
 développement back-end
Tutoriel Python
Exemple de proxy automatique IP dans la technologie d'exploration Python
développement back-end
Tutoriel Python
Exemple de proxy automatique IP dans la technologie d'exploration Python
Exemple de proxy automatique IP dans la technologie d'exploration Python

Récemment, j'ai l'intention d'explorer des questions d'examen souples sur Internet pour l'examen. J'ai rencontré quelques problèmes lors de l'exploration. L'article suivant présente principalement l'utilisation de Python pour explorer les questions d'examen souples et les informations pertinentes du proxy automatique IP. L'article le présente de manière très détaillée, les amis qui en ont besoin peuvent venir y jeter un œil ci-dessous.
Préface
Récemment, il y a eu un examen de niveau professionnel en matière de logiciels, ci-après appelé examen logiciel afin de mieux réviser et s'y préparer. l'examen, je prévois de récupérer les questions du test doux sur rkpass.cn.
Tout d'abord, laissez-moi vous raconter l'histoire (keng) de la façon dont j'ai exploré les questions d'examen soft. Désormais, je peux capturer automatiquement toutes les questions dans un certain module, comme indiqué ci-dessous :
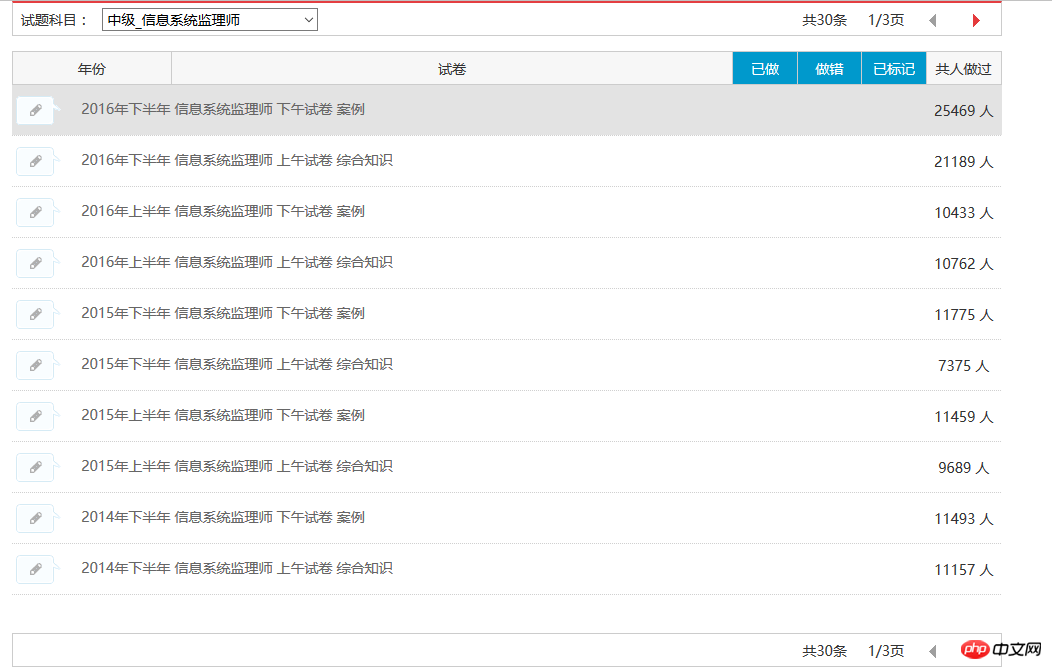
Actuellement, je peux capturer les 30 enregistrements de questions de test du superviseur du système d'information. Le résultat. est comme indiqué ci-dessous :
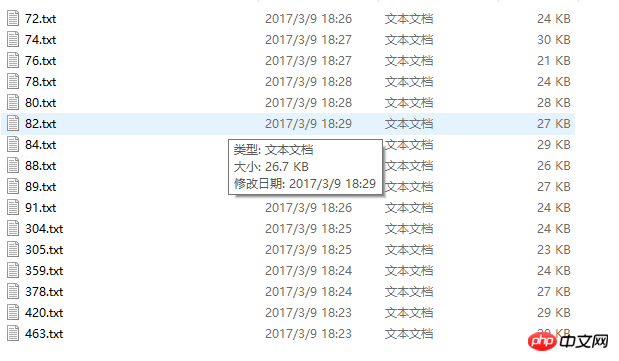
L'image du contenu capturé :

Bien que certaines informations puissent être capturées Cependant, la qualité du code n'est pas élevé.Prenons l'exemple du superviseur du système d'information de capture. Parce que l'objectif est clair et que les paramètres sont clairs, afin de capturer les informations du papier de test en peu de temps, aucune gestion d'exception n'a été effectuée. J'ai rempli le trou pendant longtemps la nuit.
