
 interface Web
js tutoriel
Explication détaillée en Javascript de la portée, de la chaîne de portée et de la fermeture (image et texte)
interface Web
js tutoriel
Explication détaillée en Javascript de la portée, de la chaîne de portée et de la fermeture (image et texte)
Explication détaillée en Javascript de la portée, de la chaîne de portée et de la fermeture (image et texte)

Cet article présente principalement le diagramme Javascript - portée, chaîne de portée, fermeture et autres connaissances. A une très bonne valeur de référence. Jetons-y un coup d'œil avec l'éditeur ci-dessous
Qu'est-ce que la portée ?
La portée est une règle déterminée lors de la phase de compilation du code et qui stipule la portée accessible des variables et des fonctions. Les variables globales ont une portée globale et les variables locales ont une portée locale. js est un langage sans portée au niveau du bloc (les blocs de code d'accolade, y compris if, for et d'autres instructions ou les blocs de code d'accolade individuels ne peuvent pas former une portée locale), donc le rôle local de js Le domaine est formé par et uniquement le bloc de code défini entre les accolades de la fonction, c'est-à-dire la portée de la fonction.
Qu'est-ce qu'une chaîne de scope ?
La chaîne de portée est l'implémentation de règles de portée. Grâce à la mise en œuvre de la chaîne de portée, les variables sont accessibles dans sa portée et les fonctions peuvent être appelées dans sa portée.
Une chaîne de portée est une liste chaînée accessible dans un seul sens. Chaque nœud de cette liste chaînée est une variable objet du contexte d'exécution (c'est un objet actif lorsque le le code est exécuté). Une liste chaînée unidirectionnelle. La tête (le premier nœud accessible) est toujours l'objet variable (objet actif) de la fonction en cours d'appel et d'exécution, et la queue est toujours l'objet actif global.
La formation d'une chaîne de portée ?
Regardons le processus de formation de la chaîne de portée à partir de l'exécution d'un morceau de code.
function fun01 () {
console.log('i am fun01...');
fun02();
}
function fun02 () {
console.log('i am fun02...');
}
fun01();
Processus d'accès aux données
Comme indiqué ci-dessus, lorsque le programme accède à une variable, il suit le processus à sens unique scope chain Pour accéder aux caractéristiques, recherchez d'abord dans l'AO du nœud de tête, sinon recherchez dans l'AO du nœud suivant, jusqu'au nœud de queue (AO global). Dans ce processus, s'il est trouvé, il sera trouvé. S'il n'est pas trouvé, une erreur non définie sera signalée.
Étendre la chaîne de portée
De la formation de la chaîne de portée ci-dessus, nous pouvons voir que chaque nœud de la chaîne se déplace vers la tête de chaîne lorsque la fonction est appelée et exécuté.AO de la fonction actuelle, et une autre façon de former des nœuds est de "étendre la chaîne de portée", c'est-à-dire d'insérer une portée d'objet que nous voulons en tête de la chaîne de portée. Il existe deux façons d'étendre la chaîne de portée :
1.avec déclaration
function fun01 () {
with (document) {
console.log('I am fun01 and I am in document scope...')
}
}
fun01();
2. Le bloc catch de l'instruction try-catch
function fun01 () {
try {
console.log('Some exceptions will happen...')
} catch (e) {
console.log(e)
}
}
fun01();
ps : personnellement, je pense qu'il n'y en a pas Il est très nécessaire d'utiliser l'instruction with, essayez. L'utilisation de -catch dépend également des besoins. Personnellement, je n'utilise pas beaucoup ces deux-là, mais au cours du processus d'organisation de cette partie, j'ai trouvé quelques conseils immatures d'Optimisation des performances au niveau de la chaîne de portée.
