
 développement back-end
Tutoriel C#.Net
Explication détaillée de la synchronisation des threads dans le multi-threading C# (image et texte)
développement back-end
Tutoriel C#.Net
Explication détaillée de la synchronisation des threads dans le multi-threading C# (image et texte)
Explication détaillée de la synchronisation des threads dans le multi-threading C# (image et texte)

Cet article présente principalement les connaissances pertinentes sur la synchronisation des threads C#. Il a une très bonne valeur de référence. Jetons-y un coup d'œil avec l'éditeur ci-dessous
Le contenu multithread est grossièrement divisé en deux parties. L'une est une opération asynchrone, qui peut être effectuée via un pool de threads dédié, Tâche, Parallèle, PLINQ, etc. Cela implique les threads de travail et les threads IO ; le second est le problème de synchronisation des threads. Ce que j'étudie et explore maintenant est le problème de synchronisation des threads.
En étudiant le contenu de "CLR via C#", j'ai formé une architecture plus claire pour la synchronisation des threads. Ce qui réalise la synchronisation des threads en multi-threads est la structure de synchronisation des threads. Cette structure est divisée en deux catégories, l'une. L’une est une structure primitive et l’autre une structure hybride. Les soi-disant primitives sont les constructions les plus simples utilisées dans le code. La structure de base est divisée en deux catégories, l’une est le mode utilisateur et l’autre le mode noyau. La construction hybride utilise le mode utilisateur et le mode noyau qui utilisent des constructions primitives en interne. Il existe certaines stratégies pour utiliser son mode, car le mode utilisateur et le mode noyau ont leurs propres avantages et inconvénients, et la construction hybride consiste à équilibrer les avantages et les inconvénients de chacun. deux. Conçu pour éviter les inconvénients. Ce qui suit répertorie l'intégralité de l'architecture de synchronisation des threads
primitives
1.1 Mode utilisateur
1.1.1 volatile
1.1.2 Interlock
1.2 Mode noyau
1.2.1 WaitHandle
1.2.2 ManualResetEvent et AutoResetEvent
1.2.3 Sémaphore
1.2. Mutex
Mixte
2.1 Divers Slim
2.2 Moniteur
2.3 MethodImplAttribute et SynchronizationAttribute
2.4 ReaderWriterLock
2.5 Barier (rarement utilisé)
2.6 CoutdownEvent (rarement utilisé)
Commençons par la cause des problèmes de synchronisation des threads lorsqu'il y a du plastique dans la mémoire. Variable A, la valeur qui y est stockée est 2. Lorsque le thread 1 est exécuté, il prendra la valeur de A de la mémoire et la stockera dans le registre CPU, et attribuera la valeur de A à 3. À ce moment , la valeur du thread 1 se trouve être La tranche de temps se termine, puis le processeur alloue la tranche de temps au thread 2. Le thread 2 retire également la valeur de A de la mémoire et la met dans la mémoire. ne remet pas la nouvelle valeur 3 de la variable A dans la mémoire, le thread 2 2 lit toujours l'ancienne valeur (c'est-à-dire les données sales) 2, puis si le thread 2 doit porter des jugements sur la valeur A, des résultats inattendus seront se produire.
Pour résoudre le problème de partage des ressources ci-dessus, diverses méthodes sont souvent utilisées. Ce qui suit présentera un par un
Parlons d'abord du mode utilisateur dans la structure primitive. L'avantage du mode utilisateur est que son exécution est relativement rapide, car elle est coordonnée via une série d'instructions CPU, et le blocage qu'il provoque n'est que Pour une très courte période de blocage, en ce qui concerne le système d'exploitation, ce thread est toujours en cours d'exécution et n'a jamais été bloqué. L'inconvénient est que seul le noyau du système peut empêcher l'exécution d'un tel thread. D'un autre côté, comme le thread tourne au lieu de se bloquer, il occupera également du temps CPU, entraînant une perte de temps CPU.
