

Cet article présente principalement l'exemple de pagination d'implémentation des opérations avancées de Cassandra en Java (avec des exigences spécifiques du projet). Les amis intéressés peuvent s'y référer.
Le dernier blog parlait de la pagination Cassandra. Je pense que tout le monde y prêtera attention : la prochaine requête dépend de la requête précédente (toutes les clés primaires du dernier enregistrement de la requête précédente) . Il n'est pas aussi flexible que mysql, il ne peut donc implémenter que des fonctions telles que la page précédente et la page suivante, mais ne peut pas implémenter des fonctions telles que le numéro de page (les performances seront trop faibles s'il est forcé de l'être. mis en œuvre).
Regardons d'abord la méthode de pagination officielle du pilote
Si le nombre d'enregistrements obtenus par une requête est trop important et renvoyés en même temps, l'efficacité est très faible et très Il est possible de provoquer un débordement de mémoire et de faire planter l'ensemble de l'application. Ainsi, le pilote pagine le jeu de résultats et renvoie la page de données appropriée.
1. Définition de la taille de récupération
La taille de récupération fait référence au nombre d'enregistrements obtenus à partir de Cassandra à la fois, en d'autres termes, c'est le nombre d'enregistrements sur chaque page ; nous pouvons spécifier une valeur par défaut pour sa taille de récupération lors de la création d'une instance de cluster. Si elle n'est pas spécifiée, la valeur par défaut est 5000
// At initialization:
Cluster cluster = Cluster.builder()
.addContactPoint("127.0.0.1")
.withQueryOptions(new QueryOptions().setFetchSize(2000))
.build();
// Or at runtime:
cluster.getConfiguration().getQueryOptions().setFetchSize(2000);De plus, la taille de récupération peut également. être défini sur l'instruction
Statement statement = new SimpleStatement("your query");
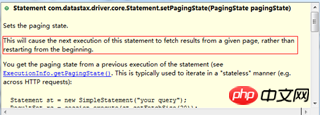
statement.setFetchSize(2000);Si la taille de récupération est définie sur l'instruction, alors la taille de récupération de l'instruction prendra effet, sinon la taille de récupération sur le cluster prendra effet.
Remarque : Définir la taille de récupération ne signifie pas que Cassandra renvoie toujours l'ensemble de résultats exact (égal à la taille de récupération), cela peut renvoyer un ensemble de résultats légèrement plus grand ou plus petit que la taille de récupération.
2. Itération de l'ensemble de résultats
la taille de récupération limite le nombre d'ensembles de résultats renvoyés par page. capturera automatiquement la page suivante d’enregistrements en arrière-plan. Comme dans l'exemple suivant, fetch size = 20 :
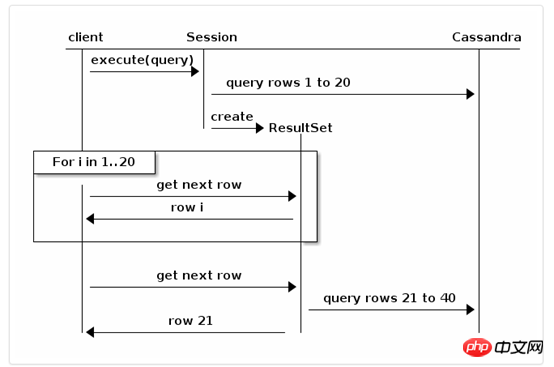
Par défaut, la récupération automatique en arrière-plan se produit au dernier moment, c'est-à-dire lorsque les enregistrements d'une certaine page ont été itératif. Si vous avez besoin d'un meilleur contrôle, l'interface ResultSet fournit les méthodes suivantes :
getAvailableWithoutFetching() and isFullyFetched() to check the current state; fetchMoreResults() to force a page fetch;
Voici comment utiliser ces méthodes pour pré-vider la page suivante à l'avance afin d'éviter d'itérer sur un certain page. Dégradation des performances causée par l'exploration de la page suivante uniquement :
ResultSet rs = session.execute("your query");
for (Row row : rs) {
if (rs.getAvailableWithoutFetching() == 100 && !rs.isFullyFetched())
rs.fetchMoreResults(); // this is asynchronous
// Process the row ...
