
 Java
javaDidacticiel
Une introduction détaillée au résumé et à la réflexion sur la programmation simultanée Java
Java
javaDidacticiel
Une introduction détaillée au résumé et à la réflexion sur la programmation simultanée Java
Une introduction détaillée au résumé et à la réflexion sur la programmation simultanée Java

Écrire un bon code concurrent est extrêmement difficile. Le langage Java intègre un support multi-threading depuis la première version, ce qui était très remarquable à l'époque. Cependant, lorsque nous avons une compréhension plus profonde et une plus grande pratique de la programmation simultanée, la réalisation de la programmation simultanée. a plus de solutions et de meilleurs choix. Cet article est un résumé et une réflexion sur la programmation simultanée. Il partage également une certaine expérience sur la façon d'écrire du code simultané dans Java 5 et les versions ultérieures.
Pourquoi la concurrence est nécessaire
La concurrence est en fait une stratégie de découplage, qui nous aide à séparer ce qu'il faut faire (objectif) et quand le faire (timing). Cela peut améliorer considérablement le débit de l'application (plus de temps de planification du processeur) et sa structure (le programme comporte plusieurs parties travaillant ensemble). Quiconque a fait du développement Java Web sait que le programme Servlet dans Java Web adopte un mode de travail multi-thread à instance unique avec la prise en charge du conteneur Servlet. Le conteneur Servlet gère les problèmes de concurrence pour vous.
Malentendus et réponses
Les malentendus les plus courants concernant la programmation simultanée sont les suivants :
-La concurrence améliore toujours les performances (la concurrence laisse beaucoup de temps d'inactivité sur le CPU) peut améliorer considérablement les performances du programme, mais lorsque le nombre de threads est important, une commutation fréquente de la planification entre les threads dégradera les performances du système)
-L'écriture de programmes simultanés ne nécessite pas de modifier la conception d'origine (le but est le même que le timing du découplage a souvent un impact énorme sur la structure du système)
-Ne vous inquiétez pas des problèmes de concurrence lors de l'utilisation de conteneurs Web ou EJB (seulement en comprenant ce que fait le conteneur peut vous utilisez mieux le conteneur)
Les déclarations suivantes sont des compréhensions objectives de la concurrence :
-L'écriture de programmes concurrents ajoutera une surcharge supplémentaire au code
-Concurrence correcte C'est très complexe, même pour des problèmes très simples
-Les défauts de concurrence ne sont pas faciles à trouver car ils ne sont pas faciles à reproduire
-La concurrence nécessite souvent des modifications fondamentales dans la conception stratégie
Principes et techniques de programmation concurrente
Principe de responsabilité unique
Code lié à la concurrence séparé et autre code (le code lié à la concurrence a son propre cycle de vie de développement, de modification et de réglage).
Limiter la portée des données
Deux threads peuvent interférer l'un avec l'autre lors de la modification du même champ d'un objet partagé, ce qui entraîne un comportement imprévisible. Une solution consiste à construire un critique. domaines, mais le nombre de domaines critiques doit être limité.
Utiliser des copies de données
Les copies de données sont un bon moyen d'éviter de partager des données. Les objets copiés sont uniquement traités en lecture seule. Une classe nommée CopyOnWriteArrayList a été ajoutée au package java.util.concurrent de Java 5. Il s'agit d'un sous-type de l'interface List, vous pouvez donc la considérer comme une version thread-safe d'ArrayList. Elle utilise la copie sur écriture. créez une copie des données. Effectuez des actions pour éviter les problèmes causés par un accès simultané aux données partagées.
Les threads doivent être aussi indépendants que possible
Laissez les threads exister dans leur propre monde et ne partagez pas de données avec d'autres threads. Toute personne ayant de l'expérience dans le développement Web Java sait que Servlet fonctionne en instance unique et de manière multithread. Les données liées à chaque requête sont transmises via les paramètres de la méthode de service (ou méthode doGet ou doPost) de la sous-classe Servlet. de. Tant que le code du servlet utilise uniquement des variables locales, le servlet ne posera pas de problèmes de synchronisation. Le contrôleur springMVC fait la même chose. Les objets obtenus à partir de la requête sont transmis en tant que paramètres de méthode plutôt qu'en tant que membres de la classe. Évidemment, Struts 2 fait le contraire, donc la classe Action en tant que contrôleur dans Struts 2 correspond à un. exemple.
