

J'ai récemment travaillé sur des projets de type commande et utilisé des transactions. Notre base de données utilise MySql et le moteur de stockage utilise innoDB, qui prend en charge les transactions. Dans cet article, jetons un coup d’œil aux connaissances liées aux affaires.
Pourquoi avons-nous besoin d'affaires ?
Les transactions sont largement utilisées dans divers scénarios tels que les systèmes de commande et les systèmes bancaires. S'il existe le scénario suivant : L'utilisateur A et l'utilisateur B sont les déposants de la banque. Maintenant, A veut transférer 500 yuans à B. Ensuite, vous devez faire les choses suivantes :
1. Vérifiez le solde du compte de A >500 yuans
2. Déduisez 500 yuans du compte de A
3. Ajout de 500 yuans
Suite au processus normal, 500 yuans ont été déduits du compte A et 500 yuans ont été ajoutés au compte B. Tout le monde était content. Que se passe-t-il si le système tombe en panne après que l'argent ait été déduit du compte A ? A a perdu 500 en vain, et B n'a pas reçu les 500 qui étaient censés lui appartenir. Dans le cas ci-dessus, il y a une condition préalable cachée : A déduisant de l'argent et B ajoutant de l'argent, soit réussissent en même temps, soit échouent en même temps. C'est ce dont les entreprises ont besoin.
Quelle est la transaction ?
Au lieu de définir une transaction, il vaut mieux parler des caractéristiques de la transaction. Comme nous le savons tous, les transactions doivent répondre aux quatre propriétés ACID.
1. Une atomicité (atomicité). L'exécution d'une transaction est considérée comme une unité minimale indivisible. Les opérations de la transaction doivent être exécutées avec succès ou annulées si elles échouent. Seule une partie d'entre elles ne peut pas être exécutée.
2. Cohérence C(cohérence). L'exécution d'une transaction ne doit pas violer les contraintes d'intégrité de la base de données. Si le système plante après l'exécution de la deuxième opération dans l'exemple ci-dessus, il est garanti que l'argent total de A et B ne changera pas.
3. I(isolement) isolement. D'une manière générale, le comportement des transactions ne devrait pas s'influencer mutuellement. Cependant, dans les situations réelles, le degré d’interaction entre les transactions est affecté par le niveau d’isolement. Les détails seront donnés plus loin dans l'article.
4. D(durabilité) persistance. Une fois la transaction validée, elle doit être conservée sur le disque. Même si le système tombe en panne, les données soumises ne doivent pas être perdues.
Quatre niveaux d'isolement des transactions
Comme mentionné dans l'article précédent, l'isolement des transactions est affecté par le niveau d'isolement. Alors, quel est le niveau d’isolement d’une transaction ? Le niveau d'isolement d'une transaction peut être considéré comme le degré d'« égoïsme » d'une transaction, qui définit la visibilité entre les transactions. Les niveaux d'isolement sont divisés selon les types suivants :
1.READ UNCOMMITTED (lecture non validée). Sous le niveau d'isolement RU, les modifications apportées aux données par la transaction A sont visibles par la transaction B même si elles ne sont pas validées. Ce problème est appelé lecture sale. Il s'agit d'un niveau d'isolation avec un degré d'isolation inférieur. Il peut poser de nombreux problèmes dans les applications pratiques, c'est pourquoi il n'est généralement pas utilisé couramment.
2.LIRE ENGAGÉ. Sous le niveau d'isolement de RC, il n'y aura pas de problème de lecture sale. Les modifications apportées par la transaction A aux données seront visibles par la transaction B après la soumission. Par exemple, lorsque la transaction B est ouverte, les données 1 sont lues, puis la transaction A est ouverte, les données sont remplacées par 2, soumises et B lit. les données à nouveau, il lira les dernières données 2. Sous le niveau d'isolement de RC, le problème des lectures non répétables se produira. Ce niveau d'isolement est le niveau d'isolement par défaut pour de nombreuses bases de données.
