

Classique pratique du développement Web Java
Dans le développement de projets, la fonction principale du HTML est d'afficher les données, et pour standardiser la structure de stockage des données, vous devez utiliser XML . XML a sa propre syntaxe et tous les éléments de balisage peuvent être définis arbitrairement par l'utilisateur.
XML (eXtended Markup Language, langage de balisage extensible) fournit un langage de balisage multiplateforme et multi-réseau , méthode de description des données entre langages de programmes, utilisant XML peut facilement réaliser des fonctions courantes telles que l'échange de données, la configuration du système et la gestion de contenu.
XML est similaire au HTML, les deux sont des langages de balisage. La plus grande différence est que les éléments en HTML sont fixes et principalement axés sur l'affichage, tandis que les balises en langage XML sont personnalisées par les utilisateurs et se concentrent principalement sur le stockage des données.
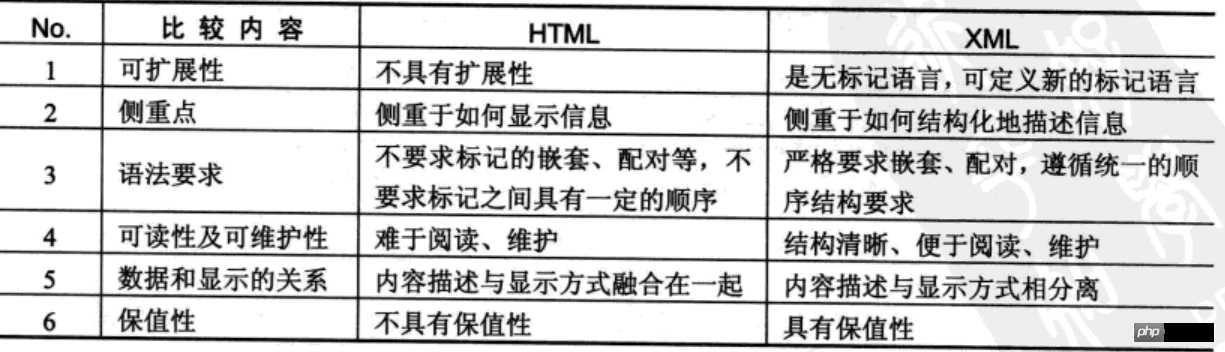
Comparaison du XML et du HTML
En fait, tous les fichiers XML sont regroupés en deux parties : zone de début et zone de données Succès.
Zone Leader : Spécifie certains attributs de la page XML. Il existe les 3 attributs suivants :
version : Indique la version XML utilisée, est maintenant 1.0.
encodage : L'encodage du texte utilisé dans la page. S'il y a du chinois, l'encodage doit être précisé.
autonome : Que ce fichier XML soit exécuté indépendamment. S'il doit être affiché, il peut être contrôlé à l'aide de CSS ou de XSL.
L'ordre dans lequel les attributs apparaissent est fixe, version, encodage, autonome. Une fois l'ordre incorrect, XML provoquera des erreurs.
<?xml version="1.0" encoding="GB2312" standalone="no"?>Copier après la connexionZone de données : toutes les zones de données doivent avoir un élément racine. Plusieurs sous-éléments peuvent être stockés sous un élément racine, mais chaque élément doit être complété. Chaque marque est sensible à la taille. Écrit.
La balise CDATA est fournie dans le langage XML pour identifier les données du fichier. Lorsque l'analyseur XML traite la balise CDATA, il n'analysera aucun symbole ou balise dans les données, mais le fera. Les données originales sont transmises intactes à l’application.
Format de syntaxe CDATA :
<![CDATA[] 不解析内容 ]>
Dans le fichier XML, car il contient des informations plus descriptives, utilisez cette application après avoir obtenu un document XML. le contenu correspondant en fonction du nom défini de l'élément. Cette opération est appelée analyse XML.