Programmation simultanée avant Java 5
Le modèle de thread de Java est basé sur une planification préemptive des threads, c'est-à-dire :
Tous les threads peuvent partagez facilement des objets dans le même processus.
Tout fil de discussion ayant une référence à ces objets peut modifier ces objets.
Pour protéger les données, les objets peuvent être verrouillés.
La concurrence Java basée sur les threads et les verrous est de trop bas niveau, et l'utilisation de verrous est souvent très mauvaise, car cela équivaut à transformer toute concurrence en files d'attente.
Avant Java 5, le mot-clé synchronisé pouvait être utilisé pour implémenter la fonction de verrouillage. Il pouvait être utilisé dans les blocs de code et les méthodes, indiquant que le thread doit obtenir le verrou approprié avant d'exécuter l'intégralité du bloc de code ou de la méthode. Pour les méthodes non statiques (méthodes membres) d'une classe, cela signifie acquérir le verrou de l'instance d'objet. Pour les méthodes statiques (méthodes de classe) de la classe, cela signifie acquérir le verrou de l'objet Class de la classe. blocs, les Programmeurs peuvent spécifier quel verrou d'objet doit être obtenu.
Qu'il s'agisse d'un bloc de code synchronisé ou d'une méthode synchronisée, un seul thread peut entrer à la fois. Si d'autres threads tentent d'entrer (qu'il s'agisse du même bloc synchronisé ou d'un bloc synchronisé différent), la JVM les suspendra. (mettez-les dans les sas d'attente). Cette structure est appelée section critique dans la théorie de la concurrence. Ici, nous pouvons faire un résumé des fonctions d'utilisation de synchronisé pour implémenter la synchronisation et le verrouillage en Java :
Peut verrouiller uniquement les objets, pas les types de données de base
-
Les objets individuels du tableau d'objets verrouillés ne seront pas verrouillés
Une méthode synchronisée peut être considérée comme un bloc de code synchronisé(this) { … } qui contient la méthode entière
La méthode de synchronisation statique verrouillera son objet Class
La synchronisation de la classe interne est indépendante de la classe externe
Le modificateur synchronisé ne fait pas partie de la signature de la méthode, il ne peut donc pas apparaître dans la déclaration de méthode de l'interface
Les méthodes asynchrones ne se soucient pas du du verrou state, ils le sont La méthode synchronisée peut toujours s'exécuter lorsqu'elle est en cours d'exécution
Le verrou implémenté par synchronisé est un verrou réentrant.
À l'intérieur de la JVM, afin d'améliorer l'efficacité, chaque thread exécuté en même temps aura une copie en cache des données qu'il traite. Lorsque nous utilisons la synchronisation pour la synchronisation, qu'est-ce que c'est. réellement synchronisé Il s'agit d'un bloc mémoire qui représente l'objet verrouillé dans différents threads (les données de copie resteront synchronisées avec la mémoire principale. Vous savez maintenant pourquoi le mot synchronisation est utilisé en termes simples, après l'exécution du bloc de synchronisation ou de la méthode de synchronisation). , toute modification apportée à l'objet verrouillé doit être réécrite dans la mémoire principale avant de libérer le verrou ; après être entré dans le bloc de synchronisation pour obtenir le verrou, les données de l'objet verrouillé sont lues dans la mémoire principale et une copie du les données du thread détenant le verrou sont Il doit être synchronisé avec la vue des données dans la mémoire principale.
Dans la version originale de Java, il y avait un mot-clé appelé Volatile, qui est un mécanisme de traitement de synchronisation simple, car les variables modifiées par volatile suivent les règles suivantes :
La valeur d'une variable est toujours lue dans la mémoire principale avant utilisation.
Les modifications apportées aux valeurs des variables sont toujours réécrites dans la mémoire principale une fois terminées.
L'utilisation du mot clé volatile peut empêcher le compilateur d'hypothèses d'optimisation incorrectes dans un environnement multithread (le compilateur peut optimiser les variables dont les valeurs ne changeront pas dans un thread en constantes) ) , mais seules les variables qui, une fois modifiées, ne dépendent pas de l'état actuel (valeur lors de la lecture) doivent être déclarées volatiles.
