
 base de données
tutoriel mysql
Explication détaillée du code pour collecter des informations sur les tables tout en surveillant MySQL (images et texte)
base de données
tutoriel mysql
Explication détaillée du code pour collecter des informations sur les tables tout en surveillant MySQL (images et texte)
Explication détaillée du code pour collecter des informations sur les tables tout en surveillant MySQL (images et texte)

1. Histoire
Peut-être qu'on vous pose souvent des questions sur la croissance mensuelle du volume de données d'une certaine table de la bibliothèque au cours de l'année écoulée. Bien sûr, ce serait plus facile si vous divisiez les tables par mois, une par une show table status S'il n'y a qu'une seule grande table, alors vous devrez probablement exécuter des statistiques SQL pendant la nuit solitaire où tout le monde se repose, car vous le pouvez. obtenez uniquement la table actuelle, les informations historiques ne peuvent pas être retracées.
De plus, en tant qu'administrateur de base de données, vous devez également estimer la croissance de l'espace de la base de données pour planifier la capacité. Les informations du tableau dont nous parlons comprennent principalement :
Taille des données du tableau (DATA_LENGTH)
Taille de l'index (INDEX_LENGTH)
Nombre de lignes (ROWS)
Valeur actuelle d'incrémentation automatique (AUTO_INCREMENT, le cas échéant)
Je n'ai Je n'ai pas encore vu lequelmysql fournit de tels indicateurs sur l'outil de surveillance. Il n'est pas nécessaire que ces informations soient collectées trop fréquemment, et le résultat n'est qu'une estimation et peut ne pas être précis. Il s'agit donc de surveiller (collecter) le tableau dans une perspective globale et à long terme.
L'outil de collecte que j'ai écrit pour présenter dans cet article est basé sur le système de suivi existant dans le groupe :
InfluxDB: base de données de séries temporelles, suivi du stockage des donnéesGrafana: Panneau d'affichage des donnéesTelegraf: Agent qui collecte des informations
Découvrez le dernier plug-in MySQL de Telegraf , j'étais très satisfait au début : il prend en charge la collecte de statistiques de schéma de table et de colonnes d'incrémentation automatique de schéma d'informations. Je l'ai essayé et il existe des données, mais comme mentionné précédemment, à l'exception de la valeur auto-augmentante, tout le reste est une estimation, la fréquence de collecte de Telegraf est trop élevée, ce qui n'a aucun sens. Peut-être que deux fois par jour suffisent. 🎜> l'option qu'il propose est corrigée. Morte dans le code, le seul moyen est de ralentir la fréquence de surveillance de l'état global. Cependant, il peut être mis en œuvre en le séparant des autres indicateurs de suivi en deuxIntervalSlowfichiers de configuration et en définissant respectivement les intervalles de collecte.
La mise en œuvre est également très simple, il suffit d'interroger les tables
et information_schema de la bibliothèque COLUMNS : TABLES
SELECT
IFNULL(@@hostname, @@server_id) SERVER_NAME,
%s as HOST,
t.TABLE_SCHEMA,
t.TABLE_NAME,
t.TABLE_ROWS,
t.DATA_LENGTH,
t.INDEX_LENGTH,
t.AUTO_INCREMENT,
c.COLUMN_NAME,
c.DATA_TYPE,
LOCATE('unsigned', c.COLUMN_TYPE) COL_UNSIGNED
# CONCAT(c.DATA_TYPE, IF(LOCATE('unsigned', c.COLUMN_TYPE)=0, '', '_unsigned'))
FROM
information_schema.`TABLES` t
LEFT JOIN information_schema.`COLUMNS` c ON t.TABLE_SCHEMA = c.TABLE_SCHEMA
AND t.TABLE_NAME = c.TABLE_NAME
AND c.EXTRA = 'auto_increment'
WHERE
t.TABLE_SCHEMA NOT IN (
'mysql',
'information_schema',
'performance_schema',
'sys'
)
AND t.TABLE_TYPE = 'BASE TABLE', en plus de prêter attention à l'endroit où se situe la croissance actuelle, nous nous soucions également de la quantité d'espace disponible par rapport à la valeur maximale de auto_increment. La colonne int / bigint a donc été calculée pour enregistrer le ratio actuellement utilisé. autoIncrUsage
- Environnement
Écrit dans l'environnement python 2.7, 2.6 et 3.x n'ont pas été testés.
et MySQLdb deux bibliothèques : influxdb
$ sudo pip install mysql-python influxdb
- Configuration
Fichier de configurationsettings_dbs.py : la liste stocke les informations de la table d'instance MySQL qui doivent être collectées, et les tuples sont les connexions. Adresse, port, nom d'utilisateur, mot de passe
DBLIST_INFOLes utilisateurs ont besoin d'une autorisation pour sélectionner la table, sinon ils ne peuvent pas voir les informations correspondantes.
