
 développement back-end
Tutoriel Python
Explication détaillée des codes de tri courants en python
développement back-end
Tutoriel Python
Explication détaillée des codes de tri courants en python
Explication détaillée des codes de tri courants en python

Cet article présente principalement en détail le didacticiel de base de l'algorithme python, qui a une certaine valeur de référence. Les amis intéressés peuvent s'y référer
Avant-propos : le test écrit de Tencent a reçu 10 000 points au cours des deux premiers jours. J'ai l'impression d'avoir perdu deux jours à aller sur Niuke.com pour poser les questions... Ce blog présente plusieurs algorithmes de tri simples/communs, qui sont triés.
Complexité temporelle
(1) Fréquence temporelleLe temps nécessaire pour exécuter un algorithme ne peut pas être calculé théoriquement, Vous devez exécuter le test sur votre machine pour savoir. Mais il est impossible et inutile pour nous de tester chaque algorithme sur l’ordinateur. Il nous suffit de savoir quel algorithme prend le plus de temps et quel algorithme prend le moins de temps. Et le temps que prend un algorithme est proportionnel au nombre d’exécutions d’instructions dans l’algorithme. Quel que soit l’algorithme qui a le plus d’instructions exécutées, cela prend plus de temps. Le nombre d'exécutions d'instructions dans un algorithme est appelé fréquence d'instruction ou fréquence temporelle. Notons-le comme T(n).
(2) Complexité temporelle Dans la fréquence temporelle que nous venons de mentionner, n est appelé l'échelle du problème. Lorsque n continue de changer, la fréquence temporelle T(n) change également constamment. . Mais parfois, nous voulons savoir quel modèle cela montre lorsqu’il change. Pour cela, nous introduisons la notion de complexité temporelle. De manière générale, le nombre de fois où les opérations de base de l'algorithme sont répétées est fonction de la taille du problème n, représentée par T(n). S'il existe une fonction auxiliaire f(n), fait en sorte que lorsque n tend vers l'infini, la valeur limite de T(n)/f(n) est une constante qui n'est pas égale à zéro, alors f(n) est dit fonction du même ordre de grandeur que T( n). Notée T(n)=O(f(n)), O(f(n)) est appelée la complexité temporelle asymptotique de l'algorithme, ou complexité temporelle en abrégé.
Temps exponentiel
fait référence au temps de calcul m(n) nécessaire pour résoudre un problème, en fonction de la taille du données d'entrée Et cela croît de façon exponentielle (c'est-à-dire que la quantité de données d'entrée augmente de manière linéaire et le temps passé augmentera de façon exponentielle)
for (i=1; i<=n; i++) x++; for (i=1; i<=n; i++) for (j=1; j<=n; j++) x++;
Le temps du premier pour la boucle est complexe Le degré est Ο(n), la complexité temporelle de la seconde boucle for est Ο(n2), alors la complexité temporelle de l'algorithme entier est Ο(n+n2)=Ο(n2).
Temps constant
Si la limite supérieure d'un algorithme est indépendante de la taille d'entrée, on dit qu'il a un temps constant, noté temps. Un exemple est l’accès à un seul élément d’un tableau, car y accéder ne nécessite qu’une seule instruction. Cependant, trouver le plus petit élément dans un tableau non ordonné ne l’est pas, car cela nécessite de parcourir tous les éléments pour trouver la plus petite valeur. Il s'agit d'une opération temporelle linéaire, ou temps. Mais si le nombre d’éléments est connu à l’avance et que ce nombre est supposé rester constant, on peut également dire que l’opération a un temps constant.
Temps logarithmique
Si l'algorithme T(n) =O(logn), alors Il on dit qu'il a un temps logarithmique
Les algorithmes courants avec temps logarithmique incluent les opérations liées aux arbres binaires et la recherche binaire.
L'algorithme de temps logarithmique est très efficace, car à chaque entrée supplémentaire, le temps de calcul supplémentaire requis devient plus petit.
Couper récursivement une chaîne en deux et la sortie est un exemple simple de fonction dans cette catégorie. Cela prend un temps O(log n) car nous coupons la chaîne en deux avant chaque sortie. Cela signifie que si nous voulons augmenter le nombre de sorties, nous devons doubler la longueur de la chaîne.