Le mode immuable est également une conception qui peut être envisagée lors de la programmation concurrente. Laissez l'état de l'objet rester inchangé. Si vous souhaitez modifier l'état de l'objet, vous allez créer une copie de l'objet et écrire les modifications dans la copie sans changer l'objet d'origine, afin qu'il y ait il n'y aura pas d'état incohérent, donc les objets immuables sont thread-safe. La classe String que nous utilisons très fréquemment en Java adopte cette conception. Si vous n'êtes pas familier avec les modèles immuables, vous pouvez lire le chapitre 34 du livre du Dr Yan Hong "Java and Patterns". Cela dit, vous réalisez peut-être également l’importance du mot-clé final.
Programmation simultanée en Java 5
Peu importe la direction dans laquelle Java se développe ou meurt dans le futur, Java 5 est définitivement une version extrêmement importante dans l'histoire du développement Java. Cette version fournit différents langages. ne discuterai pas des fonctionnalités ici (si vous êtes intéressé, vous pouvez lire mon autre article "La 20e année de Java : Regard sur le développement de la technologie de programmation à partir de l'évolution des versions Java"), mais nous devons remercier Doug Lea de lui avoir fourni dans Java 5 Le package java.util.concurrent, chef-d'œuvre historique, son émergence offre à la programmation simultanée Java plus de choix et de meilleures méthodes de travail. Le chef-d'œuvre de Doug Lea comprend principalement le contenu suivant :
De meilleurs conteneurs thread-safe
-
Pools de threads et classes d'outils associées
Solution non bloquante facultative
Mécanisme de verrouillage et de sémaphore explicite
Ci-dessous, nous avons expliqué ces choses une par une.
Classe Atomic
Il existe un sous-paquet atomique sous le package java.util.concurrent dans Java 5, qui comporte plusieurs classes commençant par Atomic, telles que AtomicInteger et AtomicLong. Ils profitent des caractéristiques des processeurs modernes et peuvent effectuer des opérations atomiques de manière non bloquante. Le code est le suivant :
/**
ID序列生成器
*/
public class IdGenerator {
private final AtomicLong sequenceNumber = new AtomicLong(0);
public long next() {
return sequenceNumber.getAndIncrement();
}
}Verrouillage de l'écran
Le mécanisme de verrouillage basé sur le. Le mot-clé synchronisé est le suivant Problème :
Il n'existe qu'un seul type de verrou, et il a le même effet sur toutes les opérations de synchronisation
Verrous ne peut être utilisé que dans des blocs ou des méthodes de code Acquérir au début et relâcher à la fin
Le fil obtient le verrou ou est bloqué, il n'y a pas d'autre possibilité
Java 5 paires Le mécanisme de verrouillage a été reconstruit et fournit des verrous affichés, ce qui peut améliorer le mécanisme de verrouillage dans les aspects suivants :
可以添加不同类型的锁,例如读取锁和写入锁
