

Pré-connaissances ASP.NET WebAPI : HTTP et RestfulAPI

Une compréhension de base du protocole HTTP est la base pour comprendre et utiliser le style API de RestFul. Après avoir compris ces bases, utilisez divers frameworks de développement RestFul. Vous pouvez être pratique. Lorsque j'ai commencé à utiliser WebApi, je sentais que ce n'était pas confortable à utiliser en raison de mon manque de compréhension de ces connaissances. Ce n'est que lorsque je me suis familiarisé avec ces connaissances HTTP que je me suis senti à l'aise avec WebApi pour développer. L'API de style RestFul est une API qui prend bien en charge le protocole HTTP et implémente le style sémantique complet de HTTP.
Avant d'introduire ces connaissances, je dois souligner un malentendu que beaucoup de gens ont : les prédicats HTTP et les méthodes de transmission de données. Le protocole HTTP avec lequel la plupart des gens entrent en contact et utilise est en train d'écrire des sites Web. Dans les applications WEB en général, nous n'utilisons que les deux prédicats GET et POST, et d'autres prédicats ne sont pas applicables. Sous cette habitude, de nombreuses personnes en ont plusieurs. cognitions étranges : le protocole HTTP ne convient qu'au développement de sites Web. HTTP n'a que deux prédicats : le transfert de données d'appel HTTP n'est effectué que sous la forme de K-V, et le développement dans ce style est souvent indéfinissable. l'utilisation de ASP.NET WebAPi apparaîtra également de manière indéfinissable, provoquant des problèmes. Nous devons d’abord comprendre que l’interaction des données sur le site Web n’est qu’un scénario d’utilisation de HTTP, et que HTTP peut transférer diverses formes de données.
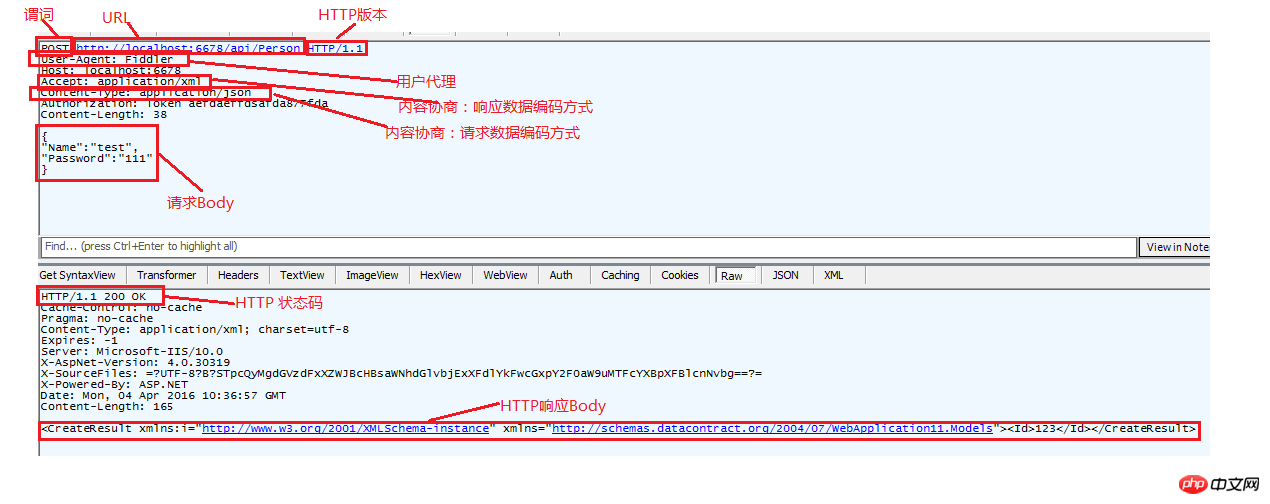
Nous commençons par la première ligne de HTTP : La première ligne de HTTP contient trois informations : le prédicat, l'URL et la version du protocole HTTP. Les trois données sont séparées par des espaces.
Prédicat : Le prédicat est un élément très important pour l'API RestFul. L'API WEB utilise des prédicats comme méthode de routage par défaut. Les prédicats les plus couramment utilisés sont : POSTDELETEPUTGET. , ces quatre prédicats correspondent aux quatre actions de "ajouter, supprimer, modifier et vérifier" (POST et PUT sont utilisés pour ajouter et modifier différentes données. Il y a toujours des avis différents. En fait, je suis un peu confus... Oui La définition dit que PUT est une opération idempotente, mais POST ne l'est pas, donc PUT est plus axé sur les changements et POST est plus axé sur les augmentations). Les prédicats les plus couramment utilisés sont ces quatre-là, et il existe d'autres prédicats avec une sémantique différente :
HEAD : renvoie uniquement l'en-tête correspondant, excluant Body
TRACE : Oui Diagnostiquer le processus de transfert de données
OPTIONS : Demander au serveur Web d'informer les différentes fonctions qu'il prend en charge
Il existe d'autres prédicats Si nécessaire, vous pouvez interroger les documents associés, mais. pas couramment utilisé.