La première est la structure volatile dans la structure du mode utilisateur primitif De nombreuses théories sur Internet sur cette structure permettent au CPU de lire le champ spécifié (le champ, c'est-à-dire la variable) à partir de la mémoire, et chacun. écrire, c'est écrire en mémoire. Cependant, cela a quelque chose à voir avec l'optimisation du code du compilateur. Regardez d'abord le code suivant
public class StrageClass
{
vo int mFlag = 0;
int mValue = 0;
public void Thread1()
{
mValue = 5;
mFlag = 1;
}
public void Thread2()
{
if (mFlag == 1)
Console.WriteLine(mValue);
}
}Les étudiants qui comprennent les problèmes de synchronisation multi-thread sauront que si deux threads sont utilisés pour exécuter respectivement les deux méthodes ci-dessus, il y a deux résultats :
1. Ne produit rien ;
2. Sorties 5. Cependant, lorsque le compilateur CSC compile en langage IL ou JIT en langage machine, une optimisation du code sera effectuée dans la méthode Thread1, le compilateur pensera que l'attribution de valeurs à deux champs n'a pas d'importance, il ne s'exécutera que dans. Du point de vue d'un seul thread, il ne prend pas du tout en compte la problématique du multi-threading, il peut donc perturber l'ordre d'exécution des deux lignes de code, ce qui fait que mFlag se voit d'abord attribuer la valeur 1. , puis mValue se voit attribuer une valeur de 5, ce qui conduit au troisième. En conséquence, 0 est émis. Malheureusement, je n'ai pas pu tester ce résultat.
La solution à ce phénomène est la construction volatile. L'effet de l'utilisation de cette construction est que chaque fois qu'une opération de lecture est effectuée sur un champ à l'aide de cette construction, l'opération est garantie d'être exécutée en premier dans la séquence de code d'origine. . Ou chaque fois qu'une opération d'écriture est effectuée sur un champ à l'aide de cette construction, l'opération est garantie d'être exécutée en dernier dans la séquence de code d'origine.
Il existe actuellement trois constructions qui implémentent volatile. L'une est les deux méthodes statiques de Thread, VolatileRead et VolatileWrite. L'analyse sur MSND est la suivante
Thread lit les valeurs des champs. . Cette valeur est la valeur la plus récente écrite par l'un des processeurs de l'ordinateur, quel que soit le nombre de processeurs ou l'état du cache du processeur.
Thread.VolatileWrite Écrit immédiatement une valeur dans un champ, rendant la valeur visible à tous les processeurs de l'ordinateur.
在多处理器系统上, VolatileRead 获得由任何处理器写入的内存位置的最新值。 这可能需要刷新处理器缓存;VolatileWrite 确保写入内存位置的值立即可见的所有处理器。 这可能需要刷新处理器缓存。
即使在单处理器系统上, VolatileRead 和 VolatileWrite 确保值为读取或写入内存,并不缓存 (例如,在处理器寄存器中)。 因此,您可以使用它们可以由另一个线程,或通过硬件更新的字段对访问进行同步。
从上面的文字看不出他和代码优化有任何关联,那接着往下看。
volatile关键字则是volatile构造的另外一种实现方式,它是VolatileRead和VolatileWrite的简化版,使用 volatile 修饰符对字段可以保证对该字段的所有访问都使用 VolatileRead 或 VolatileWrite。MSDN中对volatile关键字的说明是
volatile 关键字指示一个字段可以由多个同时执行的线程修改。 声明为 volatile 的字段不受编译器优化(假定由单个线程访问)的限制。 这样可以确保该字段在任何时间呈现的都是最新的值。
从这里可以看出跟代码优化有关系了。而纵观上面的介绍得出两个结论:
1.使用了volatile构造的字段读写都是直接对内存操作,不涉及CPU寄存器,使得所有线程对它的读写都是同步,不存在脏读了。读操作是原子的,写操作也是原子的。
2.使用了volatile构造修饰(或访问)字段,它会严格按照代码编写的顺序执行,读操作将会在最早执行,写操作将会最迟执行。
最后一个volatile构造是在.NET Framework中新增的,里面包含的方法都是Read和Write,它实际上就相当于Thread的VolatileRead 和VolatileWrite 。这需要拿源码来说明了,随便拿一个Volatile的Read方法来看
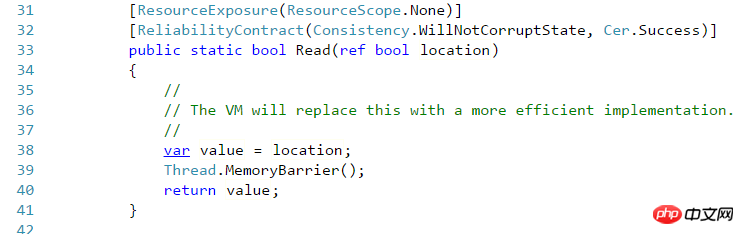
而再看看Thraed的VolatileRead方法

另一个用户模式构造是Interlocked,这个构造是保证读和写都是在原子操作里面,这是与上面volatile最大的区别,volatile只能确保单纯的读或者单纯的写。
为何Interlocked是这样,看一下Interlocaked的方法就知道了
Add(ref int,int)// 调用ExternAdd 外部方法 CompareExchange(ref Int32,Int32,Int32)//1与3是否相等,相等则替换2,返回1的原始值 Decrement(ref Int32)//递减并返回 调用add Exchange(ref Int32,Int32)//将2设置到1并返回 Increment(ref Int32)//自增 调用add
就随便拿其中一个方法Add(ref int,int)来说(Increment和Decrement这两个方法实际上内部调用了Add方法),它会先读到第一个参数的值,在与第二个参数求和后,把结果写到给第一参数中。首先这整个过程是一个原子操作,在这个操作里面既包含了读,也包含了写。至于如何保证这个操作的原子性,估计需要查看Rotor源码才行。在代码优化方面来说,它确保了所有写操作都在Interlocked之前去执行,这保证了Interlocked里面用到的值是最新的;而任何变量的读取都在Interlocked之后读取,这保证了后面用到的值都是最新更改过的。
CompareExchange方法相当重要,虽然Interlocked提供的方法甚少,但基于这个可以扩展出其他更多方法,下面就是个例子,求出两个值的最大值,直接抄了Jeffrey的源码

查看上面代码,在进入循环之前先声明每次循环开始时target的值,在求出最值之后,核对一下target的值是否有变化,如果有变化则需要再记录新值,按照新值来再求一次最值,直到target不变为止,这就满足了Interlocked中所说的,写都在Interlocked之前发生,Interlocked往后就能读到最新的值。