可以在一个方法中加锁,在另一个方法中解锁
可以使用tryLock方式尝试获得锁,如果得不到锁可以等待、回退或者干点别的事情,当然也可以在超时之后放弃操作
显示的锁都实现了java.util.concurrent.Lock接口,主要有两个实现类:
ReentrantLock – 比synchronized稍微灵活一些的重入锁
ReentrantReadWriteLock – 在读操作很多写操作很少时性能更好的一种重入锁
对于如何使用显示锁,可以参考我的Java面试系列文章《Java面试题集51-70》中第60题的代码。只有一点需要提醒,解锁的方法unlock的调用最好能够在finally块中,因为这里是释放外部资源最好的地方,当然也是释放锁的最佳位置,因为不管正常异常可能都要释放掉锁来给其他线程以运行的机会。
CountDownLatch
CountDownLatch是一种简单的同步模式,它让一个线程可以等待一个或多个线程完成它们的工作从而避免对临界资源并发访问所引发的各种问题。下面借用别人的一段代码(我对它做了一些重构)来演示CountDownLatch是如何工作的。
import java.util.concurrent.CountDownLatch;
/**
* 工人类
* @author 骆昊
*
*/
class Worker {
private String name; // 名字
private long workDuration; // 工作持续时间
/**
* 构造器
*/
public Worker(String name, long workDuration) {
this.name = name;
this.workDuration = workDuration;
}
/**
* 完成工作
*/
public void doWork() {
System.out.println(name + " begins to work...");
try {
Thread.sleep(workDuration); // 用休眠模拟工作执行的时间
} catch(InterruptedException ex) {
ex.printStackTrace();
}
System.out.println(name + " has finished the job...");
}
}
/**
* 测试线程
* @author 骆昊
*
*/
class WorkerTestThread implements Runnable {
private Worker worker;
private CountDownLatch cdLatch;
public WorkerTestThread(Worker worker, CountDownLatch cdLatch) {
this.worker = worker;
this.cdLatch = cdLatch;
}
@Override
public void run() {
worker.doWork(); // 让工人开始工作
cdLatch.countDown(); // 工作完成后倒计时次数减1
}
}
class CountDownLatchTest {
private static final int MAX_WORK_DURATION = 5000; // 最大工作时间
private static final int MIN_WORK_DURATION = 1000; // 最小工作时间
// 产生随机的工作时间
private static long getRandomWorkDuration(long min, long max) {
return (long) (Math.random() * (max - min) + min);
}
public static void main(String[] args) {
CountDownLatch latch = new CountDownLatch(2); // 创建倒计时闩并指定倒计时次数为2
Worker w1 = new Worker("骆昊", getRandomWorkDuration(MIN_WORK_DURATION, MAX_WORK_DURATION));
Worker w2 = new Worker("王大锤", getRandomWorkDuration(MIN_WORK_DURATION, MAX_WORK_DURATION));
new Thread(new WorkerTestThread(w1, latch)).start();
new Thread(new WorkerTestThread(w2, latch)).start();
try {
latch.await(); // 等待倒计时闩减到0
System.out.println("All jobs have been finished!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}ConcurrentHashMap
ConcurrentHashMap是HashMap在并发环境下的版本,大家可能要问,既然已经可以通过Collections.synchronizedMap获得线程安全的映射型容器,为什么还需要ConcurrentHashMap呢?因为通过Collections工具类获得的线程安全的HashMap会在读写数据时对整个容器对象上锁,这样其他使用该容器的线程无论如何也无法再获得该对象的锁,也就意味着要一直等待前一个获得锁的线程离开同步代码块之后才有机会执行。实际上,HashMap是通过哈希函数来确定存放键值对的桶(桶是为了解决哈希冲突而引入的),修改HashMap时并不需要将整个容器锁住,只需要锁住即将修改的“桶”就可以了。HashMap的数据结构如下图所示。
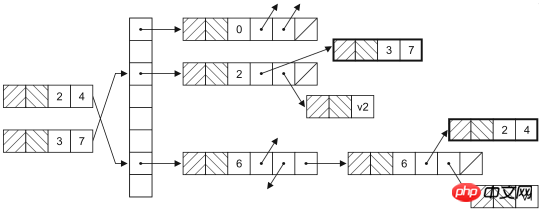
此外,ConcurrentHashMap还提供了原子操作的方法,如下所示:
putIfAbsent:如果还没有对应的键值对映射,就将其添加到HashMap中。
remove:如果键存在而且值与当前状态相等(equals比较结果为true),则用原子方式移除该键值对映射
replace:替换掉映射中元素的原子操作
CopyOnWriteArrayList
