
 Java
javaDidacticiel
Analyse détaillée du code source du framework de collection Java HashSet et HashMap (photo)
Java
javaDidacticiel
Analyse détaillée du code source du framework de collection Java HashSet et HashMap (photo)
Analyse détaillée du code source du framework de collection Java HashSet et HashMap (photo)

Introduction générale
La raison pour laquelle HashSet et HashMap sont expliqués ensemble est qu'ils ont la même implémentation en Java, et le premier est juste pour le second est une couche d'emballage, ce qui signifie que HashSet a un HashMap (mode adaptateur) à l'intérieur. Par conséquent, cet article se concentrera sur l’analyse du HashMap.
HashMap implémente l'interface Map, permettant de placer des éléments null Sauf que cette classe n'implémente pas la synchronisation, le reste est à peu près le même que <.> et TreeMapHashtable, ce conteneur ne garantit pas l'ordre des éléments. Le conteneur peut re-hacher les éléments selon les besoins, et l'ordre des éléments sera également remanié, donc le même <.>HashMap est itéré à différents moments. L'ordre peut varier. Selon les différentes manières de gérer les conflits, il existe deux façons d'implémenter des tables de hachage, l'une est l'adressage ouvert et l'autre est une liste liée de conflit (chaînage séparé avec des listes
Java HashMap utilise la méthode de liste chaînée de conflit .
Il est facile de voir à partir de la figure ci-dessus que si vous choisissez la fonction de hachage 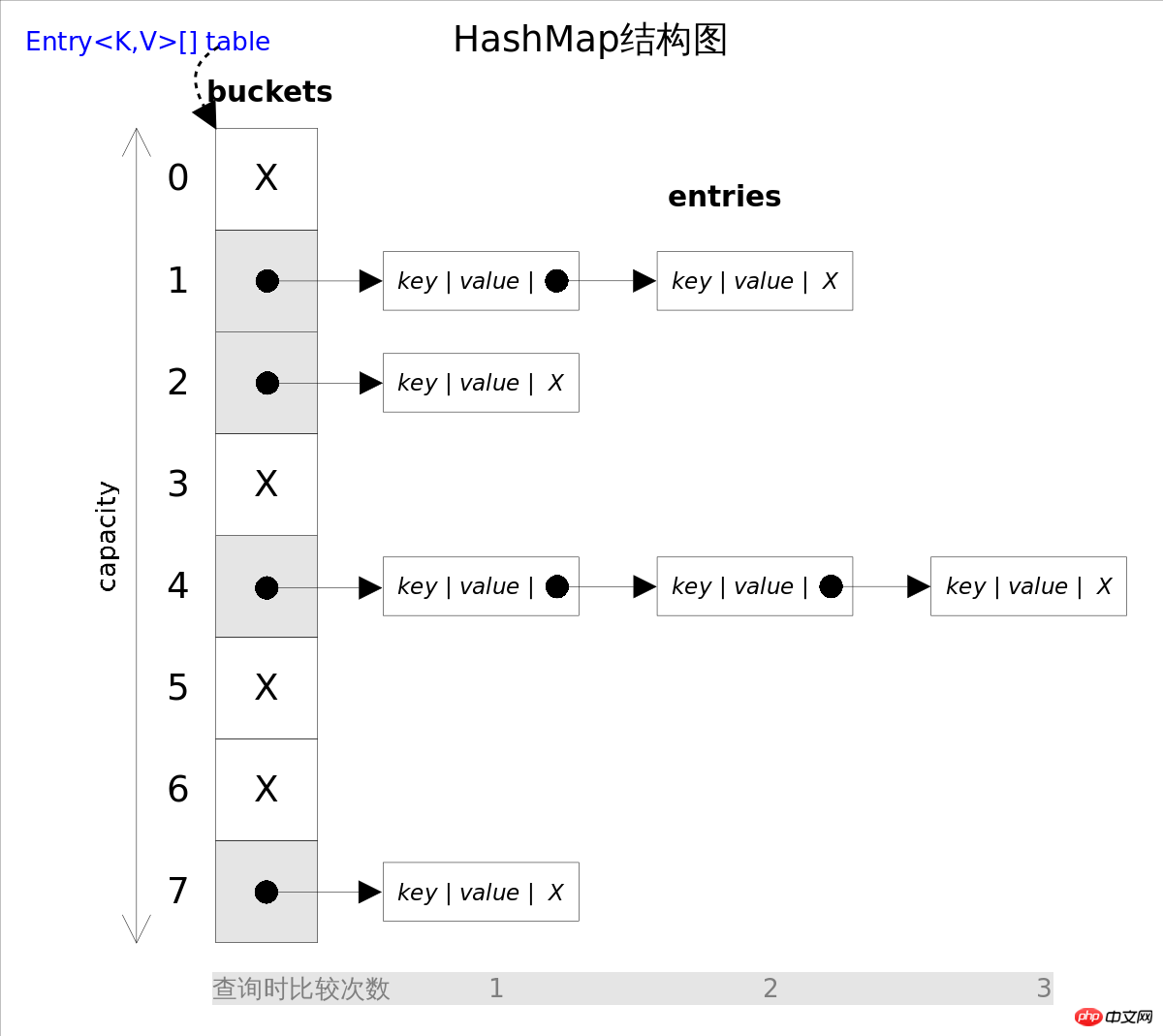
