
 base de données
tutoriel mysql
Comment optimiser les performances ? Explication détaillée d'exemples de MySQL implémentant l'insertion par lots pour optimiser les performances
base de données
tutoriel mysql
Comment optimiser les performances ? Explication détaillée d'exemples de MySQL implémentant l'insertion par lots pour optimiser les performances
Comment optimiser les performances ? Explication détaillée d'exemples de MySQL implémentant l'insertion par lots pour optimiser les performances

Cet article présente principalement le tutoriel de MySQL pour implémenter l'insertion par lots pour optimiser les performances. Le temps d'exécution est donné dans l'article pour indiquer la comparaison après optimisation des performances. Les amis dans le besoin peuvent s'y référer
Pour certains. données avec de grandes quantités de données, Dans les grands systèmes, la base de données est confrontée non seulement à une faible efficacité des requêtes, mais également à une longue durée de stockage des données. En particulier pour les systèmes de reporting, le temps consacré à l'importation des données peut durer plusieurs heures, voire plus de dix heures par jour. Il est donc logique d’optimiser les performances d’insertion des bases de données.
Après quelques tests de performances sur MySQL innodb, j'ai trouvé quelques méthodes qui peuvent améliorer l'efficacité des insertions pour votre référence.
1. Insérez plusieurs éléments de données avec une seule instruction SQL.
Les instructions d'insertion couramment utilisées telles que
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1);
sont modifiées en :
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0), ('1', 'userid_1', 'content_1', 1);
L'opération d'insertion modifiée peut améliorer l'efficacité d'insertion de le programme. La principale raison pour laquelle l'efficacité de l'exécution du deuxième SQL est élevée ici est que la quantité de journaux après la fusion (le journal binlog de MySQL et les journaux de transactions d'innodb) est réduite, ce qui réduit le volume de données et la fréquence de vidage des journaux, améliorant ainsi l'efficacité. En fusionnant les instructions SQL, cela peut également réduire le nombre d'instructions SQL analysées et réduire les E/S de transmission réseau.
Voici quelques données de comparaison de tests, qui consistent à importer une seule donnée et à la convertir en une instruction SQL pour l'importation, et à tester respectivement 100, 1 000 et 10 000 enregistrements de données.
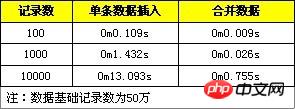
2. Effectuer le traitement d'insertion dans la transaction.
Modifiez l'insertion en :
START TRANSACTION; INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1); ... COMMIT;
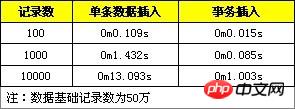
3. Insérez les données dans l'ordre.
L'insertion ordonnée des données signifie que les enregistrements insérés sont classés dans l'ordre sur la clé primaire. Par exemple, datetime est la clé primaire de l'enregistrement :
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('2', 'userid_2', 'content_2',2);
modifiée en. :
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('2', 'userid_2', 'content_2',2);Étant donné que la base de données doit conserver les données d'index lors de l'insertion, des enregistrements désordonnés augmenteront le coût de maintenance de l'index. On peut se référer à l'index B+tree utilisé par innodb. Si chaque enregistrement inséré est à la fin de l'index, l'efficacité du positionnement de l'index est très élevée, et l'ajustement de l'index est faible si l'enregistrement inséré est au milieu de l'index. index, B+tree est requis. Les processus tels que le fractionnement et la fusion consommeront plus de ressources informatiques et l'efficacité du positionnement de l'index des enregistrements insérés diminuera lorsque la quantité de données est importante, il y aura des opérations de disque fréquentes.
La comparaison des performances des données aléatoires et des données séquentielles est fournie ci-dessous, qui sont enregistrées respectivement sous la forme 100, 1 000, 10 000, 100 000 et 1 million.
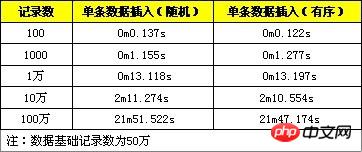
D'après les résultats des tests, les performances de cette méthode d'optimisation ont été améliorées, mais l'amélioration n'est pas très évidente.
Test de performance complet :
Voici un test qui utilise les trois méthodes ci-dessus en même temps pour optimiser l'efficacité d'INSERT.
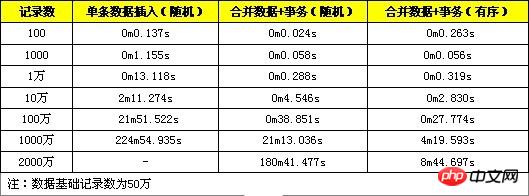
Il ressort des résultats des tests que l'amélioration des performances de la méthode de fusion données + transactions est évidente lorsque la quantité de données est faible. La quantité de données est importante, l'amélioration des performances est évidente (plus de 10 millions), les performances chuteront fortement car la quantité de données dépasse la capacité d'innodb_buffer à ce moment-là. Chaque positionnement d'index implique plus de lecture et d'écriture sur le disque. opérations, et les performances chutent rapidement. La méthode d'utilisation de données fusionnées + transactions + données ordonnées fonctionne toujours bien lorsque le volume de données atteint des dizaines de millions. Lorsque le volume de données est important, le positionnement de l'index des données ordonnées est plus pratique et ne nécessite pas d'opérations de lecture et d'écriture fréquentes sur le disque. Des performances élevées peuvent donc être maintenues.
Remarques :
1. Les instructions SQL ont des limites de longueur lors de la fusion de données dans le même SQL, la limite de longueur SQL ne doit pas être dépassée via la configuration max_allowed_packet. . La valeur par défaut est 1 M, modifiée à 8 M lors des tests.
2. La taille des transactions doit être contrôlée. Si une transaction est trop importante, cela peut affecter l'efficacité de son exécution. MySQL a l'élément de configuration innodb_log_buffer_size. Si cette valeur est dépassée, les données innodb seront vidées sur le disque. À ce stade, l'efficacité diminuera. Une meilleure approche consiste donc à valider la transaction avant que les données n'atteignent cette valeur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
La construction d'une base de données SQL comprend 10 étapes: sélectionner des SGBD; Installation de SGBD; créer une base de données; créer une table; insérer des données; récupération de données; Mise à jour des données; supprimer des données; gérer les utilisateurs; sauvegarde de la base de données.