Temps linéaire
Si la complexité temporelle d'un algorithme est O(n), alors l'algorithme est dit avoir un temps linéaire temps, ou O(n) temps. De manière informelle, cela signifie que pour des entrées suffisamment volumineuses, le temps d'exécution augmente linéairement avec la taille de l'entrée. Par exemple, un programme qui calcule la somme de tous les éléments d’une liste prend un temps proportionnel à la longueur de la liste.
1. Algorithme de bulles
Idée de base :
Dans un groupe de nombres à trier, la paire actuelle n'a pas été triée pourtant, tous les nombres dans la plage de séquence sont comparés et ajustés de haut en bas, de sorte que le plus grand nombre diminue et le plus petit nombre augmente. Autrement dit : chaque fois que deux nombres adjacents sont comparés et s'avèrent être dans l'ordre opposé aux exigences de commande, ils sont échangés.
Exemple de tri à bulles :

Mise en œuvre de l'algorithme :
def bubble(array):
for i in range(len(array)-1):
for j in range(len(array)-1-i):
if array[j] > array[j+1]: # 如果前一个大于后一个,则交换
temp = array[j]
array[j] = array[j+1]
array[j+1] = temp
if __name__ == "__main__":
array = [265, 494, 302, 160, 370, 219, 247, 287,
354, 405, 469, 82, 345, 319, 83, 258, 497, 423, 291, 304]
print("------->排序前<-------")
print(array)
bubble(array)
print("------->排序后<-------")
print(array)Sortie :
------->Avant le tri<-------
[265, 494, 302, 160, 370, 219, 247, 287, 354, 405, 469, 82, 345, 319, 83, 258, 497, 423, 291, 304]
------->Après le tri<-- --- --
[82, 83, 160, 219, 247, 258, 265, 287, 291, 302, 304, 319, 345, 354, 370, 405, 423, 469, 494, 497]
Explication :
以随机产生的五个数为例: li=[354,405,469,82,345]
冒泡排序是怎么实现的?
首先先来个大循环,每次循环找出最大的数,放在列表的最后面。在上面的例子中,第一次找出最大数469,将469放在最后一个,此时我们知道
列表最后一个肯定是最大的,故还需要再比较前面4个数,找出4个数中最大的数405,放在列表倒数第二个......
5个数进行排序,需要多少次的大循环?? 当然是4次啦!同理,若有n个数,需n-1次大循环。
现在你会问我: 第一次找出最大数469,将469放在最后一个??怎么实现的??
嗯,(在大循环里)用一个小循环进行两数比较,首先354与405比较,若前者较大,需要交换数;反之不用交换。
当469与82比较时,需交换,故列表倒数第二个为469;469与345比较,需交换,此时最大数469位于列表最后一个啦!
难点来了,小循环需要多少次??
进行两数比较,从列表头比较至列表尾,此时需len(array)-1次!! 但是,嗯,举个例子吧: 当大循环i为3时,说明此时列表的最后3个数已经排好序了,不必进行两数比较,故小循环需len(array)-1-3. 即len(array)-1-i
冒泡排序复杂度:
时间复杂度: 最好情况O(n), 最坏情况O(n^2), 平均情况O(n^2)
空间复杂度: O(1)
稳定性: 稳定
简单选择排序的示例:

二、选择排序
The selection sort works as follows: you look through the entire array for the smallest element, once you find it you swap it (the smallest element) with the first element of the array. Then you look for the smallest element in the remaining array (an array without the first element) and swap it with the second element. Then you look for the smallest element in the remaining array (an array without first and second elements) and swap it with the third element, and so on. Here is an example
基本思想:
在要排序的一组数中,选出最小(或者最大)的一个数与第1个位置的数交换;然后在剩下的数当中再找最小(或者最大)的与第2个位置的数交换,依次类推,直到第n-1个元素(倒数第二个数)和第n个元素(最后一个数)比较为止。
简单选择排序的示例:
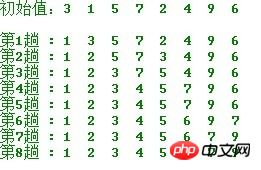
算法实现:
def select_sort(array): for i in range(len(array)-1): # 找出最小的数放与array[i]交换 for j in range(i+1, len(array)): if array[i] > array[j]: temp = array[i] array[i] = array[j] array[j] = temp if __name__ == "__main__": array = [265, 494, 302, 160, 370, 219, 247, 287, 354, 405, 469, 82, 345, 319, 83, 258, 497, 423, 291, 304] print(array) select_sort(array) print(array)
选择排序复杂度:
时间复杂度: 最好情况O(n^2), 最坏情况O(n^2), 平均情况O(n^2)
空间复杂度: O(1)
稳定性: 不稳定
举个例子:序列5 8 5 2 9, 我们知道第一趟选择第1个元素5会与2进行交换,那么原序列中两个5的相对先后顺序也就被破坏了。
排序效果:

三、直接插入排序
插入排序(Insertion Sort)的基本思想是:将列表分为2部分,左边为排序好的部分,右边为未排序的部分,循环整个列表,每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子序列中的适当位置,直到全部记录插入完成为止。

插入排序非常类似于整扑克牌。
在开始摸牌时,左手是空的,牌面朝下放在桌上。接着,一次从桌上摸起一张牌,并将它插入到左手一把牌中的正确位置上。为了找到这张牌的正确位置,要将它与手中已有的牌从右到左地进行比较。无论什么时候,左手中的牌都是排好序的。
也许你没有意识到,但其实你的思考过程是这样的:现在抓到一张7,把它和手里的牌从右到左依次比较,7比10小,应该再往左插,7比5大,好,就插这里。为什么比较了10和5就可以确定7的位置?为什么不用再比较左边的4和2呢?因为这里有一个重要的前提:手里的牌已经是排好序的。现在我插了7之后,手里的牌仍然是排好序的,下次再抓到的牌还可以用这个方法插入。编程对一个数组进行插入排序也是同样道理,但和插入扑克牌有一点不同,不可能在两个相邻的存储单元之间再插入一个单元,因此要将插入点之后的数据依次往后移动一个单元。
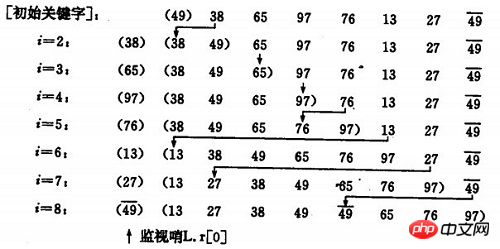
设监视哨是我大一在书上有看过,大家忽视上图的监视哨。
算法实现:
import time
def insertion_sort(array):
for i in range(1, len(array)): # 对第i个元素进行插入,i前面是已经排序好的元素
position = i # 要插入数的下标
current_val = array[position] # 把当前值存下来
# 如果前一个数大于要插入数,则将前一个数往后移,比如5,8,12,7;要将7插入,先把7保存下来,比较12与7,将12往后移
while position > 0 and current_val < array[position-1]:
array[position] = array[position-1]
position -= 1
else: # 当position为0或前一个数比待插入还小时
array[position] = current_val
if __name__ == "__main__":
array = [92, 77, 67, 8, 6, 84, 55, 85, 43, 67]
print(array)
time_start = time.time()
insertion_sort(array)
time_end = time.time()
print("time: %s" % (time_end-time_start))
print(array)输出:
[92, 77, 67, 8, 6, 84, 55, 85, 43, 67]
time: 0.0
[6, 8, 43, 55, 67, 67, 77, 84, 85, 92]
如果碰见一个和插入元素相等的,那么插入元素把想插入的元素放在相等元素的后面。所以,相等元素的前后顺序没有改变,从原无序序列出去的顺序就是排好序后的顺序,所以插入排序是稳定的。
直接插入排序复杂度:
时间复杂度: 最好情况O(n), 最坏情况O(n^2), 平均情况O(n^2)
空间复杂度: O(1)
稳定性: 稳定
个人感觉直接插入排序算法难度是选择/冒泡算法是两倍……
四、快速排序
快速排序示例:
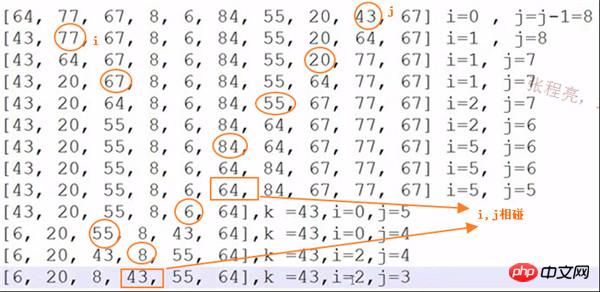

算法实现:
def quick_sort(array, left, right):
'''
:param array:
:param left: 列表的第一个索引
:param right: 列表最后一个元素的索引
:return:
'''
if left >= right:
return
low = left
high = right
key = array[low] # 第一个值,即基准元素
while low < high: # 只要左右未遇见
while low < high and array[high] > key: # 找到列表右边比key大的值 为止
high -= 1
# 此时直接 把key跟 比它大的array[high]进行交换
array[low] = array[high]
array[high] = key
while low < high and array[low] <= key: # 找到key左边比key大的值,这里为何是<=而不是<呢?你要思考。。。
low += 1
# 找到了左边比k大的值 ,把array[high](此时应该刚存成了key) 跟这个比key大的array[low]进行调换
array[high] = array[low]
array[low] = key