基元内核模式
Le mode noyau s'appuie sur l'objet du noyau du système d'exploitation pour gérer les problèmes de synchronisation des threads. Parlons d’abord de ses inconvénients, sa vitesse sera relativement lente. Il y a deux raisons. L'une est qu'il est implémenté par l'objet noyau du système d'exploitation et nécessite une coordination au sein du système d'exploitation. L'autre raison est que les objets noyau sont tous des objets non gérés après avoir compris AppDo Après main. saura, si l'objet accédé ne se trouve pas dans l'AppDomain actuel, il sera soit marshalé par valeur, soit marshalé par référence . Il a été observé que cette partie des ressources non gérées est marshalée par référence, ce qui aura un impact sur les performances. En combinant les deux points ci-dessus, nous pouvons obtenir les inconvénients du mode noyau. Mais cela présente également des avantages : 1. Le thread ne "tournera" pas mais se bloquera en attendant des ressources. Cela économise du temps CPU et une valeur de délai d'attente peut être définie pour ce blocage. 2. La synchronisation des threads Windows et des threads CLR peut être réalisée, et les threads de différents processus peuvent également être synchronisés (le premier n'a pas été expérimenté, mais pour le second, on sait qu'il existe des ressources de valeur limite dans les sémaphores). 3. Des paramètres de sécurité peuvent être appliqués pour interdire l’accès aux comptes autorisés (je ne sais pas ce qui se passe).
La classe de base pour tous les objets en mode noyau est WaitHandle. Toutes les hiérarchies de classes en mode noyau sont les suivantes >
AutoResetEvent
ManualResetEvent
Semaphore
MutexWaitHandle hérite de MarshalByRefObject, qui rassemble les objets non gérés par référence. WaitHandle contient principalement diverses méthodes Wait Si la méthode Wait est appelée, elle sera bloquée avant de recevoir le signal. WaitOne attend un signal, WaitAny(WaitHandle[] waitHandles) reçoit le signal de tous les waitHandles et WaitAll(WaitHandle[] waitHandles) attend le signal de tous les waitHandles. Il existe une version de ces méthodes qui permet de définir un délai d'attente. D'autres constructions en mode noyau ont des méthodes Wait similaires.
EventWaitHandle maintient une valeur booléenne en interne, et la méthode Wait bloquera le thread lorsque la valeur booléenne est fausse, et le thread ne sera pas libéré tant que la valeur booléenne n'est pas vraie. Les méthodes de manipulation de cette valeur booléenne incluent Set() et Reset(). La première définit la valeur booléenne sur true ; la seconde la définit sur false ; Cela équivaut à un commutateur Après avoir appelé Reset, le thread exécute Wait et est mis en pause, et ne reprend que Set. Il comporte deux sous-classes, qui sont utilisées de manière similaire. La différence est que AutoResetEvent appelle automatiquement Reset après avoir appelé Set, de sorte que le commutateur revienne immédiatement à l'état fermé, tandis que ManualResetEvent nécessite un appel manuel à Set pour fermer le commutateur. Cela produit un effet. Généralement, AutoResetEvent permet à un thread de passer à chaque fois qu'il est libéré ; tandis que ManualResetEvent peut permettre à plusieurs threads de passer avant d'appeler manuellement Reset. Semaphore maintient un entier en interne lors de la construction d'un objet Semaphore, le sémaphore maximum et la valeur initiale du sémaphore seront spécifiés à chaque fois que WaitOne est appelé, le sémaphore sera augmenté de 1. Lorsqu'il est ajouté au. valeur maximale, le thread sera bloqué. Lorsque Release est appelé, un ou plusieurs sémaphores seront libérés. À ce moment, le ou les threads bloqués seront libérés. Cela correspond au problème des producteurs et des consommateurs. Lorsque le producteur continue d'ajouter des produits à la file d'attente , il attendra que la file d'attente soit pleine, ce qui équivaut à un sémaphore plein. le producteur sera bloqué. Lorsque le consommateur consomme un produit, Release libérera un espace dans la file d'attente du produit. À ce moment, le producteur qui n'a pas d'espace pour stocker le produit peut commencer à travailler pour stocker le produit dans la file d'attente des produits.