Une petite suggestion immature sur l'optimisation des performances causée par la chaîne de portée
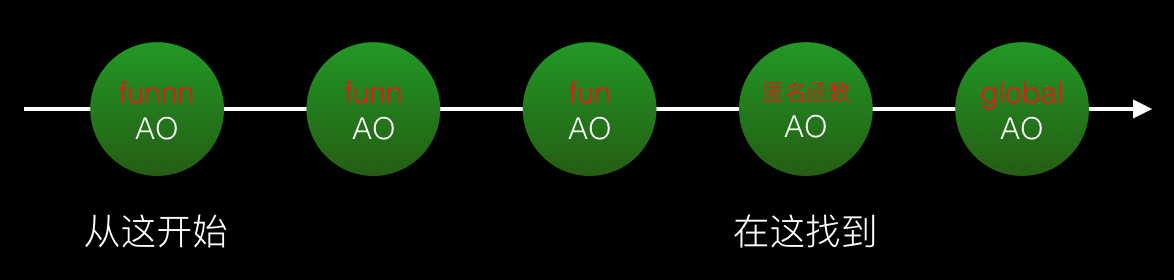
1. Réduisez l'accès à la chaîne de portée du nœud de variables <🎜. >
Ici, nous personnalisons un classement appelé "distance de recherche", qui représente le nombre de nœuds dans la chaîne de portée par lesquels le programme passe pour accéder à une variable non définie. Car si la variable n'est pas trouvée au nœud actuel, elle passe au nœud suivant à rechercher, et il est également nécessaire de déterminer si la variable recherchée existe dans le nœud suivant. Plus la « distance de recherche » est longue, plus les actions de « saut » et de « jugement » sont nécessaires, et plus la surcharge de ressources est importante, affectant ainsi les performances. Cet écart de performances peut ne pas causer trop de problèmes de performances pour quelques opérations de recherche de variables, mais si les opérations de recherche de variables sont effectuées plusieurs fois, la comparaison des performances sera plus évidente.(function(){
console.time()
var find = 1 //这个find变量需要在4个作用域链节点进行查找
function fun () {
function funn () {
var funnv = 1;
var funnvv = 2;
function funnn () {
var i = 0
while(i <= 100000000){
if(find){
i++
}
}
}
funnn()
}
funn()
}
fun()
console.timeEnd()
})()
(function(){
console.time()
function fun () {
function funn () {
var funnv = 1;
var funnvv = 2;
function funnn () {
var i = 0
var find = 1 //这个find变量只在当前节点进行查找
while(i <= 100000000){
if(find){
i++
}
}
}
funnn()
}
funn()
}
fun()
console.timeEnd()
})()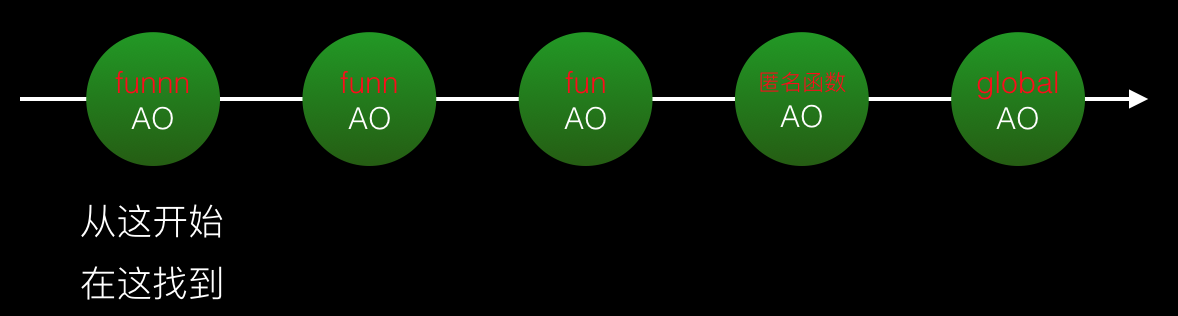
2. Évitez trop de définitions de variables sur le nœud AO dans la chaîne de portée
La principale raison pour laquelle trop de définitions de variables entraînent des problèmes de performances C'est l'opération de « jugement » dans le processus de recherche de variables qui coûte cher. Nous utilisons with pour comparer les performances.(function(){
console.time()
function fun () {
function funn () {
var funnv = 1;
var funnvv = 2;
function funnn () {
var i = 0
var find = 10
with (document) {
while(i <= 1000000){
if(find){
i++
}
}
}
}
funnn()
}
funn()
}
fun()
console.timeEnd()
})()
在mac pro的chrome浏览器下做实验,进行100万次查找运算,借助with使用document进行的延长作用域链,因为document下的变量属性比较多,可以测试在多变量作用域链节点下进行查找的性能差异。
实验结果:5次平均耗时558.802ms,而如果删掉with和document,5次平均耗时0.956ms。
当然,这两个实验是在我们假设的极端环境下进行的,结果仅供参考!
关于闭包
1.什么是闭包?