3.REPEATABLE READ (lecture répétable). Sous le niveau d'isolement de RR, il n'y aura aucun problème de lecture non reproductible. Une fois les modifications apportées aux données par la transaction A soumises, elles ne seront plus visibles pour les transactions démarrées avant la transaction A. Par exemple, lorsque la transaction B est ouverte, les données 1 sont lues. Ensuite, la transaction A est ouverte, modifie les données en 2 et valide B lit à nouveau les données et ne peut toujours lire que 1. Sous le niveau d'isolement de RR, le problème de la lecture fantôme se produira. La signification de la lecture fantôme est que lorsqu'une transaction lit une valeur dans une certaine plage et qu'une autre transaction insère un nouvel enregistrement dans cette plage, la transaction précédente lit à nouveau la valeur dans cette plage et lira les données nouvellement insérées. Le niveau d'isolement par défaut de MySQL est RR, mais le verrouillage des écarts du moteur innoDB de MySQL résout avec succès le problème des lectures fantômes.
4.SERIALIZABLE (sérialisable). Sérialisable est le niveau d'isolement le plus élevé. Ce niveau d'isolement oblige tout à être exécuté en série. À ce niveau d'isolement, chaque ligne de données lues est verrouillée, ce qui entraînera un grand nombre de problèmes d'acquisition de verrous et des performances médiocres.
Pour vous aider à comprendre les quatre niveaux d'isolement, voici un exemple. Comme le montre la figure 1, la transaction A et la transaction B sont ouvertes l'une après l'autre et les données 1 sont mises à jour plusieurs fois. Quatre méchants commencent des transactions à des moments différents. Quelles valeurs peuvent-ils voir dans les données 1 ? 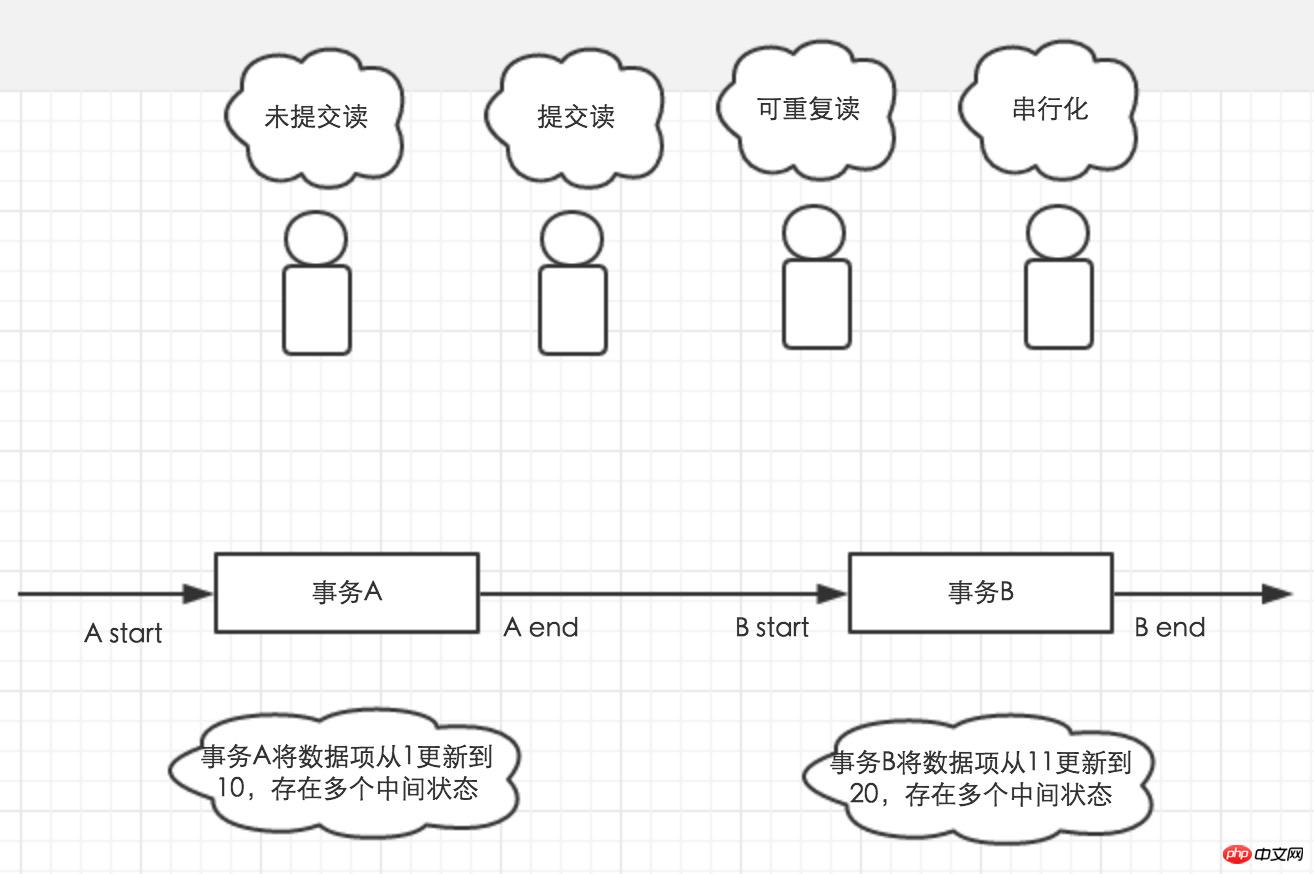
Photo 1