Les internes et les règles de Mutex sont légèrement plus compliqués que les deux précédents. Tout d'abord, la similitude avec les précédents est que le thread actuel sera bloqué via WaitOne, et le blocage du thread sera. publié via ReleaseMutex. La différence est que WaitOne permet au premier thread appelant de passer, et les autres threads suivants seront bloqués lors de l'appel de WaitOne. Le thread qui passe WaitOne peut appeler WaitOne plusieurs fois, mais il doit appeler ReleaseMutex le même nombre de fois pour être libéré, sinon il will Le nombre inégal de fois entraîne le blocage des autres threads. Par rapport aux constructions précédentes, cette construction a deux concepts : la propriété du thread et la récursion. Cela ne peut pas être réalisé simplement en s'appuyant sur les constructions précédentes, sauf pour une encapsulation supplémentaire.
Construction MixteLa structure primitive ci-dessus utilise la méthode d'implémentation la plus simple. Le mode utilisateur est plus rapide que le mode utilisateur, mais cela entraînera une perte de temps CPU ; le mode noyau résout ce problème, mais entraînera des pertes de performances, chacun a des avantages et des inconvénients. et la structure hybride combine les avantages des deux. Elle utilisera le mode utilisateur au moment opportun via certaines stratégies en interne, et utilisera le mode noyau dans une autre situation. Mais ces couches de jugements entraînent une surcharge de mémoire. Il n'y a pas de structure parfaite dans la synchronisation multithread. Chaque structure présente des avantages et des inconvénients, et son existence est significative. Combinée à des scénarios d'application spécifiques, la structure optimale sera disponible. Cela dépend simplement de notre capacité à peser le pour et le contre en fonction de scénarios spécifiques.
Diverses classes suffixées Slim. Dans l'espace de noms System.Threading , vous pouvez voir plusieurs classes se terminant par le suffixe Slim : ManualResetEventSlim, SemaphoreSlim, ReaderWriterLockSlim. A l'exception de la dernière, les deux autres ont la même structure en mode noyau primitif, mais ces trois classes sont des versions simplifiées des structures originales, surtout les deux premières. Elles sont utilisées de la même manière que les originales, mais essayez. pour éviter d'utiliser les objets du noyau du système d'exploitation et obtenir un effet léger. Par exemple, la construction du noyau ManualResetEvent est utilisée dans SemaphoreSlim, mais cette construction est initialisée par retard et n'est utilisée que si cela est nécessaire. Quant à ReaderWriterLockSlim, nous le présenterons plus tard.