Parmi eux, GET et DELETE ne contiennent pas de BODY, tandis que PUT et POST peuvent contenir BODY. Et si un prédicat contient des opérations en dehors de la sémantique, comme GET avec BODY, POST est utilisé pour supprimer des ressources. Cette opération est également autorisée, et est appelée la surcharge du prédicat. , bien que HTTP puisse prendre en charge la surcharge de prédicats, son utilisation n'est pas recommandée car elle n'est pas conforme à la sémantique standard.
URL : l'URL définit une ressource, telle que www.example.com/person définit une personne en tant que ressource. En combinaison avec les prédicats introduits ci-dessus, nous fournissons Personne. ensemble d'opérations :
GET www.example/person/1 pour obtenir les informations de l'utilisateur avec l'ID 1
POST www.example/person/ (dans BODY Contient la description de la personne) Créer une ressource Personne
PUT www.example/person/1 (BODY contient la description de la personne) Mettre à jourUne ressource Personne
.1, le protocole HTTP2.0 est en phase de vulgarisation et n'est pas encore beaucoup utilisé. La différence entre HTTP1.0 et HTTP1.1 est très faible et n'a pas un grand impact sur RestFul. Pour des différences spécifiques, vous pouvez consulter les documents pertinents.
Il s'agit de la première ligne de HTTP. Ensuite, il y aura un rn pour rompre la ligne. Ensuite, la partie HTTP HEAD décrit la requête et la réponse HTTP. Je pense que HTTP HEAD est la partie la plus importante du protocole HTTP. Il contient des informations telles que l'encodage, la longueur du CORPS, la négociation de contenu, etc. Vous pouvez également inclure des informations personnalisées. Permettez-moi de vous présenter quelques HEAD couramment utilisés dans l'API RestFul :
User-Agent : agent utilisateur, quel client fait la demande, comme IE, Chrome, Fid dl euh, etc.
HOST : Nom de domaine (HOST est généralement utilisé pour la liaison de site du serveur. Il est généralement le même que le nom de domaine de l'URL, mais dans certaines utilisations DNS personnalisées, il peut apparaître Les noms de domaine dans HOST et URL sont incohérents)
Autorisation : informations de vérification, ce champ peut contenir des informations pour la vérification de l'utilisateur, et la méthode de représentation est : info d'auteur du schéma, séparé par des espaces, où le schéma représente la vérification Méthode, authorinfo représente les informations de vérification, schéma commun tel que Base : authorinfo utilise le nom d'utilisateur + le mot de passe et est codé en Base64. Ou utilisez un jeton, similaire à Session.
Accepter : quelle méthode de sérialisation pour accepter les données renvoyées, exprimées en MIME, utilisée pour la négociation du contenu des données de réponse, peut contenir plusieurs MIME, classés par ordre de priorité, tels que application/json, application/xml, text/html ; le type spécifique de données que le serveur peut renvoyer dépend du support du serveur. Il existe parfois des MIME personnalisés ; Comme bson, protocolbuffer, etc., nous pouvons personnaliser MIME et développer notre propre implémentation côté serveur, et ces extensions spéciales ont des points d'extension correspondants dans ASP.NET WebApi.
Content-Type : utilisez une représentation MIME pour indiquer la méthode de sérialisation du corps de la demande envoyée. Les méthodes courantes sont application/json et application/x-www-, qui est la plus couramment utilisée. pour l'interaction WEB. pourm-urlencoded, les deux représentent la méthode de sérialisation de votre partie du corps, qui apparaîtra dans les requêtes et les réponses
Je pense que la partie HTTP HEAD est la. cœur du protocole HTTP. Il y a tellement d'endroits qui peuvent être configurés et utilisés, et il y a trop de détails. Ce sont les parties les plus couramment utilisées dans mon travail. Toutes les informations pour présenter ce contenu sont suffisantes pour compléter l'ensemble. processus. Ce livre est sorti. Si vous êtes intéressé, vous pouvez trouver des informations pertinentes. Dans l'API Rest, la négociation de contenu confond souvent les personnes qui apprennent à utiliser Rest au début. Accept et Content-Type. Accept exprime un espoir. Quel type de données est accepté ? Content-Type indique la méthode de codage du corps dans la requête actuelle. Dans ASP.NET WEBAPI, s'il y a un Content-Type dans la requête mais pas d'ACCEPT, le contenu du Content-Type est utilisé par défaut comme négociation de contenu pour la réponse.