CopyOnWriteArrayList是ArrayList在并发环境下的替代品。CopyOnWriteArrayList通过增加写时复制语义来避免并发访问引起的问题,也就是说任何修改操作都会在底层创建一个列表的副本,也就意味着之前已有的迭代器不会碰到意料之外的修改。这种方式对于不要严格读写同步的场景非常有用,因为它提供了更好的性能。记住,要尽量减少锁的使用,因为那势必带来性能的下降(对数据库中数据的并发访问不也是如此吗?如果可以的话就应该放弃悲观锁而使用乐观锁),CopyOnWriteArrayList很明显也是通过牺牲空间获得了时间(在计算机的世界里,时间和空间通常是不可调和的矛盾,可以牺牲空间来提升效率获得时间,当然也可以通过牺牲时间来减少对空间的使用)。
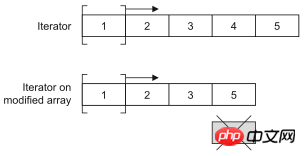
可以通过下面两段代码的运行状况来验证一下CopyOnWriteArrayList是不是线程安全的容器。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
class AddThread implements Runnable {
private List<Double> list;
public AddThread(List<Double> list) {
this.list = list;
}
@Override
public void run() {
for(int i = 0; i < 10000; ++i) {
list.add(Math.random());
}
}
}
public class Test05 {
private static final int THREAD_POOL_SIZE = 2;
public static void main(String[] args) {
List<Double> list = new ArrayList<>();
ExecutorService es = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
es.execute(new AddThread(list));
es.execute(new AddThread(list));
es.shutdown();
}
}上面的代码会在运行时产生ArrayIndexOutOfBoundsException,试一试将上面代码25行的ArrayList换成CopyOnWriteArrayList再重新运行。
List<Double> list = new CopyOnWriteArrayList<>();
Queue
队列是一个无处不在的美妙概念,它提供了一种简单又可靠的方式将资源分发给处理单元(也可以说是将工作单元分配给待处理的资源,这取决于你看待问题的方式)。实现中的并发编程模型很多都依赖队列来实现,因为它可以在线程之间传递工作单元。
Java 5中的BlockingQueue就是一个在并发环境下非常好用的工具,在调用put方法向队列中插入元素时,如果队列已满,它会让插入元素的线程等待队列腾出空间;在调用take方法从队列中取元素时,如果队列为空,取出元素的线程就会阻塞。
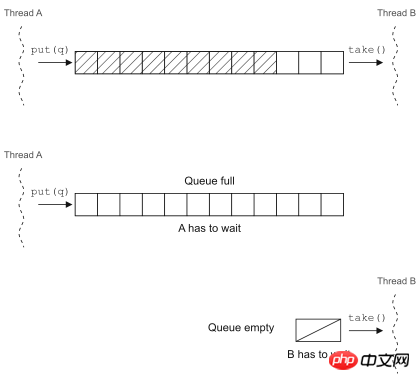
可以用BlockingQueue来实现生产者-消费者并发模型(下一节中有介绍),当然在Java 5以前也可以通过wait和notify来实现线程调度,比较一下两种代码就知道基于已有的并发工具类来重构并发代码到底好在哪里了。
基于wait和notify的实现
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 公共常量
* @author 骆昊
*
*/
class Constants {
public static final int MAX_BUFFER_SIZE = 10;
public static final int NUM_OF_PRODUCER = 2;
public static final int NUM_OF_CONSUMER = 3;
}
/**
* 工作任务
* @author 骆昊
*
*/
class Task {
private String id; // 任务的编号
public Task() {
id = UUID.randomUUID().toString();
}
@Override
public String toString() {
return "Task[" + id + "]";
}
}
/**
* 消费者
* @author 骆昊
*
*/
class Consumer implements Runnable {
private List<Task> buffer;
public Consumer(List<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
synchronized(buffer) {
while(buffer.isEmpty()) {
try {
buffer.wait();
} catch(InterruptedException e) {
e.printStackTrace();
}
}
Task task = buffer.remove(0);
buffer.notifyAll();
System.out.println("Consumer[" + Thread.currentThread().getName() + "] got " + task);
}
}
}
}
/**
* 生产者
* @author 骆昊
*
*/
class Producer implements Runnable {
private List<Task> buffer;
public Producer(List<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
synchronized (buffer) {
while(buffer.size() >= Constants.MAX_BUFFER_SIZE) {
try {
buffer.wait();
} catch(InterruptedException e) {
e.printStackTrace();
}
}
Task task = new Task();
buffer.add(task);
buffer.notifyAll();
System.out.println("Producer[" + Thread.currentThread().getName() + "] put " + task);
}
}
}
}
public class Test06 {
public static void main(String[] args) {