Surveiller et verrouiller, le mot-clé lock est le moyen le plus connu pour réaliser une synchronisation multi-thread, alors commençons par un morceau de code

Cette méthode est assez simple et n'a aucune signification pratique. Il s'agit simplement de voir dans quoi le compilateur compile ce code. En regardant l'IL comme suit

remarquez que l'IL. le code apparaît Le bloc d'instructions try...finally, les méthodes Monitor.Enter et Monotor.Exit sont ajoutées. Modifiez ensuite le code et compilez-le à nouveau pour voir le code IL

IL
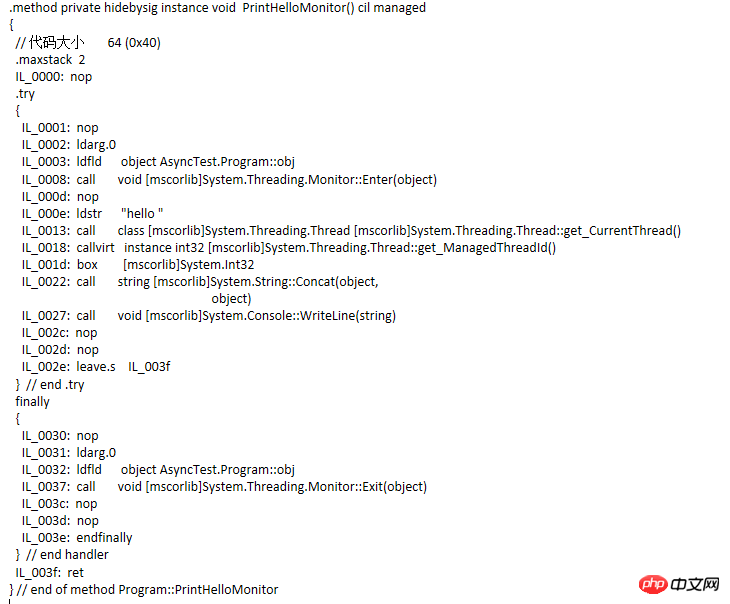
comparaison de code Similaire, mais pas équivalent. En fait, le code équivalent au bloc d'instruction de verrouillage est le suivant

Donc, puisque le verrouillage appelle essentiellement Monitor, comment Monitor passe-t-il un The. l'objet est verrouillé, puis la synchronisation des threads est réalisée. Il s'avère que chaque objet du tas géré a deux membres fixes, l'un pointant vers le pointeur du type d'objet et l'autre pointant vers un bloc de synchronisation de thread index . Cet index pointe vers un élément d'un bloc synchronisé tableau . Monitor s'appuie sur ce bloc synchronisé pour verrouiller le thread. Selon Jeffrey (l'auteur de CLR via C#), il y a trois champs dans le bloc de synchronisation, l'ID du thread de propriété, le nombre de threads en attente et le nombre de récursions. Cependant, j'ai appris grâce à un autre lot d'articles que les membres du bloc de synchronisation des threads ne sont pas seulement ces quelques étudiants intéressés peuvent lire les deux articles « Révéler l'index du bloc de synchronisation ». Lorsque le moniteur doit verrouiller un objet obj, il vérifiera si l'index du bloc de synchronisation de obj est un index du tableau. S'il est -1, il trouvera un bloc de synchronisation libre du tableau à lui associer. En même temps, l'ID de thread de propriété du bloc de synchronisation enregistre l'ID du thread actuel ; lorsqu'un thread appelle à nouveau le moniteur, il vérifiera si l'ID de propriété du bloc de synchronisation correspond à l'ID de thread actuel s'il peut correspondre, laissez-le passer. Dans la récursion, ajoutez 1 au nombre de fois. Si le thread ne peut pas correspondre, jetez le thread dans une file d'attente prête (cette file d'attente existe réellement dans le bloc de synchronisation) et bloquez-le. Ce bloc de synchronisation vérifiera le numéro ; de récursions lors de l'appel à Exit pour garantir Une fois la récursion terminée, l'ID du thread de propriété est effacé. Nous savons s'il y a des threads en attente par le nombre de threads en attente. Si c'est le cas, les threads sont retirés de la file d'attente et libérés. Sinon, l'association avec le bloc de synchronisation est libérée et le bloc de synchronisation attend d'être utilisé par le suivant. objet verrouillé.
Il existe également deux méthodes Wait et Pulse in Monitor. Le premier peut amener le thread qui a obtenu le verrou à libérer brièvement le verrou, et le thread actuel sera bloqué et placé dans la file d'attente. Jusqu'à ce que d'autres threads appellent la méthode Pulse, le thread sera placé de la file d'attente dans la file d'attente prête lorsque le verrou sera libéré la prochaine fois, il y aura une chance d'acquérir à nouveau le verrou, cela dépend de la situation. dans la file d'attente.
ReaderWriterLock est un mot-clé de verrouillage traditionnel (équivalent à Enter et Exit de Monitor). Son verrouillage sur les ressources partagées est un verrouillage totalement exclusif. Une fois la ressource verrouillée, les autres ressources ne peuvent pas y accéder.
