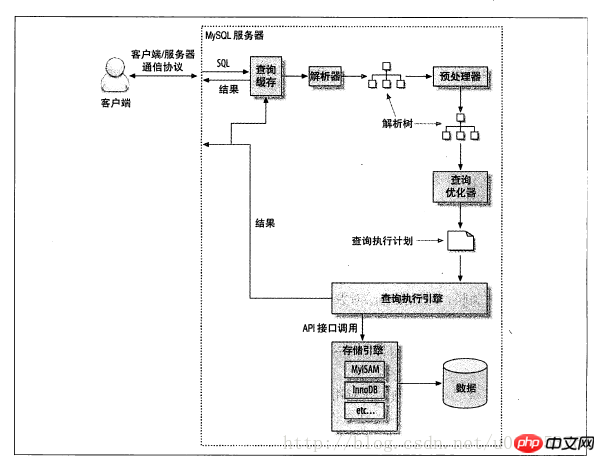
Les étapes sont les suivantes :
(1) Le client envoie une requête au serveur
(2) Le serveur vérifie d'abord le cache des requêtes. Si le cache est atteint, il renvoie immédiatement les résultats stockés. dans le cache, sinon on passe à l'étape suivante.
(3) Le serveur analyse et prétraite le SQL, puis l'optimiseur génère le plan d'exécution correspondant.
(4) MySQL appellera l'API du moteur de stockage pour exécuter la requête en fonction du plan d'exécution généré par l'optimiseur.
(5) Renvoyez le résultat au client.
Nous n'avons pas besoin de comprendre comment le protocole de communication est implémenté en interne, nous avons seulement besoin de comprendre comment la communication le protocole fonctionne.
Le protocole de communication client et serveur de MySQL est semi-duplex, ce qui signifie qu'une seule partie peut envoyer des données à l'autre partie en même temps.
Avant d'analyser une instruction SQL, si le cache est activé, MySQL donnera la priorité à vérifier si la requête atteint les données dans le cache de requêtes. Si le cache est atteint, l'ensemble de résultats sera obtenu directement du cache et renvoyé au client. S'il n'y a aucun résultat dans le cache, il passera à l'étape suivante.
La chose la plus importante dans cette partie est l'optimiseur de requête. Une instruction de requête peut être exécutée de plusieurs manières, et toutes seront renvoyées. au final, avec le même résultat, le rôle de l'optimiseur est de trouver le plan d'exécution le plus efficace.
Voici les types d'optimisation que l'optimiseur de requêtes MySQL peut gérer automatiquement :
(1) Redéfinir l'ordre des tables d'association : L'ordre d'association des tables de données n'est pas toujours dans l'ordre spécifié dans la requête. Ceci est lié à l'optimiseur.(2) Convertir les jointures externes en jointures internes :
(3) Utiliser des règles de transformation équivalentes : vous pouvez réduire certaines comparaisons ou supprimer certaines identités. Par exemple (5=5 et a>5) sera réécrit comme (a> 5).
(4) Optimiser les fonctions COUNT(), MIN() et MAX() : Le fait que les index et les colonnes puissent être vides peut aider à optimiser ce type d'expression : comme trouver la valeur minimale, en utilisant le B -Caractéristiques structurelles de l'arbre, interrogez simplement l'enregistrement le plus à gauche de B-Tree et c'est tout. La même chose est vraie pour trouver la fonction max(). Mais pour la fonction COUNT(*), le type de stockage MyISAM maintient une variable pour stocker spécifiquement le nombre total de lignes d'enregistrement dans la table.
(5) Analyse d'index couverte : lorsque les colonnes de l'index contiennent les colonnes qui doivent être utilisées dans toutes les requêtes, MySQL peut directement utiliser l'index pour renvoyer les données requises sans interroger les lignes de données correspondantes.
(6) Optimisation des sous-requêtes
(8) Terminer la requête plus tôt : MySQL peut toujours mettre fin à la requête immédiatement lorsqu'il constate que les exigences de la requête ont été remplies. Par exemple, limitez le mot clé.
(9) Comparaison de la liste IN au lieu de OR : MySQL triera d'abord les données dans l'instruction IN, puis utilisera la recherche binaire pour déterminer si les données de la liste répondent aux exigences . Il s’agit d’une opération de complexité O(logn). S'il est converti de manière équivalente en OU, il deviendra une complexité temporelle O(n).
Quoi qu'il en soit, le tri est une opération très coûteuse, et il faut éviter de trier le big data. Par conséquent, nous devons utiliser des colonnes d'index pour le tri. Lorsque l'index ne peut pas être utilisé pour générer des résultats de tri, il y aura certainement une situation où la table enregistrements de requête sera renvoyée à ce moment-là. est énorme et le tri des fichiers sera utilisé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