Dans l'analyse XML, W3C définit deux méthodes d'analyse, SAX et DOM. Les opérations de programme de ces deux méthodes d'analyse sont les suivantes :
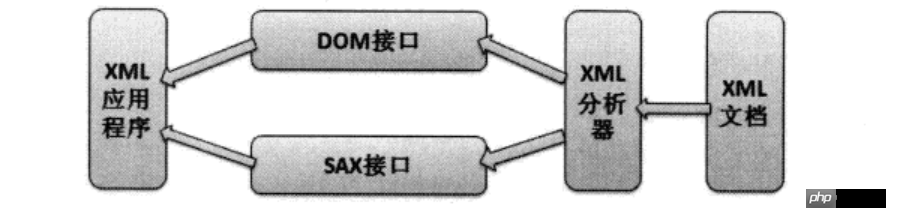
Opération d'analyse XML
On peut voir que l'application n'opère pas directement sur le document XML. Au lieu de cela, le document XML est d'abord analysé par l'analyseur XML, puis l'application transmet le DOM fourni par. l'analyseur XML. L' interface ou l'interface SAX opère sur la structure d'analyse, accédant ainsi indirectement au document XML.
2.1. Opération d'analyse DOM
Dans l'application, basée sur DOM (Document Objet Modèle, DocumentObjectModel) L'analyseur XML convertit un document XML en une collection de modèles d'objet (souvent appelé arbre DOM) C'est grâce au fonctionnement de ce modèle d'objet que l'application Cheng Xun réalise les opérations. sur les données de documents XML. Grâce à l'interface DOM, l'application peut accéder à tout moment à n'importe quelle partie des données du document XML. Par conséquent, ce mécanisme qui utilise l'interface DOM est également appelé mécanisme d'accès aléatoire.
Étant donné que l'analyseur DOM convertit l'intégralité du document XML en une arborescence DOM et le stocke en mémoire, lorsque le document est volumineux ou que la structure est complexe, les besoins en mémoire sont relativement élevés et la traversée d'arbres avec des structures complexes est également difficile. Une opération qui prend du temps.
L'opération DOM transformera tous les fichiers XML en arborescences DOM en mémoire.
Il existe les 4 interfaces d'opération principales suivantes dans l'analyse DOM :
Document : cette interface représente l'intégralité du document XML, représente la racine de l'ensemble de l'arborescence DOM et fournit L'entrée pour accéder et exploiter les données du document. Tous les contenus des éléments du fichier XML sont accessibles via le nœud Document.

Méthodes courantes de l'interface de document
Node:DOM操作的核心接口中有很大一部分是从Node接口继承过来的。例如Document、Element、Attri等接口。在DOM树中,每一个Node接口代表了DOM树中的一个节点。
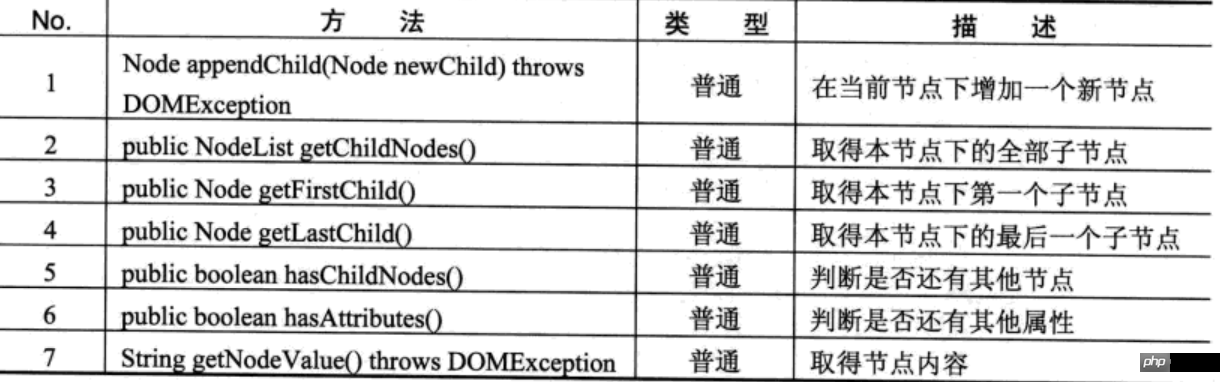
Node接口的常用方法
NodeList:此接口表示一个节点的集合,一般用于表示有顺序关系的一组节点。例如,一个节点的子节点,当文档改变时会直接 影响到NodeList集合。

NodeList接口的常用方法
NameNodeMap:此接口表示一组节点和其唯一名称对应的一一对应关系,主要用于属性节点的表示。
出以上4个核心接口外,如果一个程序需要进行DOM解析读操作,则需要按如下步骤进行:
(1)建立DocumentBuilderFactory:DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
(2)建立DocumentBuilder:DocumentBuilder builder = factory.newDocumentBuilder();
(3)建立Document:Document doc= builder.parse("要读取的文件路径");
(4)建立NodeList:NodeList nl = doc.getElementsByTagName("读取节点");
(5)进行XML信息读取。