Revenant au sujet, j'écris ce blog aujourd'hui car je suis tombé sur un nouvel écueil. D’après le titre de l’article, on peut deviner qu’il a dû y avoir trop de demandes, l’IP a donc été bloquée par le mécanisme anti-crawler du site.
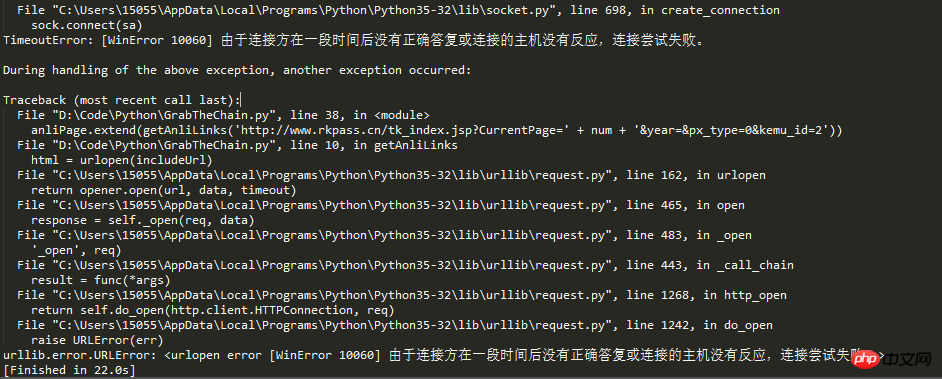
Une personne vivante ne peut pas mourir d'urination. Les actes de nos ancêtres révolutionnaires nous disent qu'en tant que successeurs du socialisme, nous ne pouvons pas succomber aux difficultés, ouvrir des routes à travers les montagnes et construire. ponts sur les rivières, afin de résoudre le problème IP, l'idée du proxy IP est apparue.
Pendant le processus de capture d'informations par les robots d'exploration Web, si la fréquence d'exploration dépasse le seuil défini du site Web, l'accès sera interdit. Habituellement, le mécanisme anti-crawler du site Web identifie les robots d'exploration en fonction de l'adresse IP.
Les développeurs de robots d'exploration doivent donc généralement utiliser deux méthodes pour résoudre ce problème :
1. Ralentissez la vitesse d'exploration et réduisez-la. la pression sur le site cible. Mais cela réduira la quantité d’exploration par unité de temps.
2. La deuxième méthode consiste à briser le mécanisme anti-crawler et à poursuivre l'exploration à haute fréquence en définissant une adresse IP proxy et d'autres moyens. Mais cela nécessite plusieurs adresses IP proxy stables.
Pas grand chose à dire, passons directement au code :
# IP地址取自国内髙匿代理IP网站:www.xicidaili.com/nn/
# 仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
#获取当前页面上的ip
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text)
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
#从抓取到的Ip中随机获取一个ip
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
#国内高匿代理IP网主地址
url = 'http://www.xicidaili.com/nn/'
#请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
#计数器,根据计数器来循环抓取所有页面的ip
num = 0
#创建一个数组,将捕捉到的ip存放到数组
ip_array = []
while num < 1537:
num += 1
ip_list = get_ip_list(url+str(num), headers=headers)
ip_array.append(ip_list)
for ip in ip_array:
print(ip)
#创建随机数,随机取到一个ip
# proxies = get_random_ip(ip_list)
# print(proxies)Capture d'écran des résultats en cours d'exécution :
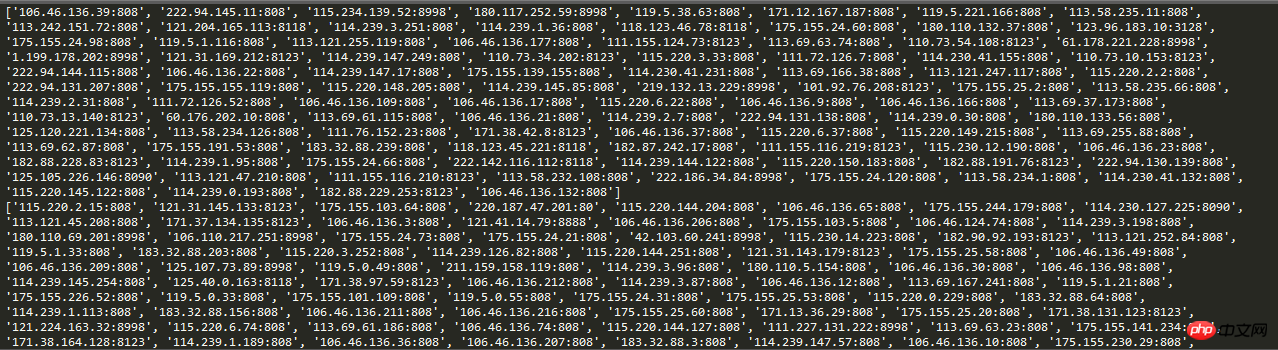
Dans ce De cette manière, lorsque le robot d'exploration demande, définir l'adresse IP de la demande sur une adresse IP automatique peut efficacement éviter le simple blocage et l'adresse IP fixe dans le mécanisme anti-crawler.