Le premier méchant peut lire entre 1 et 20. Parce que sous le niveau d'isolement de lecture non validée, les modifications apportées aux données par d'autres transactions sont également visibles pour la transaction en cours. Le deuxième méchant peut lire 1, 10 et 20. Il ne peut lire que les données soumises par d'autres transactions. Les données lues par le troisième méchant dépendent du moment où sa propre transaction est lancée. La valeur lue au démarrage de la transaction sera la valeur lue avant la validation de la transaction. Le quatrième méchant ne peut lire les données que lorsqu'elles sont ouvertes entre A fin et B start. Cependant, les données ne peuvent pas être lues lors de l'exécution de la transaction A et de la transaction B. Étant donné que le quatrième méchant doit être verrouillé lors de la lecture des données, lors de l'exécution des transactions A et B, le verrou d'écriture des données sera occupé, obligeant le quatrième méchant à attendre le verrou.
La figure 2 répertorie les problèmes rencontrés par différents niveaux d'isolement. 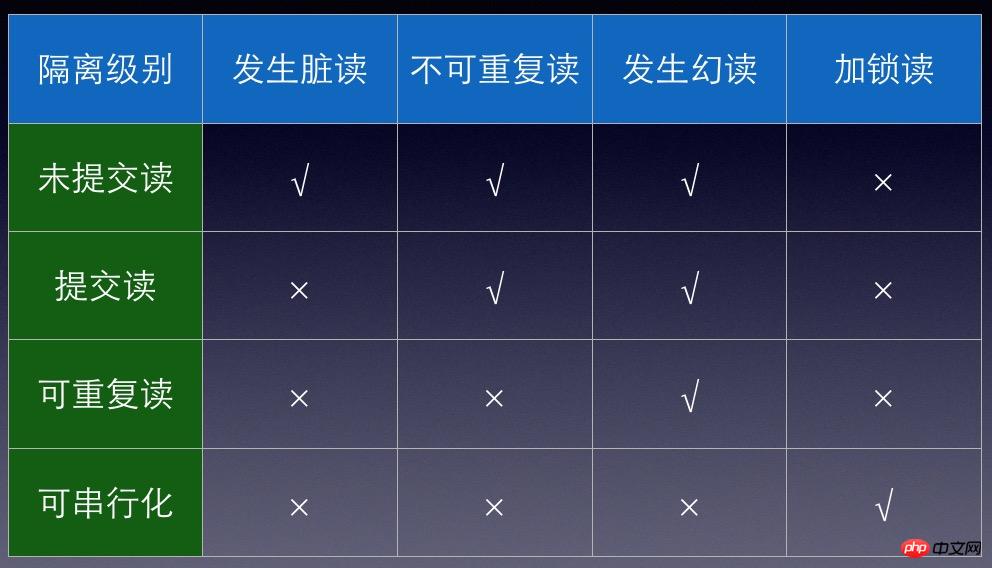
Figure 2
Évidemment, plus le niveau d'isolement est élevé, plus la consommation de ressources (verrous) qu'il apporte est importante, donc sa simultanéité Les performances sont moindres. Pour être précis, sous le niveau d'isolement sérialisable, il n'y a pas de concurrence. 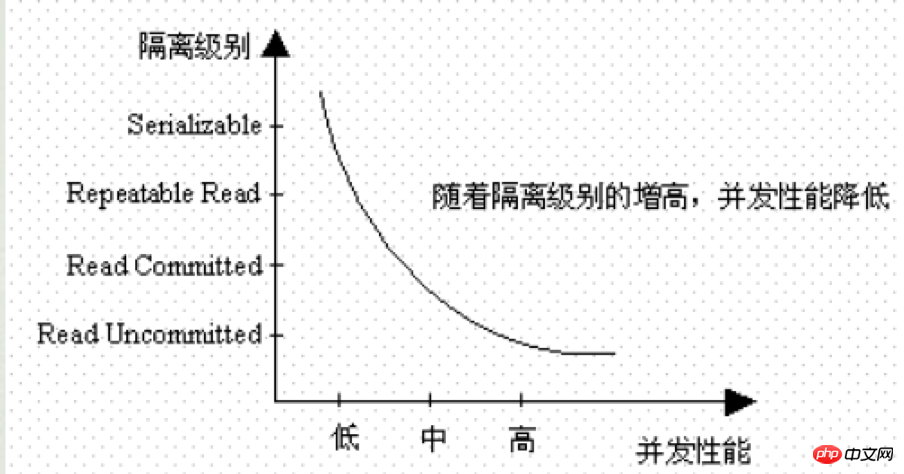
Figure 3
Transactions dans MySql
La mise en œuvre des transactions est basée sur le moteur de stockage de la base de données. Différents moteurs de stockage ont différents niveaux de prise en charge des transactions. Les moteurs de stockage qui prennent en charge les transactions dans MySQL incluent innoDB et NDB. innoDB est le moteur de stockage par défaut de mysql. Le niveau d'isolement par défaut est RR, et il va