// xml_demo.xml <?xml version="1.0" encoding="GBK"?> <addresslist> <linkman> <name>小明</name> <email>asaasa@163.com</email> </linkman> <linkman> <name>小张</name> <email>xiaoli@163.com</email> </linkman> </addresslist>
DOM完成XML的读取。
package com.demo;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class XmlDomDemo {
public static void main(String[] args) {
// (1)建立DocumentBuilderFactory,以用于取得DocumentBuilder
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// (2)通过DocumentBuilderFactory,取得DocumentBuilder
DocumentBuilder builder = null;
try {
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
// (3)定义Document接口对象,通过DocumentBuilder类进行DOM树是转换操作
Document doc = null;
try {
// 读取指定路径的XML文件,读取到内存中
doc = builder.parse("xml_demo.xml");
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
// (4)查找linkman节点
NodeList nl = doc.getElementsByTagName("linkman");
// (5)输出NodeList中第一个子节点中文本节点的内容
for (int i = 0; i < nl.getLength(); i++) {
// 取出每一个元素
Element element = (Element) nl.item(i);
System.out.println("姓名:" + element.getElementsByTagName("name").item(0).getFirstChild().getNodeValue());
System.out.println("邮箱:" + element.getElementsByTagName("email").item(0).getFirstChild().getNodeValue());
}
}
}DOM完成XML的文件输出。
此时就需要使用DOM操作中提供的各个接口(如Element接口)并手工设置各个节点的关系,同时在创建Document对象时就必须使用newDocument()方法建立一个新的DOM树。
如果现在需要将XML文件保存在硬盘上,则需要使用TransformerFactory、Transformer、DOMSource、StreamResult 4个类完成。
TransformerFactory类:取得一个Transformer类的实例对象。
DOMSource类:接收Document对象。
StreamResult 类:指定要使用的输出流对象(可以向文件输出,也可以向指定的输出流输出)。
Transformer类:通过该类完成内容的输出。

StreamResult类的构造方法
package com.demo;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class XmlDemoWrite {
public static void main(String[] args) {
// (1)建立DocumentBuilderFactory,以用于取得DocumentBuilder
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// (2)通过DocumentBuilderFactory,取得DocumentBuilder
DocumentBuilder builder = null;
try {
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
// (3)定义Document接口对象,通过DocumentBuilder类进行DOM树是转换操作
Document doc = null;
// 创建一个新的文档
doc = builder.newDocument();
// (4)建立各个操作节点
Element addresslist = doc.createElement("addresslist");
Element linkman = doc.createElement("linkman");
Element name = doc.createElement("name");
Element email = doc.createElement("email");
// (5)设置节点的文本内容,即为每一个节点添加文本节点
name.appendChild(doc.createTextNode("小明"));
email.appendChild(doc.createTextNode("xiaoming@163.com"));
// (6)设置节点关系
linkman.appendChild(name);
linkman.appendChild(email);
addresslist.appendChild(linkman);
doc.appendChild(addresslist);
// (7)输出文档到文件中
TransformerFactory tf = TransformerFactory.newInstance();
Transformer t = null;