List<Task> buffer = new ArrayList<>(Constants.MAX_BUFFER_SIZE);
ExecutorService es = Executors.newFixedThreadPool(Constants.NUM_OF_CONSUMER + Constants.NUM_OF_PRODUCER);
for(int i = 1; i <= Constants.NUM_OF_PRODUCER; ++i) {
es.execute(new Producer(buffer));
}
for(int i = 1; i <= Constants.NUM_OF_CONSUMER; ++i) {
es.execute(new Consumer(buffer));
}
}
}基于BlockingQueue的实现
import java.util.UUID;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
/**
* 公共常量
* @author 骆昊
*
*/
class Constants {
public static final int MAX_BUFFER_SIZE = 10;
public static final int NUM_OF_PRODUCER = 2;
public static final int NUM_OF_CONSUMER = 3;
}
/**
* 工作任务
* @author 骆昊
*
*/
class Task {
private String id; // 任务的编号
public Task() {
id = UUID.randomUUID().toString();
}
@Override
public String toString() {
return "Task[" + id + "]";
}
}
/**
* 消费者
* @author 骆昊
*
*/
class Consumer implements Runnable {
private BlockingQueue<Task> buffer;
public Consumer(BlockingQueue<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
try {
Task task = buffer.take();
System.out.println("Consumer[" + Thread.currentThread().getName() + "] got " + task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
/**
* 生产者
* @author 骆昊
*
*/
class Producer implements Runnable {
private BlockingQueue<Task> buffer;
public Producer(BlockingQueue<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
try {
Task task = new Task();
buffer.put(task);
System.out.println("Producer[" + Thread.currentThread().getName() + "] put " + task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Test07 {
public static void main(String[] args) {
BlockingQueue<Task> buffer = new LinkedBlockingQueue<>(Constants.MAX_BUFFER_SIZE);
ExecutorService es = Executors.newFixedThreadPool(Constants.NUM_OF_CONSUMER + Constants.NUM_OF_PRODUCER);
for(int i = 1; i <= Constants.NUM_OF_PRODUCER; ++i) {
es.execute(new Producer(buffer));
}
for(int i = 1; i <= Constants.NUM_OF_CONSUMER; ++i) {
es.execute(new Consumer(buffer));
}
}
}使用BlockingQueue后代码优雅了很多。
并发模型
在继续下面的探讨之前,我们还是重温一下几个概念:
| 概念 | 解释 |
|---|---|
| 临界资源 | 并发环境中有着固定数量的资源 |
| 互斥 | 对资源的访问是排他式的 |
| 饥饿 | 一个或一组线程长时间或永远无法取得进展 |
| 死锁 | 两个或多个线程相互等待对方结束 |
| 活锁 | 想要执行的线程总是发现其他的线程正在执行以至于长时间或永远无法执行 |
重温了这几个概念后,我们可以探讨一下下面的几种并发模型。
生产者-消费者
一个或多个生产者创建某些工作并将其置于缓冲区或队列中,一个或多个消费者会从队列中获得这些工作并完成之。这里的缓冲区或队列是临界资源。当缓冲区或队列放满的时候,生产这会被阻塞;而缓冲区或队列为空的时候,消费者会被阻塞。生产者和消费者的调度是通过二者相互交换信号完成的。
读者-写者
当存在一个主要为读者提供信息的共享资源,它偶尔会被写者更新,但是需要考虑系统的吞吐量,又要防止饥饿和陈旧资源得不到更新的问题。在这种并发模型中,如何平衡读者和写者是最困难的,当然这个问题至今还是一个被热议的问题,恐怕必须根据具体的场景来提供合适的解决方案而没有那种放之四海而皆准的方法(不像我在国内的科研文献中看到的那样)。
哲学家进餐
1965年,荷兰计算机科学家图灵奖得主Edsger Wybe Dijkstra提出并解决了一个他称之为哲学家进餐的同步问题。这个问题可以简单地描述如下:五个哲学家围坐在一张圆桌周围,每个哲学家面前都有一盘通心粉。由于通心粉很滑,所以需要两把叉子才能夹住。相邻两个盘子之间放有一把叉子如下图所示。哲学家的生活中有两种交替活动时段:即吃饭和思考。当一个哲学家觉得饿了时,他就试图分两次去取其左边和右边的叉子,每次拿一把,但不分次序。如果成功地得到了两把叉子,就开始吃饭,吃完后放下叉子继续思考。
把上面问题中的哲学家换成线程,把叉子换成竞争的临界资源,上面的问题就是线程竞争资源的问题。如果没有经过精心的设计,系统就会出现死锁、活锁、吞吐量下降等问题。