et peuvent être réalisé en temps constant. Mais lors d'une itération sur HashMapput(), vous devez parcourir l'intégralité de la table et la liste chaînée des conflits qui suit. Par conséquent, pour les scénarios avec des itérations fréquentes, il n'est pas approprié de définir la taille initiale de get()HashMap trop grande. a deux paramètres qui peuvent affecter les performances de HashMap
et le facteur de charge est utilisé pour spécifier la valeur critique pour l'expansion automatique. Lorsque le nombre de dépasse , le conteneur sera automatiquement agrandi et rehaché. Pour les scénarios dans lesquels un grand nombre d’éléments sont insérés, la définition d’une capacité initiale plus grande peut réduire le nombre de répétitions. Lorsque tableentry est placé dans capacity*load_factorHashMap
HashSet, deux méthodes nécessitent une attention particulière : et . La méthode hashCode() détermine dans quel equals() l' objet hashCode() sera placé. Lorsque les valeurs de hachage de plusieurs objets sont en conflit, la méthode détermine si ces objets sont "les mêmes un". Objet”. Par conséquent, si vous souhaitez placer un objet personnalisé dans bucket ou equals(), vous avez besoin des méthodes @Override et HashMap. HashSethashCode()Méthode d'analyseequals()
get(<h3 id="Objet">Objet</h3> <a href="http://www.php.cn/%20La%20m%C3%A9thode%20wiki/1051.html" target="_blank">key<p>)</p></a> renvoie le get(<a href="http://www.php.cn/wiki/60.html" target="_blank">Object</a> <a href="http://www.php.cn/wiki/1051.html" target="_blank">key</a>) correspondant