函数对象可以通过作用域链相互关联起来,函数体内的数据(变量和函数声明)都可以保存在函数作用域内,这种特性在计算机科学文献中被称为“闭包”。既函数体内的数据被隐藏于作用于链内,看起来像是函数将数据“包裹”了起来。从技术角度来说,js的函数都是闭包:函数都是对象,都关联到作用域链,函数内数据都被保存在函数作用域内。
2.闭包的几种实现方式
实现方式就是函数A在函数B的内部进行定义了,并且当函数A在执行时,访问了函数B内部的变量对象,那么B就是一个闭包。如下:


如上两图所示,是在chrome浏览器下查看闭包的方法。两种方式的共同点是都有一个外部函数outerFun(),都在外部函数内定义了内部函数innerFun(),内部函数都访问了外部函数的数据。不同的是,第一种方式的innerFun()是在outerFun()内被调用的,既声明和被调用均在同一个执行上下文内。而第二种方式的innerFun()则是在outerFun()外被调用的,既声明和被调用不在同一个执行上下文。第二种方式恰好是js使用闭包常用的特性所在:通过闭包的这种特性,可以在其他执行上下文内访问函数内部数据。
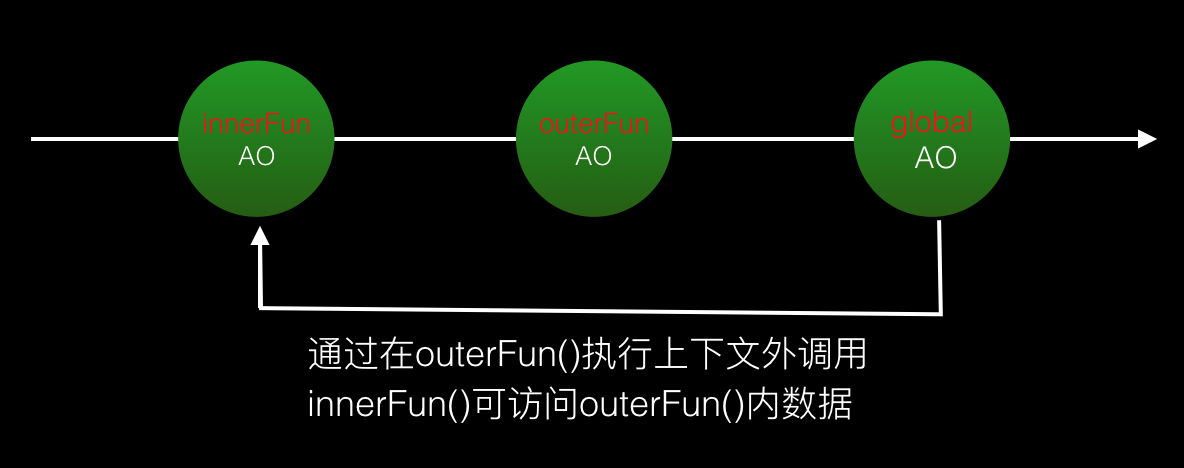
我们更常用的一种方式则是这样的:
//闭包实例
function outerFun () {
var outerV1 = 10
function outerF1 () {
console.log('I am outerF1...')
}
function innerFun () {
var innerV1 = outerV1
outerF1()
}
return innerFun //return回innerFun()内部函数
}
var fn = outerFun() //接到return回的innerFun()函数
fn() //执行接到的内部函数innerFun()此时它的作用域链是这样的:
3.闭包的好处及使用场景
js的垃圾回收机制可以粗略的概括为:如果当前执行上下文执行完毕,且上下文内的数据没有其他引用,则执行上下文pop出call stack,其内数据等待被垃圾回收。而当我们在其他执行上下文通过闭包对执行完的上下文内数据仍然进行引用时,那么被引用的数据则不会被垃圾回收。就像上面代码中的outerV1,放我们在全局上下文通过调用innerFun()仍然访问引用outerV1时,那么outerFun执行完毕后,outerV1也不会被垃圾回收,而是保存在内存中。另外,outerV1看起来像不像一个outerFun的私有内部变量呢?除了innerFun()外,我们无法随意访问outerV1。所以,综上所述,这样闭包的使用情景可以总结为:
(1)进行变量持久化。
(2)使函数对象内有更好的封装性,内部数据私有化。
进行变量持久化方面举个栗子:
我们假设一个需求时写一个函数进行类似id自增或者计算函数被调用的功能,普通青年这样写:
var count = 0
function countFun () {
return count++
}这样写固然实现了功能,但是count被暴露在外,可能被其他代码篡改。这个时候闭包青年就会这样写:
function countFun () {
var count = 0
return function(){
return count++
}
}
var a = countFun()
a()这样count就不会被不小心篡改了,函数调用一次就count加一次1。而如果结合“函数每次被调用都会创建一个新的执行上下文”,这种count的安全性还有如下体现:
function countFun () {
var count = 0
return {
count: function () {
count++
},
reset: function () {
count = 0
},
printCount: function () {
console.log(count)
}
}
}
var a = countFun()
var b = countFun()
a.count()
a.count()
b.count()
b.reset()
a.printCount() //打印:2 因为a.count()被调用了两次
b.printCount() //打印出:0 因为调用了b.reset()以上便是闭包提供的变量持久化和封装性的体现。
4.闭包的注意事项
Étant donné que les variables dans les fermetures ne seront pas récupérées comme les autres variables normales, mais existeront toujours en mémoire, une utilisation intensive des fermetures peut entraîner des problèmes de performances.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Utilisation de la structure typedef en langage C
May 09, 2024 am 10:15 AM
Utilisation de la structure typedef en langage C
May 09, 2024 am 10:15 AM
typedef struct est utilisé en langage C pour créer des alias de type de structure afin de simplifier l'utilisation des structures. Il crée un alias pour un nouveau type de données sur une structure existante en spécifiant l'alias de la structure. Les avantages incluent une lisibilité améliorée, la réutilisation du code et la vérification du type. Remarque : La structure doit être définie avant d'utiliser un alias. L'alias doit être unique dans le programme et valide uniquement dans le périmètre dans lequel il est déclaré.