encore plus loin sous le niveau d'isolement de RR. Il résout le problème de lecture non répétable grâce au contrôle de concurrence multi-versions (. MVCC (Multiversion Concurrency Control), ajoutant Utiliser des verrous d'espacement (c'est-à-dire un contrôle de concurrence) pour résoudre le problème de lecture fantôme. Par conséquent, le niveau d'isolation RR d'innoDB produit réellement l'effet du niveau de sérialisation et conserve des performances de concurrence relativement bonnes.
L'isolement des transactions est obtenu grâce à des verrous, tandis que l'atomicité, la cohérence et la durabilité des transactions sont obtenues grâce aux journaux de transactions. En ce qui concerne les journaux de transactions, ce que je dois dire, c'est refaire et annuler.
1.redo log
Dans le moteur de stockage innoDB, le journal des transactions est implémenté via le redo log et le tampon de journal (InnoDB Log Buffer) du moteur de stockage innoDB. Lorsqu'une transaction est démarrée, les opérations de la transaction seront d'abord écrites dans le tampon de journal du moteur de stockage. Avant que la transaction ne soit validée, ces journaux mis en mémoire tampon doivent être vidés au préalable sur le disque pour des raisons de persistance. "connectez-vous d'abord" "(journalisation avec écriture anticipée). Une fois la transaction validée, les fichiers de données mappés dans le pool de tampons seront lentement actualisés sur le disque. À ce stade, si la base de données tombe en panne ou est en panne, lorsque le système est redémarré pour une récupération, la base de données peut être restaurée à un état avant le crash en fonction des journaux enregistrés dans le journal redo. Les transactions inachevées peuvent continuer à être soumises ou annulées, en fonction de la stratégie de récupération.
