

Cet article présente principalement la partie suivante de la série de sept algorithmes de tri classiques de C#, le tri par insertion directe, le tri Hill et le tri par fusion. Il a une certaine valeur de référence. Amis intéressés, vous pouvez vous y référer. 🎜>
Aujourd'hui je vais vous parler des trois derniers tris : le tri par insertion directe, le tri Hill et le tri par fusion.Tri par insertion directe :
Ce type de tri est en fait assez facile à comprendre. Un exemple très réaliste est celui de notre propriétaire. Lorsque nous attrapons une main aléatoire de cartes, Nous devons trier les cartes de poker selon leur taille. Après 30 secondes, les cartes de poker sont triées, 4 3, 5 s, wow... Rappelez-vous comment nous avions trié à ce moment-là. La carte la plus à gauche est 3, la deuxième carte est 5, la troisième carte est encore 3, insérez-la rapidement derrière la première carte, la quatrième carte est encore 3, grande joie, dépêchez-vous Insérez-la après la seconde carte, et la cinquième carte est encore 3. Je suis ravi, haha, un canon est né. Et si ? Les algorithmes sont partout dans la vie et ont déjà été intégrés dans nos vies et dans notre sang. Ce qui suit est une explication de l'image ci-dessus :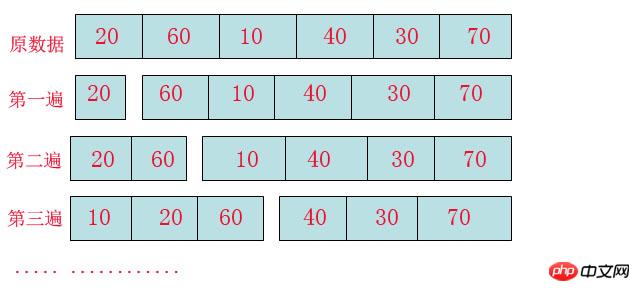
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace InsertSort
{
public class Program
{
static void Main(string[] args)
{
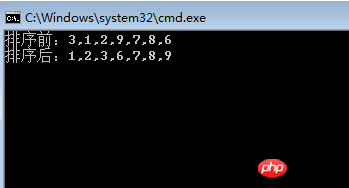
List<int> list = new List<int>() { 3, 1, 2, 9, 7, 8, 6 };
Console.WriteLine("排序前:" + string.Join(",", list));
InsertSort(list);
Console.WriteLine("排序后:" + string.Join(",", list));
}
static void InsertSort(List<int> list)
{
//无须序列
for (int i = 1; i < list.Count; i++)
{
var temp = list[i];
int j;
//有序序列
for (j = i - 1; j >= 0 && temp < list[j]; j--)
{
list[j + 1] = list[j];
}
list[j + 1] = temp;
}
}
}
}
Tri par colline :
Observez le "tri par insertion" : En fait , il n'est pas difficile de constater qu'elle a un défaut : Si les données sont "5, 4, 3, 2, 1", à ce moment nous le ferons Lorsqu'un enregistrement est inséré dans un "bloc ordonné", on estime que nous allons planter, et la position sera déplacée à chaque insertion. À ce stade, l'efficacité du tri par insertion peut être imaginée.
Le shell a amélioré l'algorithme basé sur cette faiblesse et a incorporé une idée appelée "Méthode de tri incrémental de réduction". C'est en fait assez simple, mais quelque chose à noter est :
Les incréments ne sont pas aléatoires, mais suivent un modèle.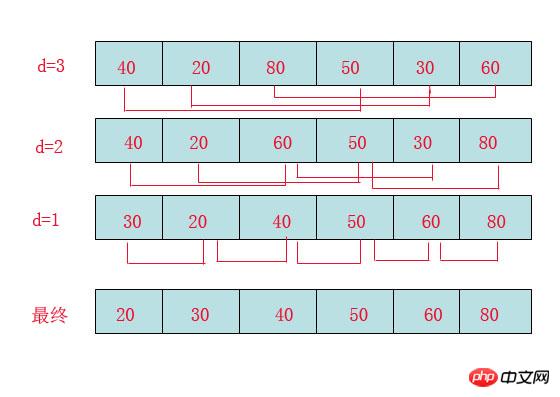
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using System.Diagnostics;
namespace ShellSort
{
public class Program
{
static void Main(string[] args)
{
//5次比较
for (int i = 1; i <= 5; i++)
{
List<int> list = new List<int>();
//插入1w个随机数到数组中
for (int j = 0; j < 10000; j++)
{
Thread.Sleep(1);
list.Add(new Random((int)DateTime.Now.Ticks).Next(10000, 1000000));
}
List<int> list2 = new List<int>();
list2.AddRange(list);
Console.WriteLine("\n第" + i + "次比较:");
Stopwatch watch = new Stopwatch();
watch.Start();
InsertSort(list);
watch.Stop();
Console.WriteLine("\n插入排序耗费的时间:" + watch.ElapsedMilliseconds);
Console.WriteLine("输出前十个数:" + string.Join(",", list.Take(10).ToList()));
watch.Restart();