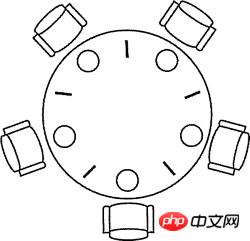
下面是用信号量原语来解决哲学家进餐问题的代码,使用了Java 5并发工具包中的Semaphore类(代码不够漂亮但是已经足以说明问题了)。
//import java.util.concurrent.ExecutorService;
//import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* 存放线程共享信号量的上下问
* @author 骆昊
*
*/
class AppContext {
public static final int NUM_OF_FORKS = 5; // 叉子数量(资源)
public static final int NUM_OF_PHILO = 5; // 哲学家数量(线程)
public static Semaphore[] forks; // 叉子的信号量
public static Semaphore counter; // 哲学家的信号量
static {
forks = new Semaphore[NUM_OF_FORKS];
for (int i = 0, len = forks.length; i < len; ++i) {
forks[i] = new Semaphore(1); // 每个叉子的信号量为1
}
counter = new Semaphore(NUM_OF_PHILO - 1); // 如果有N个哲学家,最多只允许N-1人同时取叉子
}
/**
* 取得叉子
* @param index 第几个哲学家
* @param leftFirst 是否先取得左边的叉子
* @throws InterruptedException
*/
public static void putOnFork(int index, boolean leftFirst) throws InterruptedException {
if(leftFirst) {
forks[index].acquire();
forks[(index + 1) % NUM_OF_PHILO].acquire();
}
else {
forks[(index + 1) % NUM_OF_PHILO].acquire();
forks[index].acquire();
}
}
/**
* 放回叉子
* @param index 第几个哲学家
* @param leftFirst 是否先放回左边的叉子
* @throws InterruptedException
*/
public static void putDownFork(int index, boolean leftFirst) throws InterruptedException {
if(leftFirst) {
forks[index].release();
forks[(index + 1) % NUM_OF_PHILO].release();
}
else {
forks[(index + 1) % NUM_OF_PHILO].release();
forks[index].release();
}
}
}
/**
* 哲学家
* @author 骆昊
*
*/
class Philosopher implements Runnable {
private int index; // 编号
private String name; // 名字
public Philosopher(int index, String name) {
this.index = index;
this.name = name;
}
@Override
public void run() {
while(true) {
try {
AppContext.counter.acquire();
boolean leftFirst = index % 2 == 0;
AppContext.putOnFork(index, leftFirst);
System.out.println(name + "正在吃意大利面(通心粉)..."); // 取到两个叉子就可以进食
AppContext.putDownFork(index, leftFirst);
AppContext.counter.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Test04 {
public static void main(String[] args) {
String[] names = { "骆昊", "王大锤", "张三丰", "杨过", "李莫愁" }; // 5位哲学家的名字
// ExecutorService es = Executors.newFixedThreadPool(AppContext.NUM_OF_PHILO); // 创建固定大小的线程池
// for(int i = 0, len = names.length; i < len; ++i) {
// es.execute(new Philosopher(i, names[i])); // 启动线程
// }
// es.shutdown();
for(int i = 0, len = names.length; i < len; ++i) {
new Thread(new Philosopher(i, names[i])).start();
}
}
}现实中的并发问题基本上都是这三种模型或者是这三种模型的变体。
测试并发代码
对并发代码的测试也是非常棘手的事情,棘手到无需说明大家也很清楚的程度,所以这里我们只是探讨一下如何解决这个棘手的问题。我们建议大家编写一些能够发现问题的测试并经常性的在不同的配置和不同的负载下运行这些测试。不要忽略掉任何一次失败的测试,线程代码中的缺陷可能在上万次测试中仅仅出现一次。具体来说有这么几个注意事项:
不要将系统的失效归结于偶发事件,就像拉不出屎的时候不能怪地球没有引力。
先让非并发代码工作起来,不要试图同时找到并发和非并发代码中的缺陷。
编写可以在不同配置环境下运行的线程代码。
编写容易调整的线程代码,这样可以调整线程使性能达到最优。
让线程的数量多于CPU或CPU核心的数量,这样CPU调度切换过程中潜在的问题才会暴露出来。
让并发代码在不同的平台上运行。
通过自动化或者硬编码的方式向并发代码中加入一些辅助测试的代码。
Java 7的并发编程