en fonction de la valeur key spécifiée. Cette méthode appelle value pour obtenir le getEntry(Object key) correspondant . Puis reviens entry. entry.getValue() est donc le cœur de l’algorithme. L'idée de l'algorithme getEntry() est d'obtenir d'abord l'indice correspondant à via la fonction hash(), puis de parcourir la liste chaînée de conflit dans l'ordre et d'utiliser la méthode bucket pour déterminer si c'est le key.equals(k) que vous recherchez. entry
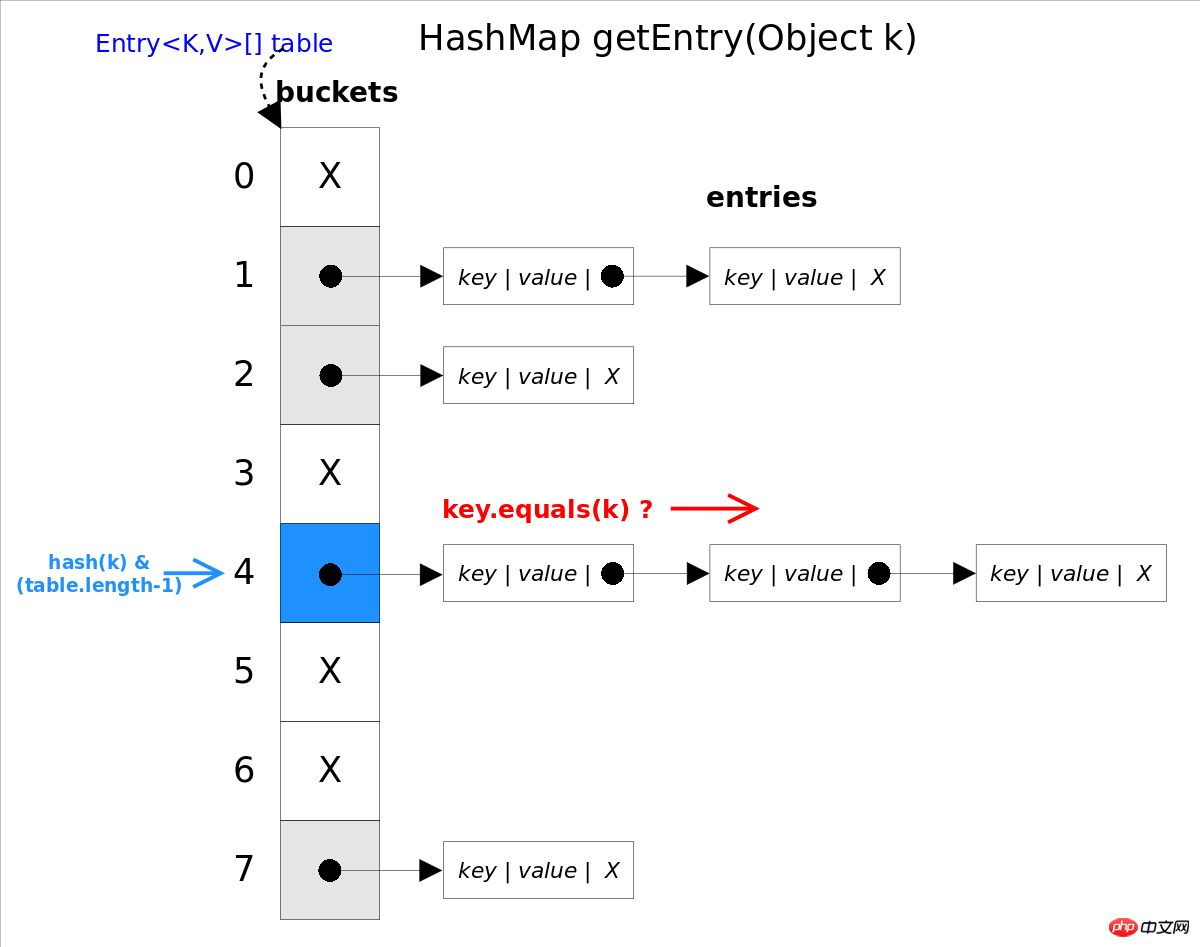
est équivalent à hash(k)&(table.length-1) La raison est que hash(k)%table.lengthHashMap exige que soit un exposant. de 2, donc table.lengthC'est-à-dire que les bits de poids faible du système binaire sont tous 1. Le ET avec table.length-1 effacera tous les bits de poids fort de la valeur de hachage, et le reste est le reste. La méthode hash(k)
//getEntry()方法
final Entry<K,V> getEntry(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[hash&(table.length-1)];//得到冲突链表
e != null; e = e.next) {//依次遍历冲突链表中的每个entry
Object k;
//依据equals()方法判断是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
} ajoute la paire put(K key, V value) spécifiée à key, value. Cette méthode recherchera d'abord map pour voir s'il contient le tuple, s'il est inclus, il retournera directement. Le processus de recherche est similaire à la méthode map s'il n'est pas trouvé, un nouveau getEntry() sera. inséré via la méthode addEntry(int hash, K key, V value, int bucketIndex) 🎜>, la méthode d'insertion est la entry méthode d'insertion de la tête .
