

Utilisez le module xml.etree.ElementTree comme suit pour analyser les fichiers XML. Le module ElementTree fournit deux classes pour atteindre cet objectif :
ElementTree représente l'intégralité du fichier XML (une structure arborescente)
L'élément représente un élément (nœud) dans l'arborescence
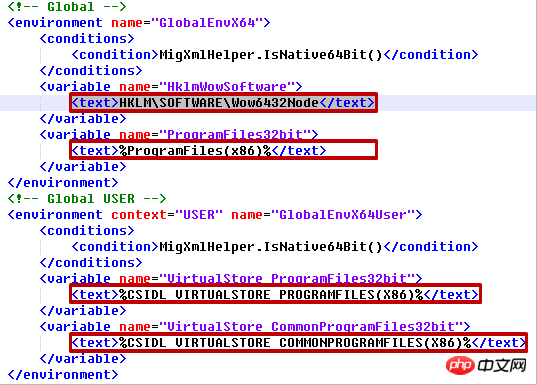
On exploite le fichier XML suivant : migapp.xml

Nous pouvons importer le module ElementTree comme suit : import xml.etree.ElementTree as ET
Ou nous pouvons uniquement importer l'analyseur parse : from xml.etree.ElementTree import parse
Vous devez d'abord ouvrir un fichier XML. Pour les fichiers locaux, utilisez la fonction open S'il s'agit d'un fichier Internet, utilisez urlopen:
f = open( ' migapp.xml ' , ' rt ' , encoding. = 'utf -8' )
Ensuite, analysez le XML.
1.1 Analyser l'élément racine
tree = ET.parse(f) root = tree.getroot() print('root.tag =', root.tag) print('root.attrib =', root.attrib)

1.2 Analyser la racine Fils de
for child in root: # 仅可以解析出root的儿子,不能解析出root的子孙
print(child.tag)
print(child.attrib) # attrib is a dict
1.3 Résolution des descendants de racine par index
print(root[1][1].tag) print(root[1][1].text)

1.4 Analyser itérativement tous les éléments spécifiés
for element in root.iter('environment'):
print(element.attrib)
1.5 Plusieurs méthodes utiles
# element.findall()解析出指定element的所有儿子
# element.find()解析出指定element的第一个儿子
# element.get()解析出指定element的属性attrib
for environment in root.findall('environment'):
first_variable = environment.find('variable')
print(first_variable.get('name'))
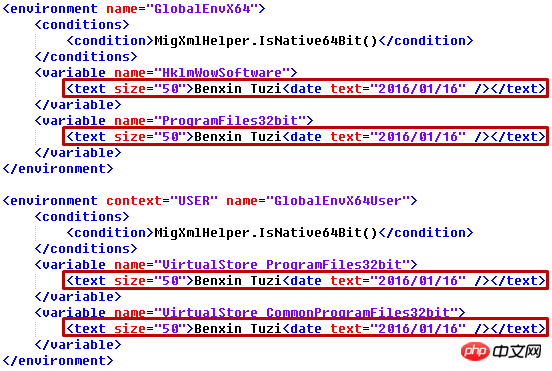
Supposons que nous devions ajouter un attribut size="50" à chaque élément de texte et modifier son texte en "Benxin Tuzi", ajoutez un élément enfant date="2016/01/16"
for text in root.iter('text'):
text.set('size', '50')
text.text = 'Benxin Tuzi'
text.append(ET.Element('date', attrib={}, text='2016/01/16'))
tree.write('output.xml')migapp.xml Partie dans :
output.xml :
En effet, lors de l'importation, il recherchera d'abord dans le chemin actuel, à ce moment-là, on constate que le module xml.py existe, et le xml.py que nous avons écrit nous-mêmes n'est bien sûr pas un package
Remarque : Si vous ne parvenez toujours pas à interpréter correctement xml.py après l'avoir supprimé, c'est parce que xml.pyc est également généré dans le chemin actuel et que la priorité de ce fichier est supérieure à xml.py , donc l'interpréteur donne toujours la priorité à xml.pyc , le fichier doit donc également être supprimé pour réussir à résoudre le problème. Conclusion : Essayez de ne pas faire en sorte que le nom du fichier ait le même nom que le nom du package ou le nom du module, même si vous n'utilisez pas le module ou le package dans le script, sinon des erreurs étranges peut survenir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