Java 7中引入了TransferQueue,它比BlockingQueue多了一个叫transfer的方法,如果接收线程处于等待状态,该操作可以马上将任务交给它,否则就会阻塞直至取走该任务的线程出现。可以用TransferQueue代替BlockingQueue,因为它可以获得更好的性能。
刚才忘记了一件事情,Java 5中还引入了Callable接口、Future接口和FutureTask接口,通过他们也可以构建并发应用程序,代码如下所示。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class Test07 {
private static final int POOL_SIZE = 10;
static class CalcThread implements Callable<Double> {
private List<Double> dataList = new ArrayList<>();
public CalcThread() {
for(int i = 0; i < 10000; ++i) {
dataList.add(Math.random());
}
}
@Override
public Double call() throws Exception {
double total = 0;
for(Double d : dataList) {
total += d;
}
return total / dataList.size();
}
}
public static void main(String[] args) {
List<Future<Double>> fList = new ArrayList<>();
ExecutorService es = Executors.newFixedThreadPool(POOL_SIZE);
for(int i = 0; i < POOL_SIZE; ++i) {
fList.add(es.submit(new CalcThread()));
}
for(Future<Double> f : fList) {
try {
System.out.println(f.get());
} catch (Exception e) {
e.printStackTrace();
}
}
es.shutdown();
}
}Callable接口也是一个单方法接口,显然这是一个回调方法,类似于函数式编程中的回调函数,在Java 8 以前,Java中还不能使用Lambda表达式来简化这种函数式编程。和Runnable接口不同的是Callable接口的回调方法call方法会返回一个对象,这个对象可以用将来时的方式在线程执行结束的时候获得信息。上面代码中的call方法就是将计算出的10000个0到1之间的随机小数的平均值返回,我们通过一个Future接口的对象得到了这个返回值。目前最新的Java版本中,Callable接口和Runnable接口都被打上了@FunctionalInterface的注解,也就是说它可以用函数式编程的方式(Lambda表达式)创建接口对象。
下面是Future接口的主要方法:
get():获取结果。如果结果还没有准备好,get方法会阻塞直到取得结果;当然也可以通过参数设置阻塞超时时间。
cancel():在运算结束前取消。
isDone():可以用来判断运算是否结束。
Java 7中还提供了分支/合并(fork/join)框架,它可以实现线程池中任务的自动调度,并且这种调度对用户来说是透明的。为了达到这种效果,必须按照用户指定的方式对任务进行分解,然后再将分解出的小型任务的执行结果合并成原来任务的执行结果。这显然是运用了分治法(pide-and-conquer)的思想。下面的代码使用了分支/合并框架来计算1到10000的和,当然对于如此简单的任务根本不需要分支/合并框架,因为分支和合并本身也会带来一定的开销,但是这里我们只是探索一下在代码中如何使用分支/合并框架,让我们的代码能够充分利用现代多核CPU的强大运算能力。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
class Calculator extends RecursiveTask<Integer> {
private static final long serialVersionUID = 7333472779649130114L;
private static final int THRESHOLD = 10;
private int start;
private int end;
public Calculator(int start, int end) {
this.start = start;
this.end = end;
}
@Override
public Integer compute() {
int sum = 0;
if ((end - start) < THRESHOLD) { // 当问题分解到可求解程度时直接计算结果
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
int middle = (start + end) >>> 1;
// 将任务一分为二
Calculator left = new Calculator(start, middle);
Calculator right = new Calculator(middle + 1, end);
left.fork();
right.fork();
// 注意:由于此处是递归式的任务分解,也就意味着接下来会二分为四,四分为八...
sum = left.join() + right.join(); // 合并两个子任务的结果
}
return sum;
}
}
public class Test08 {
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
Future<Integer> result = forkJoinPool.submit(new Calculator(1, 10000));
System.out.println(result.get());
}
}伴随着Java 7的到来,Java中默认的数组排序算法已经不再是经典的快速排序(双枢轴快速排序)了,新的排序算法叫TimSort,它是归并排序和插入排序的混合体,TimSort可以通过分支合并框架充分利用现代处理器的多核特性,从而获得更好的性能(更短的排序时间)。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