ShellSort(list2);
watch.Stop();
Console.WriteLine("\n希尔排序耗费的时间:" + watch.ElapsedMilliseconds);
Console.WriteLine("输出前十个数:" + string.Join(",", list2.Take(10).ToList()));
}
}
///<summary>
/// 希尔排序
///</summary>
///<param name="list"></param>
static void ShellSort(List<int> list)
{
//取增量
int step = list.Count / 2;
while (step >= 1)
{
//无须序列
for (int i = step; i < list.Count; i++)
{
var temp = list[i];
int j;
//有序序列
for (j = i - step; j >= 0 && temp < list[j]; j = j - step)
{
list[j + step] = list[j];
}
list[j + step] = temp;
}
step = step / 2;
}
}
///<summary>
/// 插入排序
///</summary>
///<param name="list"></param>
static void InsertSort(List<int> list)
{
//无须序列
for (int i = 1; i < list.Count; i++)
{
var temp = list[i];
int j;
//有序序列
for (j = i - 1; j >= 0 && temp < list[j]; j--)
{
list[j + 1] = list[j];
}
list[j + 1] = temp;
}
}
}
}
Tri par fusion :
Personnellement, le tri que nous pouvons facilement comprendre est fondamentalement O (n^2), et le tri qui est plus difficile à comprendre est fondamentalement O (n^2). C'est N(LogN), donc le tri par fusion est également relativement difficile à comprendre, surtout lorsqu'il s'agit d'écrire le code Il m'a fallu un après-midi entier pour le comprendre, héhé. Premier coup d'oeil à l'image :
第一: “分”, 就是将数组尽可能的分,一直分到原子级别。
第二: “并”,将原子级别的数两两合并排序,最后产生结果。
代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace MergeSort
{
class Program
{
static void Main(string[] args)
{
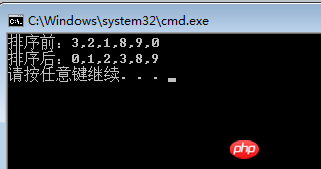
int[] array = { 3, 2, 1, 8, 9, 0 };
MergeSort(array, new int[array.Length], 0, array.Length - 1);
Console.WriteLine(string.Join(",", array));
}
///<summary>
/// 数组的划分
///</summary>
///<param name="array">待排序数组</param>
///<param name="temparray">临时存放数组</param>
///<param name="left">序列段的开始位置,</param>
///<param name="right">序列段的结束位置</param>
static void MergeSort(int[] array, int[] temparray, int left, int right)
{
if (left < right)
{
//取分割位置
int middle = (left + right) / 2;
//递归划分数组左序列
MergeSort(array, temparray, left, middle);
//递归划分数组右序列
MergeSort(array, temparray, middle + 1, right);
//数组合并操作
Merge(array, temparray, left, middle + 1, right);
}
}
///<summary>
/// 数组的两两合并操作
///</summary>
///<param name="array">待排序数组</param>
///<param name="temparray">临时数组</param>
///<param name="left">第一个区间段开始位置</param>
///<param name="middle">第二个区间的开始位置</param>
///<param name="right">第二个区间段结束位置</param>
static void Merge(int[] array, int[] temparray, int left, int middle, int right)
{
//左指针尾
int leftEnd = middle - 1;
//右指针头
int rightStart = middle;
//临时数组的下标
int tempIndex = left;
//数组合并后的length长度
int tempLength = right - left + 1;
//先循环两个区间段都没有结束的情况
while ((left <= leftEnd) && (rightStart <= right))
{
//如果发现有序列大,则将此数放入临时数组
if (array[left] < array[rightStart])
temparray[tempIndex++] = array[left++];
else
temparray[tempIndex++] = array[rightStart++];
}
//判断左序列是否结束
while (left <= leftEnd)
temparray[tempIndex++] = array[left++];
//判断右序列是否结束
while (rightStart <= right)
temparray[tempIndex++] = array[rightStart++];
//交换数据
for (int i = 0; i < tempLength; i++)
{
array[right] = temparray[right];
right--;
}
}
}
}结果图:
ps:
插入排序的时间复杂度为:O(N^2)
希尔排序的时间复杂度为:平均为:O(N^3/2)
最坏:O(N^2)
归并排序时间复杂度为: O(NlogN)
空间复杂度为: O(N)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