try {
t = tf.newTransformer();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
}
// 设置编码
t.setOutputProperty(OutputKeys.ENCODING, "GBK");
// 输出文档
DOMSource source = new DOMSource(doc);
// 指定输出位置
StreamResult result = new StreamResult(new File("xml_wirte.xml"));
try {
// 输出
t.transform(source, result);
System.out.println("yes");
} catch (TransformerException e) {
e.printStackTrace();
}
}
}生成文档:
//xml_write.xml <?xml version="1.0" encoding="GBK" standalone="no"?> <addresslist> <linkman> <name>小明</name> <email>xiaoming@163.com</email> </linkman> </addresslist>
2.2、SAX解析操作
SAX(Simple APIs for XML,操作XML的简单接口)与DOM操作不同的是,SAX采用的是一种顺序的模式进行访问,是一种快速读取XML数据的方式。
当使用SAX 解析器进行操作时会触发一系列的事件。
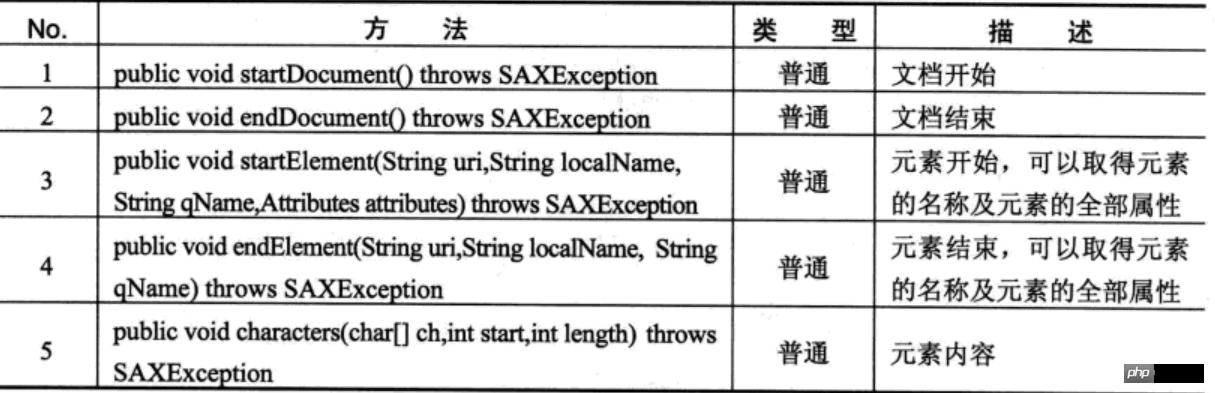
SAX主要事件
当扫描到文档(Document)开始与结束、元素(Element)开始与结束时都会调用相关的处理方法,并由这些操作方法做出相应的操作,直到整个文档扫描结束。
如果在开发中想要使用SAX解析,则首先应该编写一个SAX解析器,再直接定义一个类,并使该类继承自DefaultHandler类,同时覆写上述的表中的方法即可。
package com.sax.demo;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class XmlSax extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
System.out.println("<?xml version=\"1.0\" encoding=\"GBK\"?>");
}
@Override
public void endDocument() throws SAXException {
System.out.println("\n 文档读取结束。。。");
}
@Override
public void startElement(String url, String localName, String name,
Attributes attributes) throws SAXException {
System.out.print("<");
System.out.print(name);
if (attributes != null) {
for (int x = 0; x < attributes.getLength(); x++) {
System.out.print("" + attributes.getQName(x) + "=\"" + attributes.getValue(x) + "\"");
}
}
System.out.print(">");
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.print(new String(ch, start, length));
}
@Override
public void endElement(String url, String localName, String name)
throws SAXException {
System.out.print("</");
System.out.print(name);
System.out.print(">");
}
}建荔湾SAX解析器后,还需要建立SAXParserFactory和SAXParser对象,之后通过SAXPaeser的parse()方法指定要解析的XML文件和指定的SAX解析器。
建立要读取的文件:sax_demo.xml
<?xml version="1.0" encoding="GBK"?> <addresslist> <linkman id="xm"> <name>小明</name> <email>xiaoming@163.com</email> </linkman> <linkman id="xl"> <name>小李</name> <email>xiaoli@163.com</email> </linkman> </addresslist>
使用SAX解析器
package com.sax.demo;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
public class SaxTest {
public static void main(String[] args) throws Exception {
//(1)建立SAX解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//(2)构造解析器
SAXParser parser = factory.newSAXParser();
//(3)解析XML使用handler
parser.parse("sax_demo.xml", new XmlSax());
}
}通过上面的程序可以发现,使用SAX解析比使用DOM解析更加容易。
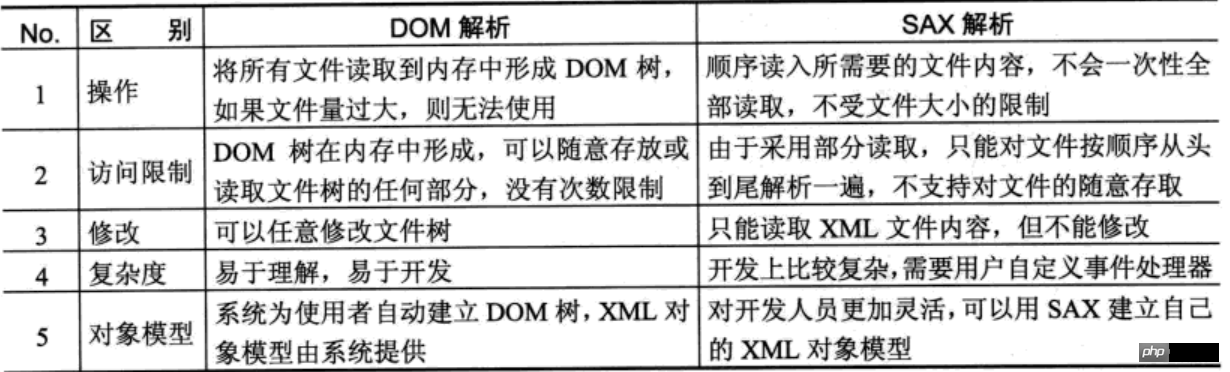
DOM解析与SAX解析的区别
