

L'éditeur suivant vous proposera un article sur la façon de simuler des requêtes HTTP pour réaliser le fonctionnement automatique et la collecte de données des pages Web. L'éditeur pense que c'est plutôt bien, alors je vais le partager avec vous maintenant et le donner comme référence. Venez jeter un œil avec l'éditeur
Avant-propos
Les pages Web peuvent être divisées en catégories de fourniture d'informations et d'opérations commerciales telles que la fourniture d'informations. actualités, actions, cotations et autres sites Web. Opérations commerciales telles que la salle d'affaires en ligne, OA, etc. Bien sûr, il existe de nombreux sites Web qui possèdent les deux propriétés en même temps. Des sites Web tels que Weibo, Douban et Taobao fournissent non seulement des informations, mais mettent également en œuvre certaines activités.
Les méthodes ordinaires d'accès à Internet sont généralement des opérations manuelles (cela ne nécessite aucune explication : D). Mais parfois, les opérations manuelles peuvent ne pas suffire, comme l'exploration d'une grande quantité de données sur Internet, la surveillance des modifications d'une page en temps réel, les opérations par lots (telles que la publication par lots sur Weibo, les achats par lots sur Taobao), le brossage des commandes, etc. En raison du grand nombre d’opérations et des opérations répétitives, les opérations manuelles sont inefficaces et sujettes aux erreurs. À ce stade, vous pouvez utiliser un logiciel pour fonctionner automatiquement.
J'ai développé de nombreux logiciels de ce type, notamment des robots d'exploration Web et des entreprises d'opérations automatiques par lots. L'une des fonctions principales utilisées est de simuler les requêtes HTTP. Bien entendu, le protocole HTTPS est parfois utilisé et le site Web doit généralement être connecté avant de pouvoir effectuer d'autres opérations. Le point le plus important est de comprendre le processus métier du site Web, c'est-à-dire de savoir quand et comment soumettre. vers quelle page afin de réaliser une certaine opération. Quelles données ? Enfin, pour extraire les données ou connaître les résultats de l'opération, vous devez également analyser le code HTML. Cet article les expliquera un par un.
Cet article utilise le langage C# pour afficher le code. Bien entendu, il peut également être implémenté dans d'autres langages. Prenons l'exemple de la connexion à JD.com.
La simulation de requêtes HTTP
La simulation C# des requêtes HTTP nécessite l'utilisation des classes suivantes :
•WebRequest
•HttpWebRequest
•HttpWebResponse
•Stream
Créez d'abord un objet de requête (HttpWebRequest), définissez les informations d'en-tête pertinentes, puis envoyez la requête (s'il s'agit d'un POST, écrivez également les données du formulaire au flux réseau), si l'adresse cible est accessible, un objet de réponse (HttpWebResponse) sera obtenu et le résultat du retour pourra être lu à partir du flux réseau de l'objet correspondant.
L'exemple de code est le suivant :
String contentType = "application/x-www-form-urlencoded";
String accept = "image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/x-silverlight,
application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-ms-application, application/x-ms-xbap,
application/vnd.ms-xpsdocument, application/xaml+xml, application/x-silverlight-2-b1, */*";
String userAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36";
public String Get(String url, String encode = DEFAULT_ENCODE)
{
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "GET";
var html = ReadHtml(request, encode);
return html;
}
public String Post(String url, String param, String encode = DEFAULT_ENCODE)
{
Encoding encoding = System.Text.Encoding.UTF8;
byte[] data = encoding.GetBytes(param);
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "POST";
request.ContentLength = data.Length;
var outstream = request.GetRequestStream();
outstream.Write(data, 0, data.Length);
var html = ReadHtml(request, encode);
return html;
}
private void InitHttpWebRequestHeaders(HttpWebRequest request)
{
request.ContentType = contentType;
request.Accept = accept;
request.UserAgent = userAgent;
}
private String ReadHtml(HttpWebRequest request, String encode)
{
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.GetEncoding(encode));
String content = reader.ReadToEnd();
reader.Close();
stream.Close();
return content;
}On peut voir que la plupart des codes des méthodes Get et Post sont similaire, donc les codes sont L'encapsulation extrait le même code qu'une nouvelle fonction.