La partie réponse est également divisée en en-tête et corps. La plus grande différence entre l'en-tête de réponse et l'en-tête de requête est qu'il y a un code HTTP dans la première ligne de la réponse, et le code HTTP est utilisé comme appel API L'affichage du statut est également très important. Le code de statut le plus couramment utilisé dans l'API REST est généralement composé de trois segments : 2XX, 4XX et 5XX. 1XX signifie que le travail va continuer, et 3XX signifie généralement une redirection, peu utilisée dans les API REST. Parmi les trois segments d'état les plus couramment utilisés, 2XX indique une exécution réussie, 4XX indique des erreurs de données client (telles que l'échec de la vérification des paramètres) et 5XX indique des erreurs de traitement côté serveur, telles que des exceptions non gérées (telles que des erreurs de connexion à la base de données). sur ces codes d'état, l'état d'exécution de l'appel API peut être initialement jugé.
Il y a une ligne vide (rn) après l'en-tête, suivie de Contenu. Il y a ici des données commerciales spécifiques, qui sont représentées par différentes méthodes de sérialisation selon différents types de contenu, tels que JSON, XML et même HTML. Lorsque vous apprenez l'API HTTP, vous pouvez penser que les applications Web sont également une application HTTP, mais la méthode d'interaction utilise généralement application/x-www-form-urlencoded comme requête et text/html comme réponse. RestAPI peut interagir avec de nombreuses autres méthodes de codage et offre une prise en charge plus large. L'application Web n'est qu'un scénario d'application qui utilise la transmission HTTP et les pages Web ne peuvent pas être séparées. Je pense que Nancy fait cela mieux qu'ASP.NET. Nancy ne sépare pas RestAPI de la page Web, tandis qu'ASP.NET sépare les deux en utilisant MVC et WEBAPI pour demander des données, je peux demander à Accepter ; renvoyer des données Json lorsqu'il s'agit d'application/json, et pour renvoyer une page Web lorsque text/html est utilisé, bien sûr, couper ou fusionner ces deux méthodes d'application a ses propres avantages et inconvénients ;
Ce que j'ai écrit est trop peu pour le protocole HTTP. Si vous êtes intéressé, vous pouvez rechercher vous-même les informations pertinentes. Je viens d'écrire les parties couramment utilisées de l'API WEB. l'image vous montre cette connaissance :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Que signifie le code d'état http 520 ?
Oct 13, 2023 pm 03:11 PM
Que signifie le code d'état http 520 ?
Oct 13, 2023 pm 03:11 PM
Le code d'état HTTP 520 signifie que le serveur a rencontré une erreur inconnue lors du traitement de la demande et ne peut pas fournir d'informations plus spécifiques. Utilisé pour indiquer qu'une erreur inconnue s'est produite lorsque le serveur traitait la demande, ce qui peut être dû à des problèmes de configuration du serveur, à des problèmes de réseau ou à d'autres raisons inconnues. Cela est généralement dû à des problèmes de configuration du serveur, des problèmes de réseau, une surcharge du serveur ou des erreurs de codage. Si vous rencontrez une erreur de code d'état 520, il est préférable de contacter l'administrateur du site Web ou l'équipe d'assistance technique pour plus d'informations et d'assistance.
 Qu'est-ce que le code d'état http 403 ?
Oct 07, 2023 pm 02:04 PM
Qu'est-ce que le code d'état http 403 ?
Oct 07, 2023 pm 02:04 PM
Le code d'état HTTP 403 signifie que le serveur a rejeté la demande du client. La solution au code d'état http 403 est la suivante : 1. Vérifiez les informations d'authentification. Si le serveur requiert une authentification, assurez-vous que les informations d'identification correctes sont fournies ; 2. Vérifiez les restrictions d'adresse IP. Si le serveur a restreint l'adresse IP, assurez-vous que les informations d'identification sont correctes. l'adresse IP du client est restreinte. Sur liste blanche ou non sur liste noire ; 3. Vérifiez les paramètres d'autorisation du fichier. Si le code d'état 403 est lié aux paramètres d'autorisation du fichier ou du répertoire, assurez-vous que le client dispose des autorisations suffisantes pour accéder à ces fichiers ou répertoires. etc.