有两者的特点可以发现两者的区别:
DOM解析适合于对文件进行修改和随机存取的操作,但是不适合于大型文件的操作。
SAX采用部分读取的方式,所以可以处理大型文件,而且只需要从文件中读取特定内容。SAX解析可以由用户自己建立自己的对象模型。
2.3、XML解析的好帮手:jdom
jdom是使用Java编写的,用于读、写、操作XML的一套组件。
jdom = dom 修改文件的有点 + SAX读取快速的优点

jdom的主要操作类
使用jdom生成XML文件
package com.jdom.demo;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import org.jdom.Attribute;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.output.XMLOutputter;
public class WriteXml {
public static void main(String[] args) {
// 定义节点
Element addresslist = new Element("addresslist");
Element linkman = new Element("linkman");
Element name = new Element("name");
Element email = new Element("email");
// 定义属性
Attribute id = new Attribute("id", "xm");
// 声明一个Document对象
Document doc = new Document(addresslist);
// 设置元素的内容
name.setText("小明");
email.setText("xiaoming@163.com");
name.setAttribute(id);
// 设置子节点
linkman.addContent(name);
linkman.addContent(email);
// 将linkman加入根子节点
addresslist.addContent(linkman);
// 用来输出XML文件
XMLOutputter out = new XMLOutputter();
// 设置输出编码
out.setFormat(out.getFormat().setEncoding("GBK"));
// 输出XML文件
try {
out.output(doc, new FileOutputStream("jdom_write.xml"));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}// jdom_write.xml <?xml version="1.0" encoding="GBK"?> <addresslist> <linkman> <name id="xm">小明</name> <email>xiaoming@163.com</email> </linkman> </addresslist>
使用jdom读取XML文件
package com.jdom.demo;
import java.io.IOException;
import java.util.List;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
public class ReadXml {
public static void main(String[] args) throws JDOMException, IOException {
//建立SAX解析
SAXBuilder builder = new SAXBuilder();
//找到Document
Document readDoc = builder.build("jdom_write.xml");
//读取根元素
Element stu = readDoc.getRootElement();
//得到全部linkman子元素
List list = stu.getChildren("linkman");
for (int i = 0; i < list.size(); i++) {
Element e = (Element) list.get(i);
String name = e.getChildText("name");
String id = e.getChild("name").getAttribute("id").getValue();
String email = e.getChildText("email");
System.out.println("----联系人----");
System.out.println("姓名:" + name + "编号:" + id);
System.out.println("Email:" + email);
}
}
}jdom是一种常见的操作组件
在实际的开发中使用非常广泛。
2.4、解析工具:dom4j
dom4j也是一组XML操作组件包,主要用来读写XML文件,由于dom4j性能优异、功能强大,且具有易用性,所以现在已经被广泛地应用开来。如,Hibernate、Spring框架中都使用了dom4j进行XML的解析操作。
开发时需要引入的jar包:dom4j-1.6.1.jar、lib/jaxen-1.1-beta-6.jar
dom4j中的所用操作接口都在org.dom4j包中定义。其他包根据需要把选择使用。
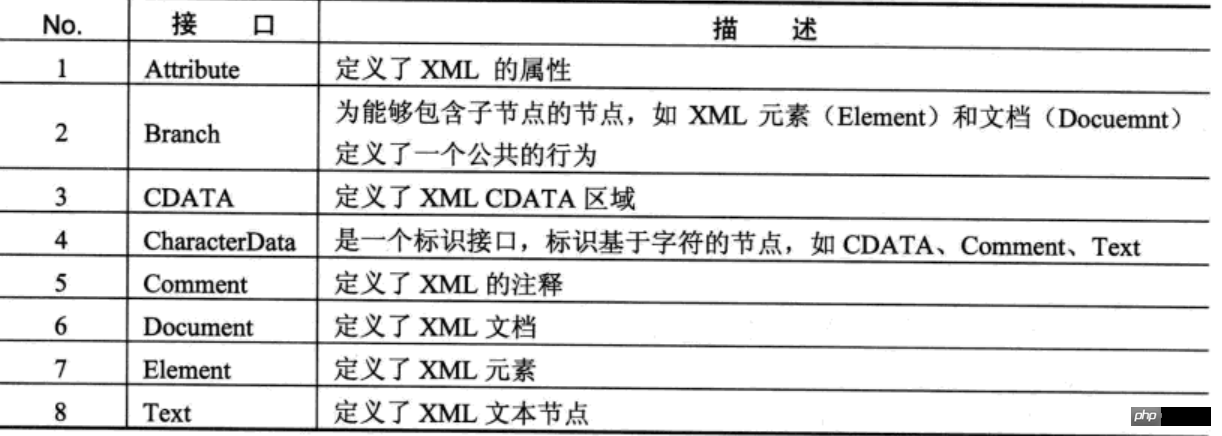
dom4j的主要接口
用dom4j生成XML文件:
package com.dom4j.demo;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class Dom4jWrite {
public static void main(String[] args) {