Demande HTTPS
Lorsque le site Web utilise le protocole https, l'erreur suivante peut se produire dans le code ci-dessus :
The underlying connection was closed: Could not establish trust relationship for
La raison est une erreur de certificat. Lors de son ouverture avec un navigateur, la page suivante apparaîtra :
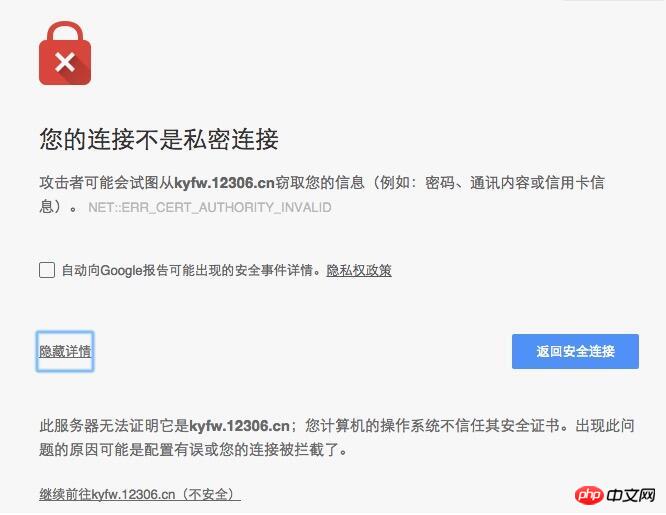
Lorsque vous cliquez sur. continuez vers xxx.xx (dangereux), vous pouvez continuer à ouvrir la page Web. Dans le programme, il vous suffit de simuler cette étape pour continuer. En C#, il vous suffit de définir le proxy ServicePointManager.ServerCertificateValidationCallback et de renvoyer true directement dans la méthode proxy.
private HttpWebRequest CreateHttpWebRequest(String url)
{
HttpWebRequest request;
if (IsHttpsProtocol(url))
{
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(CheckValidationResult);
request = WebRequest.Create(url) as HttpWebRequest;
request.ProtocolVersion = HttpVersion.Version10;
}
else
{
request = WebRequest.Create(url) as HttpWebRequest;
}
return request;
}
private HttpWebRequest CreateHttpWebRequest(String url)
{
HttpWebRequest request;
if (IsHttpsProtocol(url))
{
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(CheckValidationResult);
request = WebRequest.Create(url) as HttpWebRequest;
request.ProtocolVersion = HttpVersion.Version10;
}
else
{
request = WebRequest.Create(url) as HttpWebRequest;
}
return request;
}De cette façon, vous pouvez accéder normalement aux sites Web https.
Enregistrer les cookies pour l'authentification de l'identité
Certains sites Web nécessitent une connexion pour effectuer l'étape suivante, comme les achats sur JD.com où vous devez d'abord vous connecter. Le serveur du site Web utilise des sessions pour enregistrer les utilisateurs clients. Chaque session correspond à un utilisateur, et le code précédent rétablira une session à chaque fois qu'une requête est créée. Même si la connexion réussit, la connexion sera invalide car une nouvelle connexion est créée lors de l'étape suivante. A ce moment, il faut trouver un moyen de faire croire au serveur que cette série de requêtes proviennent de la même session.
Le client ne dispose que de Cookies. Afin de faire savoir au serveur à quelle session correspond le client lors de la prochaine requête, il y aura un enregistrement de l'ID de session dans les Cookies. Par conséquent, tant que les cookies sont les mêmes, il s’agit du même utilisateur sur le serveur.