而ReaderWriterLock对互斥资源的加的锁分读锁与写锁,类似于数据库中提到的共享锁和排他锁。大致情况是加了读锁的资源允许多个线程对其访问,而加了写锁的资源只有一个线程可以对其访问。两种加了不同缩的线程都不能同时访问资源,而严格来说,加了读锁的线程只要在同一个队列中的都能访问资源,而不同队列的则不能访问;加了写锁的资源只能在一个队列中,而写锁队列中只有一个线程能访问资源。区分读锁的线程是否在于统一个队列中的判断标准是,本次加读锁的线程与上次加读锁的线程这个时间段中,有否别的线程加了写锁,没没别的线程加写锁,则这两个线程都在同一个读锁队列中。
ReaderWriterLockSlim和ReaderWriterLock类似,是后者的升级版,出现在.NET Framework3.5,据说是优化了递归和简化了操作。在此递归策略我尚未深究过。目前大概列举一下它们通常用的方法
ReaderWriterLock常用的方法
Acqurie或Release ReaderLock或WriteLock 的排列组合
UpGradeToWriteLock/DownGradeFromWriteLock 用于在读锁中升级到写锁。当然在这个升级的过程中也涉及到线程从读锁队列切换到写锁队列中,因此需要等待。
ReleaseLock/RestoreLock 释放所有锁和恢复锁状态
ReaderWriterLock实现IDispose接口,其方法则是以下模式
TryEnter/Enter/Exit ReadLock/WriteLock/UpGradeableReadLock
CoutdownEvent比较少用的混合构造,这个跟Semaphore相反,体现在Semaphore是在内部计数(也就是信号量)达到最大值的时候让线程阻塞,而CountdownEvent是在内部计数达到0的时候才让线程阻塞。其方法有
AddCount //计数递增; Signal //计数递减; Reset //计数重设为指定或初始; Wait //当且仅当计数为0才不阻塞,否则就阻塞。
Barrier也是一个比较少用的混合构造,用于处理多线程在分步骤的操作中协作问题。它内部维护着一个计数,该计数代表这次协作的参与者数量,当不同的线程调用SignalAndWait的时候会给这个计数加1并且把调用的线程阻塞,直到计数达到最大值的时候,才会释放所有被阻塞的线程。假设还是不明白的话就看一下MSND上面的示例代码
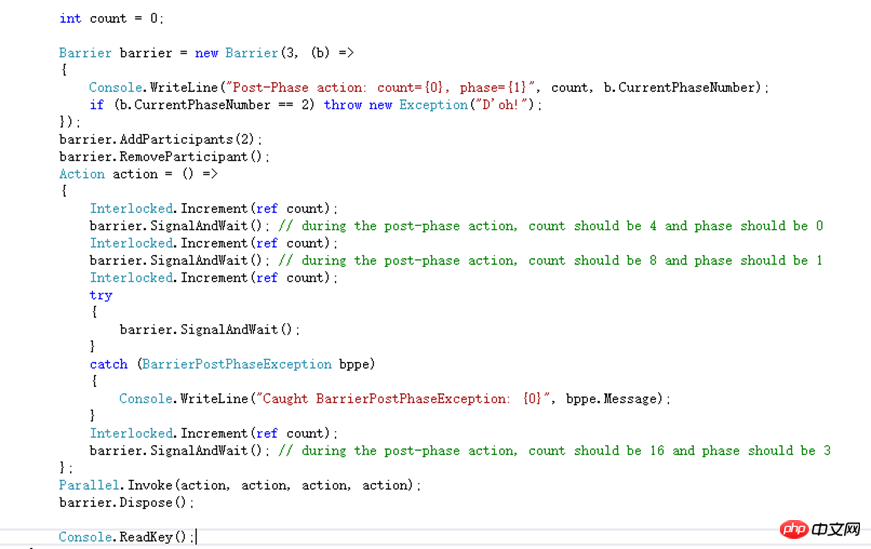
这里给Barrier初始化的参与者数量是3,同时每完成一个步骤的时候会调用委托,该方法是输出count的值步骤索引。参与者数量后来增加了两个又减少了一个。每个参与者的操作都是相同,给count进行原子自增,自增完则调用SgnalAndWait告知Barrier当前步骤已完成并等待下一个步骤的开始。但是第三次由于回调方法里抛出了一个异常,每个参与者在调用SignalAndWait的时候都会抛出一个异常。通过Parallel开始了一个并行操作。假设并行开的作业数跟Barrier参与者数量不一样就会导致在SignalAndWait会有非预期的情况出现。
接下来说两个Attribute,这个估计不算是同步构造,但是也能在线程同步中发挥作用
MethodImplAttribute这个Attribute适用于方法的,当给定的参数是MethodImplOptions.Synchronized,它会对整个方法的方法体进行加锁,凡是调用这个方法的线程在没有获得锁的时候就会被阻塞,直到拥有锁的线程释放了才将其唤醒。对静态方法而言它就相当于把该类的类型对象给锁了,即lock(typeof(ClassType));对于实例方法他就相当于把该对象的实例给锁了,即lock(this)。最开始对它内部调用了lock这个结论存在猜疑,于是用IL编译了一下,发现方法体的代码没啥异样,查看了一些源码也好无头绪,后来发现它的IL方法头跟普通的方法有区别,多了一个synchronized
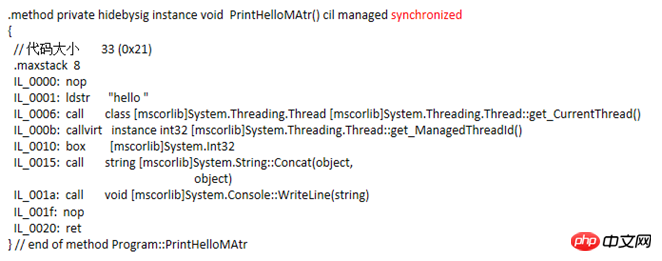
于是网上找各种资料,最后发现"junchu25"的博客[1][2]里提到用WinDbg来查看JIT生成的代码。
调用Attribute的
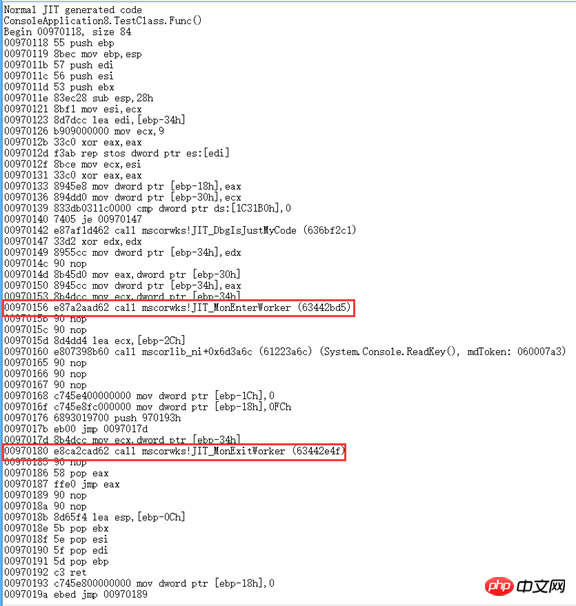
调用lock的
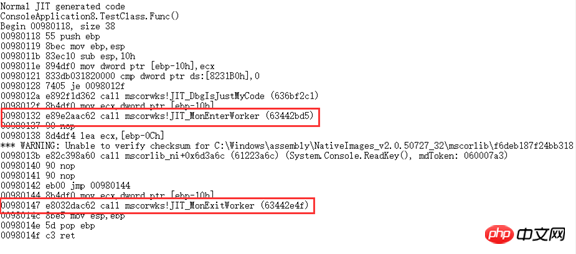
对于用这个Attribute实现的线程同步连Jeffrey都不推荐使用。
System.Runtime.Remoting.Contexts.SynchronizationAttribute est applicable aux classes. Ajoutez cet attribut à la définition de classe et héritez de la classe de ContextBoundOject. Il ajoutera le même verrou à toutes les méthodes de la classe. Compare MethodImplAttribute a une portée plus large. . Lorsqu'un thread appelle une méthode de cette classe, si le verrou n'est pas obtenu, le thread sera bloqué. Il y a un dicton qui appelle essentiellement lock.Il est encore plus difficile de vérifier cette affirmation. Il existe très peu de ressources nationales, qui impliquent également AppDomain et le contexte de thread. Le noyau final est implémenté par la classe SynchronizedServerContextSink. AppDomain devrait être présenté dans un article séparé. Mais je veux en parler un peu ici. Je pensais qu'il y avait des piles de