// 创建文档
Document doc = DocumentHelper.createDocument();
// 定义个节点
Element addresslist = doc.addElement("addresslist");
Element linkman = addresslist.addElement("linkman");
Element name = linkman.addElement("name");
Element email = linkman.addElement("email");
// 设置节点内容
name.setText("小明");
email.setText("xiaoming@163.com");
// 设置输出格式
OutputFormat format = OutputFormat.createPrettyPrint();
// 指定输出编码
format.setEncoding("GBK");
try {
XMLWriter writer = new XMLWriter(new FileOutputStream(new File(
"dom4j_demo.xml")), format);
writer.write(doc);
writer.close();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}// dom4j_demo.xml <?xml version="1.0" encoding="GBK"?> <addresslist> <linkman> <name>小明</name> <email>xiaoming@163.com</email> </linkman> </addresslist>
用dom4j读取XML文件:
package com.dom4j.demo;
import java.io.File;
import java.util.Iterator;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4jRead {
public static void main(String[] args) {
//读取文件
File file = new File("dom4j_demo.xml");
//建立SAX解析读取
SAXReader reader = new SAXReader();
Document doc = null;
try {
//读取文档
doc = reader.read(file);
} catch (DocumentException e) {
e.printStackTrace();
}
//取得根元素
Element root = doc.getRootElement();
//取得全部的子节点
Iterator iter = root.elementIterator();
while (iter.hasNext()) {
//取得每一个linkman
Element linkman = (Element) iter.next();
System.out.println("姓名:"+linkman.elementText("name"));
System.out.println("邮件地址:"+linkman.elementText("email"));
}
}
}XML主要用于数据交换,而HTML则用于显示。
Java直接提供的XML解析方式分为两种,即DOM和SAX。这两种解析的区别如下:
DOM解析是将所有内容读取到内存中,并形成内存树,如果文件量较大则无法使用,但是DOM解析可以进行文件的修改
SAX解析是采用顺序的方式读取XML文件中,不受文件大小限制,但是不允许修改。
XML解析可以使用jdom和dom4j第三方工具包,以提升开发效率。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment convertir un pdf au format XML
Comment convertir un pdf au format XML
 Comment vendre des pièces LUNA
Comment vendre des pièces LUNA
 Quelles sont les méthodes pour télécharger des vidéos depuis Douyin ?
Quelles sont les méthodes pour télécharger des vidéos depuis Douyin ?
 Classements des échanges de crypto-monnaie
Classements des échanges de crypto-monnaie
 Trois méthodes d'encodage couramment utilisées
Trois méthodes d'encodage couramment utilisées
 Comment calculer les frais de traitement du remboursement du chemin de fer 12306
Comment calculer les frais de traitement du remboursement du chemin de fer 12306
 Comment résoudre le statut http 404
Comment résoudre le statut http 404
 Comment désactiver les mises à jour automatiques dans Win10
Comment désactiver les mises à jour automatiques dans Win10








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