------------------------------------------------------ ------ -------------------------------------------- ------ ---------------------------------------
Pour la stabilité du site Web, chacun doit garder la vitesse du robot sous contrôle, après tout, ce n'est pas non plus facile pour les webmasters. Le test de cet article n’a capturé que 17 pages d’adresses IP.
Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Cet article expliquera comment améliorer les performances du site Web en analysant les journaux Apache dans le système Debian. 1. Bases de l'analyse du journal APACH LOG enregistre les informations détaillées de toutes les demandes HTTP, y compris l'adresse IP, l'horodatage, l'URL de la demande, la méthode HTTP et le code de réponse. Dans Debian Systems, ces journaux sont généralement situés dans les répertoires /var/log/apache2/access.log et /var/log/apache2/error.log. Comprendre la structure du journal est la première étape d'une analyse efficace. 2.
 Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python excelle dans les jeux et le développement de l'interface graphique. 1) Le développement de jeux utilise Pygame, fournissant des fonctions de dessin, audio et d'autres fonctions, qui conviennent à la création de jeux 2D. 2) Le développement de l'interface graphique peut choisir Tkinter ou Pyqt. Tkinter est simple et facile à utiliser, PYQT a des fonctions riches et convient au développement professionnel.
 PHP et Python: comparaison de deux langages de programmation populaires
Apr 14, 2025 am 12:13 AM
PHP et Python: comparaison de deux langages de programmation populaires
Apr 14, 2025 am 12:13 AM
PHP et Python ont chacun leurs propres avantages et choisissent en fonction des exigences du projet. 1.Php convient au développement Web, en particulier pour le développement rapide et la maintenance des sites Web. 2. Python convient à la science des données, à l'apprentissage automatique et à l'intelligence artificielle, avec syntaxe concise et adaptée aux débutants.
 Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Cet article traite de la méthode de détection d'attaque DDOS. Bien qu'aucun cas d'application directe de "Debiansniffer" n'ait été trouvé, les méthodes suivantes ne peuvent être utilisées pour la détection des attaques DDOS: technologie de détection d'attaque DDOS efficace: détection basée sur l'analyse du trafic: identification des attaques DDOS en surveillant des modèles anormaux de trafic réseau, tels que la croissance soudaine du trafic, une surtension dans des connexions sur des ports spécifiques, etc. Par exemple, les scripts Python combinés avec les bibliothèques Pyshark et Colorama peuvent surveiller le trafic réseau en temps réel et émettre des alertes. Détection basée sur l'analyse statistique: en analysant les caractéristiques statistiques du trafic réseau, telles que les données
 Certificat NGINX SSL Mise à jour du tutoriel Debian
Apr 13, 2025 am 07:21 AM
Certificat NGINX SSL Mise à jour du tutoriel Debian
Apr 13, 2025 am 07:21 AM
Cet article vous guidera sur la façon de mettre à jour votre certificat NGINXSSL sur votre système Debian. Étape 1: Installez d'abord CERTBOT, assurez-vous que votre système a des packages CERTBOT et Python3-CERTBOT-NGINX installés. Si ce n'est pas installé, veuillez exécuter la commande suivante: Sudoapt-getUpDaSuDoapt-GetInstallCertBotpyThon3-Certerbot-Nginx Étape 2: Obtenez et configurez le certificat Utilisez la commande Certbot pour obtenir le certificat LETSCRYPT et configure
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Pour maximiser l'efficacité de l'apprentissage de Python dans un temps limité, vous pouvez utiliser les modules DateTime, Time et Schedule de Python. 1. Le module DateTime est utilisé pour enregistrer et planifier le temps d'apprentissage. 2. Le module de temps aide à définir l'étude et le temps de repos. 3. Le module de planification organise automatiquement des tâches d'apprentissage hebdomadaires.
 Comment configurer le serveur HTTPS dans Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Comment configurer le serveur HTTPS dans Debian OpenSSL
Apr 13, 2025 am 11:03 AM
La configuration d'un serveur HTTPS sur un système Debian implique plusieurs étapes, notamment l'installation du logiciel nécessaire, la génération d'un certificat SSL et la configuration d'un serveur Web (tel qu'Apache ou Nginx) pour utiliser un certificat SSL. Voici un guide de base, en supposant que vous utilisez un serveur Apacheweb. 1. Installez d'abord le logiciel nécessaire, assurez-vous que votre système est à jour et installez Apache et OpenSSL: SudoaptupDaSuDoaptupgradeSudoaptinsta