threads et de la mémoire tas dans la mémoire, et ce n'est qu'une division très basique. La mémoire tas est également divisée en plusieurs domaines d'application, et il y en a. au moins un contexte dans chaque AppDomain. Chaque objet appartiendra à un contexte au sein d'un AppDomain. Les objets des AppDomains ne sont pas accessibles directement. Ils doivent être marshalés par valeur (équivalent à une copie approfondie d'un objet dans l'AppDomain appelant) ou marshalés par référence. Pour le marshaling par référence, la classe doit hériter de MarshalByRefObject. Lorsqu'il appelle un objet qui hérite de cette classe, il n'appelle pas la classe elle-même, mais l'appelle via un proxy. Ensuite, un marshaling inter-contexte par opération de valeur est également requis. Un objet généralement construit se trouve dans le contexte par défaut sous l'AppDomain par défaut du processus, et l'instance d'une classe qui utilise l'attribut SynchronizationAttribute appartient à un autre contexte. Les classes qui héritent de la classe de base ContextBoundObject accèdent également aux objets à travers les contextes via l'utilisation d'un proxy pour accéder au. Le marshaling d’objet par référence n’accède pas à l’objet lui-même. Quant à savoir s'il faut accéder à l'objet dans plusieurs contextes, vous pouvez le juger via la méthode RemotingServices.IsObjectOutOfContext(obj). SynchronizedServerContextSink est une classe interne de mscorlib. Lorsqu'un thread appelle un objet inter-contexte, l'appel sera encapsulé dans un objet WorkItem par SynchronizedServerContextSink, qui est également une classe interne dans les requêtes mscorlib. SynchronizationAttribute détermine la demande d'exécution actuelle en fonction de l'existence ou non de plusieurs demandes d'exécution WorkItem. Le WorkItem traité sera-t-il exécuté immédiatement ou placé dans une file d'attente WorkItem premier entré, premier sorti pour être exécuté dans l'ordre ? Cette file d'attente est membre de SynchronizationAttribute lorsque les membres de la file d'attente entrent et sortent de la file d'attente, ou lorsque l'attribut détermine si. pour exécuter le WorkItem immédiatement, un verrou doit être obtenu, l'objet verrouillé est également la file d'attente de ce WorkItem. Cela implique l'interaction de plusieurs classes. Je ne l'ai pas encore complètement compris. Il peut y avoir des erreurs dans le processus ci-dessus, j'en ajouterai plus après une analyse claire. Cependant, la synchronisation des threads obtenue via cet attribut n'est pas recommandée sur la base d'une forte intuition, principalement en raison de pertes de performances et de la plage de verrouillage relativement large.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Active Directory avec C#
Sep 03, 2024 pm 03:33 PM