Vous devez utiliser CookieContainer pour le moment. Comme son nom l'indique, il s'agit d'un conteneur de cookies. HttpWebRequest possède une propriété CookieContainer. Tant que les cookies de chaque requête sont enregistrés dans CookieContainer, l'attribut CookieContainer de HttpWebRequest est défini sur la requête suivante. Puisque les cookies sont les mêmes, il s'agit du même utilisateur sur le serveur.
public String Get(String url, String encode = DEFAULT_ENCODE)
{
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "GET";
request.CookieContainer = cookieContainer;
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
foreach (Cookie c in response.Cookies)
{
cookieContainer.Add(c);
}
}Site Web d'analyse et de débogage
Ce qui précède réalise des requêtes HTTP simulées. au final, l'important c'est la station d'analyse. La situation habituelle est qu’il n’y a pas de documentation, qu’aucun développeur de site Web n’est trouvé et que l’exploration commence à partir d’une boîte noire. Il existe de nombreux outils d'analyse. Il est recommandé d'utiliser le plug-in Chrome+ Advanced Rest Client. Les outils de développement de Chrome nous permettent de savoir quelles opérations et requêtes sont effectuées en arrière-plan lors de l'ouverture d'une page Web. Advanced Rest Client peut simuler l'envoi de requêtes.
Par exemple, lors de la connexion à JD.com, les données suivantes seront soumises :
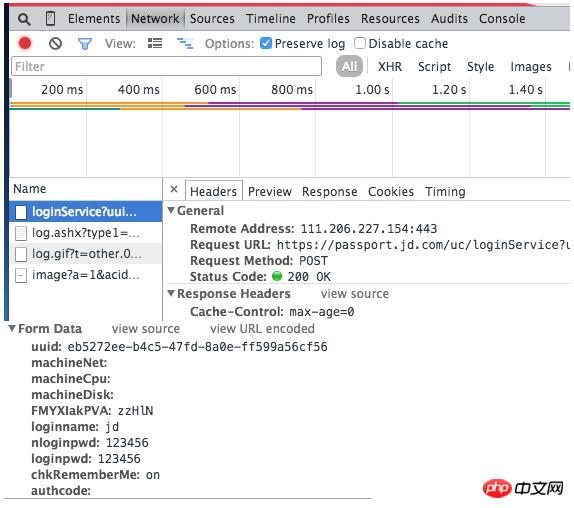
On constate également que le mot de passe de Jingdong est effectivement transmis en texte clair, ce qui est très inquiétant pour la sécurité !
Vous pouvez également voir les données renvoyées :

Les données renvoyées sont des données JSON, mais u8d26, qu'est-ce que c'est ? En fait, il s'agit d'un encodage Unicode. Vous pouvez utiliser l'outil de conversion d'encodage Unicode pour le convertir en texte lisible. Par exemple, le résultat renvoyé cette fois est : le nom du compte et le mot de passe ne correspondent pas, veuillez le saisir à nouveau.
Analyser HTML
Les données obtenues par requête HTTP sont généralement au format HTML, et parfois elles peuvent être Json ou XML. L'analyse est nécessaire pour extraire des données utiles. Les composants qui analysent le HTML sont :
•HTML Parser. Disponible sur plusieurs plateformes telles que Java/C#/Python. Je ne l'ai pas utilisé depuis longtemps.
•HtmlAgilityPack. En analysant HMTL via XPath. Utilisé tout le temps. Pour les didacticiels XPath, vous pouvez consulter les didacticiels XPath de W3School.
Conclusion
Cet article présente les compétences requises pour développer des opérations de page Web automatiques simulées, de la simulation de requêtes HTTP/HTTPS aux cookies, et analyser des sites Web, analyser le HTML. Le code est destiné à illustrer l'utilisation et n'est pas un code complet et ne peut pas être exécuté directement.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles sont les technologies de collecte de données ?
Quelles sont les technologies de collecte de données ?
 Comment résoudre les caractères chinois tronqués de Tomcat
Comment résoudre les caractères chinois tronqués de Tomcat
 HONOR est-il Huawei ?
HONOR est-il Huawei ?
 MySQL supprime la procédure stockée
MySQL supprime la procédure stockée
 Comment supprimer vos propres œuvres sur TikTok
Comment supprimer vos propres œuvres sur TikTok
 Utilisation de la liste déroulante
Utilisation de la liste déroulante
 Que signifient les caractères pleine chasse ?
Que signifient les caractères pleine chasse ?
 Que dois-je faire si mon iPad ne peut pas être chargé ?
Que dois-je faire si mon iPad ne peut pas être chargé ?
 Mise à niveau du Samsung s5830
Mise à niveau du Samsung s5830








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