quick_sort(array, left, low-1) # 最后用同样的方式对分出来的左边的小组进行同上的做法
quick_sort(array,low+1, right) # 用同样的方式对分出来的右边的小组进行同上的做法
if __name__ == '__main__':
array = [8,4,1, 14, 6, 2, 3, 9,5, 13, 7,1, 8,10, 12]
print("-------排序前-------")
print(array)
quick_sort(array, 0, len(array)-1)
print("-------排序后-------")
print(array)输出:
-------排序前-------
[8, 4, 1, 14, 6, 2, 3, 9, 5, 13, 7, 1, 8, 10, 12]
-------排序后-------
[1, 1, 2, 3, 4, 5, 6, 7, 8, 8, 9, 10, 12, 13, 14]
22行那里如果不加=号,当排序64,77,64是会死循环,此时key=64, 最后的64与开始的64交换,开始的64与本最后的64交换…… 无穷无尽
直接插入排序复杂度:
时间复杂度: 最好情况O(nlogn), 最坏情况O(n^2), 平均情况O(nlogn)
下面空间复杂度是看别人博客的,我也不大懂了……改天再研究下。
最优的情况下空间复杂度为:O(logn);每一次都平分数组的情况
最差的情况下空间复杂度为:O( n );退化为冒泡排序的情况
稳定性:不稳定
快速排序效果:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP est principalement la programmation procédurale, mais prend également en charge la programmation orientée objet (POO); Python prend en charge une variété de paradigmes, y compris la POO, la programmation fonctionnelle et procédurale. PHP convient au développement Web, et Python convient à une variété d'applications telles que l'analyse des données et l'apprentissage automatique.
 Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
PHP convient au développement Web et au prototypage rapide, et Python convient à la science des données et à l'apprentissage automatique. 1.Php est utilisé pour le développement Web dynamique, avec une syntaxe simple et adapté pour un développement rapide. 2. Python a une syntaxe concise, convient à plusieurs champs et a un écosystème de bibliothèque solide.
 Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
 Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python convient plus aux débutants, avec une courbe d'apprentissage en douceur et une syntaxe concise; JavaScript convient au développement frontal, avec une courbe d'apprentissage abrupte et une syntaxe flexible. 1. La syntaxe Python est intuitive et adaptée à la science des données et au développement back-end. 2. JavaScript est flexible et largement utilisé dans la programmation frontale et côté serveur.
 Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
 PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP est originaire en 1994 et a été développé par Rasmuslerdorf. Il a été utilisé à l'origine pour suivre les visiteurs du site Web et a progressivement évolué en un langage de script côté serveur et a été largement utilisé dans le développement Web. Python a été développé par Guidovan Rossum à la fin des années 1980 et a été publié pour la première fois en 1991. Il met l'accent sur la lisibilité et la simplicité du code, et convient à l'informatique scientifique, à l'analyse des données et à d'autres domaines.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