Active Directory avec C#
Sep 03, 2024 pm 03:33 PM
Guide d'Active Directory avec C#. Nous discutons ici de l'introduction et du fonctionnement d'Active Directory en C# ainsi que de la syntaxe et de l'exemple.
 Sérialisation C#
Sep 03, 2024 pm 03:30 PM
Sérialisation C#
Sep 03, 2024 pm 03:30 PM
Guide de sérialisation C#. Nous discutons ici de l'introduction, des étapes de l'objet de sérialisation C#, du fonctionnement et de l'exemple respectivement.
 Générateur de nombres aléatoires en C#
Sep 03, 2024 pm 03:34 PM
Générateur de nombres aléatoires en C#
Sep 03, 2024 pm 03:34 PM
Guide du générateur de nombres aléatoires en C#. Nous discutons ici du fonctionnement du générateur de nombres aléatoires, du concept de nombres pseudo-aléatoires et sécurisés.
 Vue Grille de données C#
Sep 03, 2024 pm 03:32 PM
Vue Grille de données C#
Sep 03, 2024 pm 03:32 PM
Guide de la vue Grille de données C#. Nous discutons ici des exemples de la façon dont une vue de grille de données peut être chargée et exportée à partir de la base de données SQL ou d'un fichier Excel.
 Modèles en C#
Sep 03, 2024 pm 03:33 PM
Modèles en C#
Sep 03, 2024 pm 03:33 PM
Guide des modèles en C#. Nous discutons ici de l'introduction et des 3 principaux types de modèles en C# ainsi que de ses exemples et de l'implémentation du code.
 Nombres premiers en C#
Sep 03, 2024 pm 03:35 PM
Nombres premiers en C#
Sep 03, 2024 pm 03:35 PM
Guide des nombres premiers en C#. Nous discutons ici de l'introduction et des exemples de nombres premiers en c# ainsi que de l'implémentation du code.
 Factorielle en C#
Sep 03, 2024 pm 03:34 PM
Factorielle en C#
Sep 03, 2024 pm 03:34 PM
Guide de Factorial en C#. Nous discutons ici de l'introduction de factorial en c# ainsi que de différents exemples et de l'implémentation du code.
 La différence entre le multithreading et le C # asynchrone
Apr 03, 2025 pm 02:57 PM
La différence entre le multithreading et le C # asynchrone
Apr 03, 2025 pm 02:57 PM
La différence entre le multithreading et l'asynchrone est que le multithreading exécute plusieurs threads en même temps, tandis que les opérations effectuent de manière asynchrone sans bloquer le thread actuel. Le multithreading est utilisé pour les tâches à forte intensité de calcul, tandis que de manière asynchrone est utilisée pour l'interaction utilisateur. L'avantage du multi-threading est d'améliorer les performances informatiques, tandis que l'avantage des asynchrones est de ne pas bloquer les threads d'interface utilisateur. Le choix du multithreading ou asynchrone dépend de la nature de la tâche: les tâches à forte intensité de calcul utilisent le multithreading, les tâches qui interagissent avec les ressources externes et doivent maintenir la réactivité de l'interface utilisateur à utiliser asynchrone.
