

Cet article utilise principalement plusieurs algorithmes de tri couramment utilisés qui sont visuellement intuitifs et ont une certaine valeur de référence. Les amis intéressés peuvent se référer à
pour découvrir intuitivement plusieurs algorithmes de tri couramment utilisés. Le contenu spécifique est le suivant
1 Tri rapide
Réorganisez la séquence et placez tous les éléments plus petits que la valeur du pivot devant le pivot, tous les éléments plus grand que la valeur de base sont placés derrière la base (le même nombre peut aller des deux côtés). Une fois cette partition terminée, la base se trouve au milieu de la séquence. C'est ce qu'on appelle une opération de partition.
Triez récursivement le sous-tableau d'éléments plus petits que la valeur de base et le sous-tableau d'éléments supérieurs à la valeur de base.
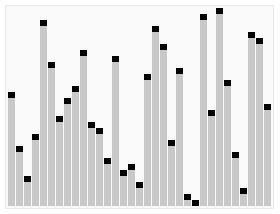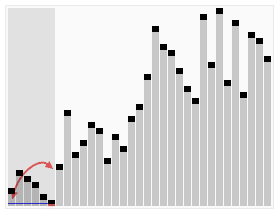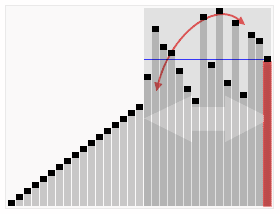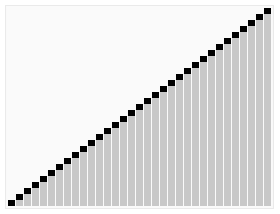
2 Tri par fusion
Le tri par fusion (Merge sort, traduction taïwanaise : merge sort) est un algorithme de tri efficace basé sur des opérations de fusion. Cet algorithme est une application très typique utilisant la méthode diviser pour mieux régner (pide and conquer) Étapes : Appliquer l'espace pour que sa taille soit la somme de deux séquences triées, et l'espace est Pour stocker la séquence fusionnée
Définir deux pointeurs, les positions initiales sont les positions de départ des deux séquences triées
Comparez les éléments pointés par les deux pointeurs, sélectionnez l'élément relativement petit et placez-le dans l'espace de fusion , et déplacez le pointeur vers la position suivante
Répétez l'étape 3 jusqu'à ce qu'un certain pointeur atteigne la fin de la séquence
Copiez tous les éléments restants de l'autre séquence directement à la fin de la séquence fusionnée

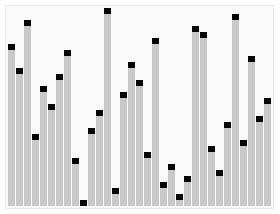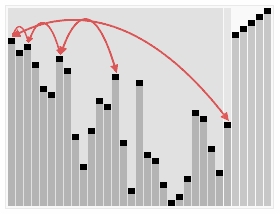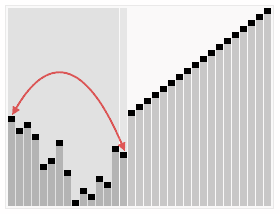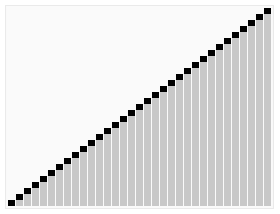
3 Tri par tas
4 Tri par sélection

Tri à 5 bulles
Faites de même pour chaque paire d'éléments adjacents, en commençant par la première paire et en terminant par la dernière paire. À ce stade, le dernier élément doit être le plus grand nombre.
Répétez les étapes ci-dessus pour tous les éléments sauf le dernier.
Continuez à répéter les étapes ci-dessus pour de moins en moins d'éléments à chaque fois jusqu'à ce qu'il n'y ait plus de paires de nombres à comparer.

6 Tri par insertion
La description de l'algorithme de Tri par Insertion est un algorithme de tri simple et intuitif. Il fonctionne en construisant une séquence ordonnée. Pour les données non triées, il analyse d'arrière en avant dans la séquence triée pour trouver la position correspondante et l'insérer. Dans la mise en œuvre du tri par insertion, le tri sur place est généralement utilisé (c'est-à-dire un tri qui utilise uniquement l'espace supplémentaire O(1). Par conséquent, pendant le processus d'analyse d'arrière en avant, les éléments triés doivent être triés de manière répétée et progressive). décalé vers l'arrière, fournissant un espace d'insertion pour le dernier élément.
Étapes :
Commencer par le premier élément, qui peut être considéré comme trié
Sortir l'élément suivant et scanner d'arrière en avant dans la séquence des éléments triés
Si l'élément (trié) est supérieur au nouvel élément, déplacez l'élément à la position suivante
Répétez l'étape 3 jusqu'à ce que vous trouviez une position où l'élément trié est inférieur ou égal au nouvel élément
Insérez le nouvel élément dans cette position Répétez l'étape 2 dans
7 Tri par collines
Introduction :
Tri par collines, également appelé décroissant L'algorithme de tri incrémentiel est une version améliorée, rapide et stable, du tri par insertion.
Le tri Hill propose une méthode améliorée basée sur les deux propriétés suivantes du tri par insertion :
Le tri par insertion est très efficace lorsqu'on opère sur des données qui ont presque été triées, c'est-à-dire qu'il peut atteindre Le efficacité du tri linéaire
Mais le tri par insertion est généralement inefficace, car le tri par insertion ne peut déplacer les données qu'un bit à la fois
Effet de tri :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