Lorsque le système démarre, un espace de stockage continu a été alloué pour le journal redo, le journal redo est enregistré dans une méthode d'ajout séquentiel et les performances sont améliorées grâce aux E/S séquentielles. Toutes les transactions partagent l'espace de stockage du redo log, et leurs redo logs sont enregistrés ensemble alternativement selon l'ordre d'exécution des instructions. À titre d'exemple simple :
Enregistrement 1 :
Enregistrement 2 :
Enregistrement 3 :
Enregistrement 4 :
Enregistrement 5 :
2.undo log
undo log sert principalement à l'annulation des transactions. Pendant le processus d'exécution de la transaction, en plus de l'enregistrement du journal de rétablissement, une certaine quantité de journal d'annulation sera également enregistrée. Le journal d'annulation enregistre l'état des données avant chaque opération. Si une restauration est requise pendant l'exécution de la transaction, l'opération de restauration peut être effectuée sur la base du journal d'annulation. L'annulation d'une seule transaction annulera uniquement les opérations effectuées par la transaction en cours et n'affectera pas les opérations effectuées par d'autres transactions.
Ce qui suit est le processus simplifié d'annulation + rétablissement de la transaction
Supposons qu'il y ait 2 valeurs, A et B, avec les valeurs 1 et 2
1 démarrer la transaction. ;
2. Enregistrez A=1 pour annuler le journal ;
3. Mettez à jour A = 3;
4. Enregistrez A=3 pour refaire le journal;
5. Enregistrez B = 2 pour annuler le journal ;
6. Mettez à jour B = 4 ;
7. Enregistrez B = 4 pour refaire le journal ; redo log Actualiser sur le disque
9. commit
Si le système tombe en panne à une étape 1 à 8 et que la transaction n'est pas validée, la transaction n'aura aucun impact sur les données sur le disque. S'il descend entre 8 et 9, vous pouvez choisir de revenir en arrière après la récupération, ou vous pouvez choisir de continuer à terminer la soumission de la transaction, car le journal redo a été conservé à ce moment-là. Si le système tombe en panne après 9 heures et que les données modifiées dans la carte mémoire ne sont pas renvoyées sur le disque, une fois le système récupéré, les données peuvent être renvoyées sur le disque conformément au journal de rétablissement.
Ainsi, le redo log garantit en fait la durabilité et la cohérence des transactions, tandis que l'annulation du journal garantit l'atomicité des transactions.
Transactions distribuées
Il existe de nombreuses façons d'implémenter des transactions distribuées. Vous pouvez utiliser la prise en charge native des transactions fournie par innoDB ou utiliser des files d'attente de messages pour implémenter des transactions distribuées. . Cohérence éventuelle des transactions. Ici, nous parlons principalement de la prise en charge par innoDB des transactions distribuées.  Comme le montre la figure, le modèle de transaction distribuée de MySQL. Le modèle est divisé en trois parties : programme d'application (AP), gestionnaire de ressources (RM) et gestionnaire de transactions (TM).
Comme le montre la figure, le modèle de transaction distribuée de MySQL. Le modèle est divisé en trois parties : programme d'application (AP), gestionnaire de ressources (RM) et gestionnaire de transactions (TM).
L'application définit les limites de la transaction et spécifie les transactions à effectuer ;
Le gestionnaire de ressources fournit des méthodes pour accéder aux transactions. Habituellement, une base de données est un gestionnaire de ressources ; 🎜 >Le gestionnaire de transactions coordonne et participe aux différentes transactions de la transaction globale.
Les transactions distribuées adoptent une méthode de validation en deux phases. Dans la première phase, tous les nœuds de transaction commencent à se préparer et indiquent au gestionnaire de transactions qu'ils sont prêts. Le gestionnaire de transactions de deuxième étape indique à chaque nœud s'il doit valider ou annuler. Si un nœud échoue, tous les nœuds globaux doivent être restaurés pour garantir l'atomicité de la transaction.
Résumé
Quand devez-vous utiliser les transactions ? Je pense que tant que l'entreprise doit répondre aux scénarios ACID, la prise en charge des transactions est nécessaire. Les transactions sont indispensables, notamment dans les systèmes de commande et les systèmes bancaires. Cet article présente principalement les caractéristiques des transactions et la prise en charge des transactions par MySQL InnoDB. Il y a beaucoup plus de connaissances liées aux affaires que ce qui est indiqué dans l'article. Cet article n'est qu'une introduction. J'espère que les lecteurs me pardonneront toute lacune.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