System.out.println(row);
}3. Enregistrez et réutilisez le statut de la pagination
<. 🎜>Parfois, il est très utile de sauvegarder l'état de la pagination pour une récupération ultérieure. Imaginez : il existe un service Web sans état qui affiche une liste de résultats et affiche un lien vers la page suivante. exécutez exactement la même requête que précédemment, sauf que l'itération doit commencer à l'endroit où la page précédente s'est arrêtée ; cela équivaut à se rappeler où la page précédente a itéré, puis la page suivante peut commencer à partir d'ici. Pour ce faire, le pilote expose un objet PagingStatequi représente notre position dans l'ensemble de résultats lorsque la page suivante est récupérée.
ResultSet resultSet = session.execute("your query");
// iterate the result set...
PagingState pagingState = resultSet.getExecutionInfo().getPagingState();
// PagingState对象可以被序列化成字符串或字节数组
String string = pagingState.toString();
byte[] bytes = pagingState.toBytes();< 🎜. >
Veuillez noter que l'état paginé ne peut être utilisé que de manière répétée avec exactement la même instruction (même requête, mêmes paramètres). De plus, il s'agit d'une valeur opaque et est simplement utilisée pour stocker une valeur d'état qui peut être réutilisée. Si vous essayez de modifier son contenu ou de l'utiliser sur une autre instruction, le pilote générera une erreur.PagingState.fromBytes(byte[] bytes); PagingState.fromString(String str);
Jetons un coup d'œil au code en particulier. L'exemple suivant est une requête pour simuler la pagination de page et implémenter le parcours de tous les enregistrements dans la table t
each Code principal :import java.util.Map;
import com.datastax.driver.core.PagingState;
public interface ICassandraPage
{
Map<String, Object> page(PagingState pagingState);
}import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.datastax.driver.core.PagingState;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.Session;
import com.datastax.driver.core.SimpleStatement;
import com.datastax.driver.core.Statement;
import com.huawei.cassandra.dao.ICassandraPage;
import com.huawei.cassandra.factory.SessionRepository;
import com.huawei.cassandra.model.Teacher;
public class CassandraPageDao implements ICassandraPage
{
private static final Session session = SessionRepository.getSession();
private static final String CQL_TEACHER_PAGE = "select * from mycas.teacher;";
@Override
public Map<String, Object> page(PagingState pagingState)
{
final int RESULTS_PER_PAGE = 2;
Map<String, Object> result = new HashMap<String, Object>(2);
List<Teacher> teachers = new ArrayList<Teacher>(RESULTS_PER_PAGE);
Statement st = new SimpleStatement(CQL_TEACHER_PAGE);
st.setFetchSize(RESULTS_PER_PAGE);
// 第一页没有分页状态
if (pagingState != null)
{
st.setPagingState(pagingState);
}
ResultSet rs = session.execute(st);
result.put("pagingState", rs.getExecutionInfo().getPagingState());
//请注意,我们不依赖RESULTS_PER_PAGE,因为fetch size并不意味着cassandra总是返回准确的结果集
//它可能返回比fetch size稍微多一点或者少一点,另外,我们可能在结果集的结尾
int remaining = rs.getAvailableWithoutFetching();
for (Row row : rs)
{
Teacher teacher = this.obtainTeacherFromRow(row);
teachers.add(teacher);
if (--remaining == 0)
{
break;
}
}
result.put("teachers", teachers);
return result;
}
private Teacher obtainTeacherFromRow(Row row)
{
Teacher teacher = new Teacher();
teacher.setAddress(row.getString("address"));
teacher.setAge(row.getInt("age"));
teacher.setHeight(row.getInt("height"));
teacher.setId(row.getInt("id"));
teacher.setName(row.getString("name"));
return teacher;
}
}import java.util.Map;
import com.datastax.driver.core.PagingState;
import com.huawei.cassandra.dao.ICassandraPage;
import com.huawei.cassandra.dao.impl.CassandraPageDao;
public class PagingTest
{
public static void main(String[] args)
{
ICassandraPage cassPage = new CassandraPageDao();
Map<String, Object> result = cassPage.page(null);
PagingState pagingState = (PagingState) result.get("pagingState");
System.out.println(result.get("teachers"));
while (pagingState != null)
{
// PagingState对象可以被序列化成字符串或字节数组
System.out.println("==============================================");
result = cassPage.page(pagingState);
pagingState = (PagingState) result.get("pagingState");
System.out.println(result.get("teachers"));
}
}
}