 Comment résoudre la variable attendue en Java
May 07, 2024 am 02:48 AM
Comment résoudre la variable attendue en Java
May 07, 2024 am 02:48 AM
Les exceptions de valeur attendue des variables en Java peuvent être résolues en : initialisant les variables ; en utilisant des valeurs par défaut ; en utilisant des contrôles et des affectations et en connaissant la portée des variables locales ;
 Avantages et inconvénients des fermetures en js
May 10, 2024 am 04:39 AM
Avantages et inconvénients des fermetures en js
May 10, 2024 am 04:39 AM
Les avantages des fermetures JavaScript incluent le maintien d'une portée variable, l'activation du code modulaire, l'exécution différée et la gestion des événements ; les inconvénients incluent les fuites de mémoire, la complexité accrue, la surcharge de performances et les effets de chaîne de portée.
 Que signifie inclure en C++
May 09, 2024 am 01:45 AM
Que signifie inclure en C++
May 09, 2024 am 01:45 AM
La directive de préprocesseur #include en C++ insère le contenu d'un fichier source externe dans le fichier source actuel, en copiant son contenu à l'emplacement correspondant dans le fichier source actuel. Principalement utilisé pour inclure des fichiers d'en-tête contenant les déclarations nécessaires dans le code, telles que #include <iostream> pour inclure des fonctions d'entrée/sortie standard.
 Comment implémenter la fermeture dans une expression C++ Lambda ?
Jun 01, 2024 pm 05:50 PM
Comment implémenter la fermeture dans une expression C++ Lambda ?
Jun 01, 2024 pm 05:50 PM
Les expressions C++ Lambda prennent en charge les fermetures, qui enregistrent les variables de portée de fonction et les rendent accessibles aux fonctions. La syntaxe est [capture-list](parameters)->return-type{function-body}. capture-list définit les variables à capturer. Vous pouvez utiliser [=] pour capturer toutes les variables locales par valeur, [&] pour capturer toutes les variables locales par référence, ou [variable1, variable2,...] pour capturer des variables spécifiques. Les expressions Lambda ne peuvent accéder qu'aux variables capturées mais ne peuvent pas modifier la valeur d'origine.
 Pointeurs intelligents C++ : une analyse complète de leur cycle de vie
May 09, 2024 am 11:06 AM
Pointeurs intelligents C++ : une analyse complète de leur cycle de vie
May 09, 2024 am 11:06 AM
Cycle de vie des pointeurs intelligents C++ : Création : Les pointeurs intelligents sont créés lors de l'allocation de mémoire. Transfert de propriété : Transférer la propriété via une opération de déménagement. Libération : la mémoire est libérée lorsqu'un pointeur intelligent sort de la portée ou est explicitement libéré. Destruction d'objet : lorsque l'objet pointé est détruit, le pointeur intelligent devient un pointeur invalide.
 Les définitions de fonctions et les appels en C++ peuvent-ils être imbriqués ?
May 06, 2024 pm 06:36 PM
Les définitions de fonctions et les appels en C++ peuvent-ils être imbriqués ?
May 06, 2024 pm 06:36 PM
Peut. C++ autorise les définitions et les appels de fonctions imbriquées. Les fonctions externes peuvent définir des fonctions intégrées et les fonctions internes peuvent être appelées directement dans la portée. Les fonctions imbriquées améliorent l'encapsulation, la réutilisabilité et le contrôle de la portée. Cependant, les fonctions internes ne peuvent pas accéder directement aux variables locales des fonctions externes et le type de valeur de retour doit être cohérent avec la déclaration de la fonction externe. Les fonctions internes ne peuvent pas être auto-récursives.
 Il existe plusieurs situations dans lesquelles cela indique en js
May 06, 2024 pm 02:03 PM
Il existe plusieurs situations dans lesquelles cela indique en js
May 06, 2024 pm 02:03 PM
En JavaScript, les types de pointage de this incluent : 1. Objet global ; 2. Appel de fonction ; 3. Appel de constructeur 4. Gestionnaire d'événements 5. Fonction de flèche (héritant de this). De plus, vous pouvez définir explicitement ce que cela désigne à l'aide des méthodes bind(), call() et apply().