 Comprendre les scénarios d'application courants de redirection de pages Web et comprendre le code d'état HTTP 301
Feb 18, 2024 pm 08:41 PM
Comprendre les scénarios d'application courants de redirection de pages Web et comprendre le code d'état HTTP 301
Feb 18, 2024 pm 08:41 PM
Comprendre la signification du code d'état HTTP 301 : scénarios d'application courants de redirection de pages Web Avec le développement rapide d'Internet, les exigences des utilisateurs en matière d'interaction avec les pages Web sont de plus en plus élevées. Dans le domaine de la conception Web, la redirection de pages Web est une technologie courante et importante, mise en œuvre via le code d'état HTTP 301. Cet article explorera la signification du code d'état HTTP 301 et les scénarios d'application courants dans la redirection de pages Web. Le code d'état HTTP 301 fait référence à une redirection permanente (PermanentRedirect). Lorsque le serveur reçoit le message du client
 Comment utiliser Nginx Proxy Manager pour implémenter le saut automatique de HTTP à HTTPS
Sep 26, 2023 am 11:19 AM
Comment utiliser Nginx Proxy Manager pour implémenter le saut automatique de HTTP à HTTPS
Sep 26, 2023 am 11:19 AM
Comment utiliser NginxProxyManager pour implémenter le saut automatique de HTTP à HTTPS Avec le développement d'Internet, de plus en plus de sites Web commencent à utiliser le protocole HTTPS pour crypter la transmission des données afin d'améliorer la sécurité des données et la protection de la vie privée des utilisateurs. Le protocole HTTPS nécessitant la prise en charge d'un certificat SSL, un certain support technique est requis lors du déploiement du protocole HTTPS. Nginx est un serveur HTTP et un serveur proxy inverse puissants et couramment utilisés, et NginxProxy
 Envoyer une requête POST avec les données du formulaire à l'aide de la fonction http.PostForm
Jul 25, 2023 pm 10:51 PM
Envoyer une requête POST avec les données du formulaire à l'aide de la fonction http.PostForm
Jul 25, 2023 pm 10:51 PM
Utilisez la fonction http.PostForm pour envoyer une requête POST avec des données de formulaire. Dans le package http du langage Go, vous pouvez utiliser la fonction http.PostForm pour envoyer une requête POST avec des données de formulaire. Le prototype de la fonction http.PostForm est le suivant : funcPostForm(urlstring,dataurl.Values)(resp*http.Response,errerror)where, u
 Application rapide : analyse de cas de développement pratique du téléchargement HTTP asynchrone PHP de plusieurs fichiers
Sep 12, 2023 pm 01:15 PM
Application rapide : analyse de cas de développement pratique du téléchargement HTTP asynchrone PHP de plusieurs fichiers
Sep 12, 2023 pm 01:15 PM
Application rapide : analyse de cas de développement pratique de PHP Téléchargement HTTP asynchrone de plusieurs fichiers Avec le développement d'Internet, la fonction de téléchargement de fichiers est devenue l'un des besoins fondamentaux de nombreux sites Web et applications. Pour les scénarios dans lesquels plusieurs fichiers doivent être téléchargés en même temps, la méthode de téléchargement synchrone traditionnelle est souvent inefficace et prend du temps. Pour cette raison, utiliser PHP pour télécharger plusieurs fichiers de manière asynchrone via HTTP est devenu une solution de plus en plus courante. Cet article analysera en détail comment utiliser le HTTP asynchrone PHP à travers un cas de développement réel.
 Problèmes et solutions courants en matière de communication et de sécurité réseau en C#
Oct 09, 2023 pm 09:21 PM
Problèmes et solutions courants en matière de communication et de sécurité réseau en C#
Oct 09, 2023 pm 09:21 PM
Problèmes courants de communication réseau et de sécurité et solutions en C# À l'ère d'Internet d'aujourd'hui, la communication réseau est devenue un élément indispensable du développement logiciel. En C#, nous rencontrons généralement certains problèmes de communication réseau, tels que la sécurité de la transmission des données, la stabilité de la connexion réseau, etc. Cet article abordera en détail les problèmes courants de communication réseau et de sécurité en C# et fournira les solutions correspondantes et des exemples de code. 1. Problèmes de communication réseau Interruption de la connexion réseau : pendant le processus de communication réseau, la connexion réseau peut être interrompue, ce qui peut entraîner
 Solution d'erreur de requête http 415
Nov 14, 2023 am 10:49 AM
Solution d'erreur de requête http 415
Nov 14, 2023 am 10:49 AM
Solution : 1. Vérifiez le type de contenu dans l'en-tête de la requête ; 2. Vérifiez le format des données dans le corps de la requête ; 3. Utilisez le format de codage approprié. 4. Utilisez la méthode de requête appropriée ;