4. Requête de décalage Enregistrer l'état de la pagination peut garantir que le passage d'une page à la page suivante fonctionne bien (la page précédente peut également être implémentée), mais cela ne satisfait pas aux sauts aléatoires, comme passer directement à la page 10, car nous ne le faisons pas. Je ne connais pas l'état de la pagination de la page précédente de la page 10. Les fonctionnalités comme celle-ci qui nécessitent des requêtes de décalage ne sont pas prises en charge nativement par Cassandra. La raison en est que les requêtes de décalage sont inefficaces (les performances sont linéairement inversement proportionnelles au nombre de lignes ignorées), donc Cassandra décourage officiellement l'utilisation de décalages. Si nous devons implémenter une requête offset, nous pouvons la simuler sur le client. Cependant, la performance reste linéairement inversement proportionnelle, ce qui signifie que plus le décalage est grand, plus la performance est faible. Si la performance se situe dans notre plage d'acceptation, elle peut toujours être atteinte. Par exemple, chaque page affiche 10 lignes, et un maximum de 20 pages peuvent être affichées. Cela signifie que lors de l'affichage de la 20ème page, jusqu'à 190 lignes supplémentaires doivent être récupérées, mais cela n'entraînera donc pas une grande réduction des performances. , si la quantité de données n'est pas importante, il est toujours possible de simuler une requête de décalage. Par exemple, en supposant que 10 enregistrements sont affichés sur chaque page et que la taille de récupération est de 50, nous demandons la page 12 (c'est-à-dire les lignes 110 à 119) : 1. requête une fois, et l'ensemble de résultats contient les lignes 0 à 49. Nous n'avons pas besoin de l'utiliser, nous avons seulement besoin du statut de pagination 2. Utilisez le statut de pagination obtenu à partir de la première requête pour exécuter la seconde ; query; 3. Utilisez le statut de pagination obtenu à partir de la deuxième requête pour exécuter la troisième requête. L'ensemble de résultats contient 100 à 149 lignes ; 4. À l'aide de l'ensemble de résultats obtenu à partir de la troisième requête, filtrez d'abord les 10 premiers enregistrements, puis lisez 10 enregistrements, puis supprimez les enregistrements restants et lisez les 10. les enregistrements sont les enregistrements qui doivent être affichés à la page 12. Nous devons essayer de trouver la meilleure taille de récupération pour obtenir le meilleur équilibre : une taille trop petite signifie plus de requêtes en arrière-plan ; une taille trop grande signifie renvoyer une plus grande quantité d'informations et plus de OK inutiles. De plus, Cassandra elle-même ne prend pas en charge les requêtes offset. Sous réserve de performances satisfaisantes, la mise en œuvre du décalage de simulation côté client n'est qu'un compromis. Les recommandations officielles sont les suivantes : 1. Testez le code en utilisant les modèles de requête attendus pour vous assurer que les hypothèses sont correctes. 2 Fixez une limite stricte au nombre maximum de pages pour empêcher les utilisateurs malveillants de le faire. déclenchant une grande requête de ligne sautée 5. Résumé Cassandra a une prise en charge limitée de la pagination, et la page précédente et la page suivante sont plus faciles à mettre en œuvre . La requête de décalage n'est pas prise en charge. Si vous insistez pour la mettre en œuvre, vous pouvez utiliser la simulation client. Cependant, il est préférable de ne pas utiliser ce scénario sur Cassandra, car Cassandra est généralement utilisée pour résoudre des problèmes de Big Data et compenser une fois la quantité de données. dans la requête est trop volumineuse, les performances ne peuvent pas être complimentées. Dans mon projet, index repair utilise la pagination de cassandra. Le scénario est le suivant : la table cassandra n'a pas d'index secondaire, et elasticsearch est utilisé pour implémenter l'index secondaire de cassandra. table. Ensuite, cela impliquera la question de la réparation de la cohérence de l'index. La pagination Cassandra est utilisée ici pour parcourir la table entière d'une table Cassandra et la faire correspondre une par une avec les données dans elasticsearch. dans elasticsearch. Ajoutez , s'il existe mais est incohérent, corrigez-le dans elasticsearch. La manière dont elasticsearch implémente la fonction d'indexation de cassandra sera spécifiquement expliquée dans mon prochain blog, je n'entrerai donc pas dans les détails ici. La pagination est requise lors du parcours de l'intégralité de la table Cassandra, car la quantité de données dans la table est trop importante et il est impossible de charger des centaines de millions de données dans la mémoire à la fois.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