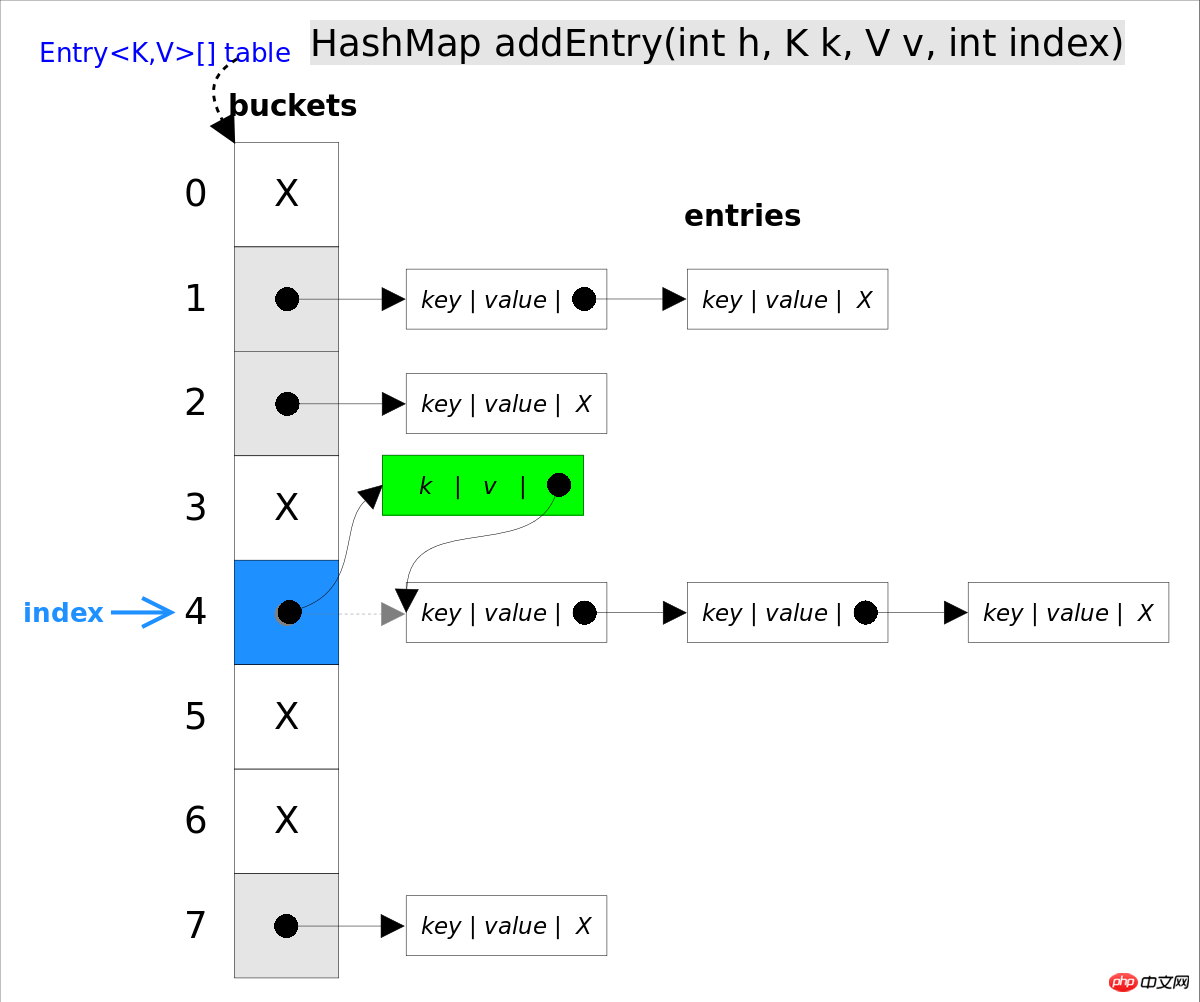
//addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);//hash%table.length
}
//在冲突链表头部插入新的entry
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
} est utilisé pour supprimer le remove(Object key) correspondant à la valeur key La logique spécifique de. cette méthode est implémentée dans entry. La méthode removeEntryForKey(Object key) trouvera d'abord le removeEntryForKey() correspondant à la valeur key, puis supprimera le entry (modifier le pointeur correspondant de la liste chaînée). Le processus de recherche est similaire au processus entry. getEntry()

//removeEntryForKey()
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);//hash&(table.length-1)
Entry<K,V> prev = table[i];//得到冲突链表
Entry<K,V> e = prev;
while (e != null) {//遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {//找到要删除的entry
modCount++; size--;
if (prev == e) table[i] = next;//删除的是冲突链表的第一个entry
else prev.next = next;
return e;
}
prev = e; e = next;
}
return e;
}HashSet
前面已经说过HashSet是对HashMap的简单包装,对HashSet的函数调用都会转换成合适的HashMap方法,因此HashSet的实现非常简单,只有不到300行代码。这里不再赘述。
//HashSet是对HashMap的简单包装
public class HashSet<E>
{
......
private transient HashMap<E,Object> map;//HashSet里面有一个HashMap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