-
: Informations de connexion Influxdb, veuillez créer le nom de la base de données à l'avance
InfluxDB_INFOmysql_infoet définissez-le sur
Le résultat de sortie peut être json.None - Créez le. base de données et stratégie de stockage sur influxdb
Stockage pendant 2 ans, 1 jeu de répliques : (Ajuster selon les besoins)
- Mettez crontab à exécuter
Il peut être placé séparément sur le serveur utilisé pour la surveillance, mais il est recommandé de l'exécuter sur l'hôte où se trouve l'instance mysql dans l'environnement de production pour des raisons de sécurité.
Dans le cas d'une sous-base de données et d'une table, l'ID unique global ne peut pas être calculé dans la table autoIncrUsage
C'est effectivement très difficile à mettre en œuvre Simple, le plus important est d'éveiller la conscience de la collecte de ces informations
Vous pouvez ajouter le format de sortie Graphite
CREATE DATABASE "mysql_info" CREATE RETENTION POLICY "mysql_info_schema" ON "mysql_info" DURATION 730d REPLICATION 1 DEFAULT
avant et après la migration pour les collecter. Pas recommandé trop souvent. mysql_schema_info.py
40 23,5,12,18 * * * /opt/DBschema_info/mysql_schema_info.py >> /tmp/collect_DBschema_info.log 2>&1
Taille des données du tableau et nombre de lignes
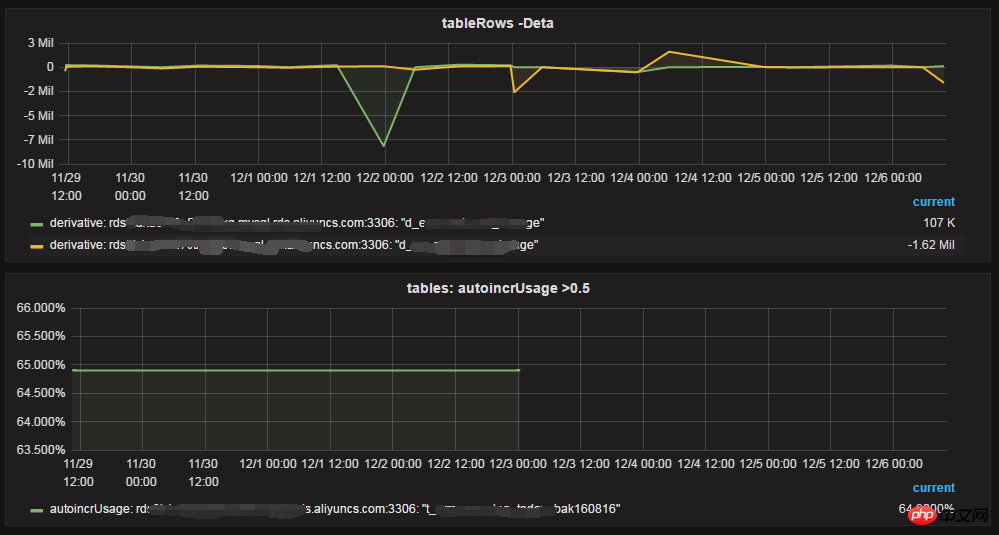
Incrément du nombre de lignes par jour, utilisation auto_increment
4. Plus
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
 Comment installer MySQL dans CentOS7
Apr 14, 2025 pm 08:30 PM
Comment installer MySQL dans CentOS7
Apr 14, 2025 pm 08:30 PM
La clé de l'installation de MySQL est d'élégance pour ajouter le référentiel MySQL officiel. Les étapes spécifiques sont les suivantes: Téléchargez la clé GPG officielle MySQL pour empêcher les attaques de phishing. Ajouter un fichier de référentiel MySQL: RPM -UVH https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm Mise à jour du référentiel Cache: Yum Update Installation Mysql: Yum install install install starting starting mysql Service: SystemCTL start start mysqld starger bugo boartup Service mysql Service: SystemCTL start start mysqld starger bugo bo onthing staring Service mysql Service: SystemCTL Start Start MySQLD Set Out Up Boaching Staring Service MySQL Service: SystemCTL Start Start MysQL
