

Cet article présente principalement l'explication détaillée de la classe Java String. Cet article a été collecté, trié et résumé à partir de nombreuses sources, et finalement écrit dans un article. Il est très bon et mérite d'être collecté. qui en a besoin peuvent s'y référer
Question d'introduction
Parmi tous les types de données du langage Java, le Le type String est un type spécial, et c'est aussi un point de connaissance souvent demandé lors de l'utilisation de Java. Cet article combine l'allocation de mémoire Java avec une analyse approfondie de nombreux problèmes déroutants concernant String. Voici quelques problèmes qui seront abordés dans cet article. Si le lecteur est familier avec ces problèmes, vous pouvez ignorer cet article.
1. À quelle mémoire la mémoire Java fait-elle spécifiquement référence ? Pourquoi cette zone mémoire devrait-elle être divisée ? Comment est-il divisé ? Quel est le rôle de chaque zone après la division ? Comment définir la taille de chaque zone ?
2. Pourquoi le type String est-il moins efficace que StringBuffer ou StringBuilder lors des opérations de connexion ? Quelles sont les connexions et les différences entre StringBuffer et StringBuilder ?
3. Que signifient les constantes en Java ? Quelle est la différence entre String s = "s" et String s = new String("s") ?
Cet article a été compilé et résumé à partir de diverses sources et finalement rédigé s'il y a des erreurs, faites-le moi savoir !
Allocation de mémoire Java
1. JVMIntroduction
Java La machine virtuelle (Java Virtual Machine, appelée JVM) est un ordinateur abstrait qui exécute tous les programmes Java. C'est l'environnement d'exécution du langage Java. C'est l'une des fonctionnalités les plus attrayantes de Java. La machine virtuelle Java possède sa propre architecture matérielle complète , telle que processeur, pile, registres, etc., et dispose également d'un système d'instructions correspondant. La JVM protège les informations liées à la plate-forme spécifique du système d'exploitation, de sorte que le programme Java n'a besoin que de générer le code cible (bytecode) qui s'exécute sur la machine virtuelle Java et peut s'exécuter sur plusieurs plates-formes sans modification.
La tâche impérative d'une instance de machine virtuelle Java d'exécution est la suivante : responsable de l'exécution d'un programme Java. Lorsqu'un programme Java est démarré, une instance de machine virtuelle naît. Lorsque le programme est fermé et se termine , l'instance de machine virtuelle mourra également. Si trois programmes Java sont exécutés simultanément sur le même ordinateur, trois instances de machine virtuelle Java seront obtenues. Chaque programme Java s'exécute dans sa propre instance de machine virtuelle Java.
Comme le montre la figure ci-dessous, l'architecture JVM comprend plusieurs sous-systèmes et zones de mémoire majeurs :
Recyclez les objets inutilisés dans la mémoire tas (Heap), c'est-à-dire que ces objets sont n'est plus référencé. Mémoire du sous-système du chargeur de classe et aide à la résolution des références de symboles.
Execution Engine (Execution Engine) : Responsable de l'exécution des instructions contenues dans les méthodes de la classe chargée.
Zone de données d'exécution (Zone d'allocation de mémoire Java) : également appelée mémoire de machine virtuelle ou mémoire Java, lorsque la machine virtuelle est en cours d'exécution, elle doit diviser une zone de mémoire de la mémoire entière de l'ordinateur pour stocker plusieurs des choses. Par exemple : bytecode, autres informations obtenues à partir des fichiers de classe chargés, objets créés par le programme, paramètres passés aux méthodes, valeurs de retour, variables locales, etc.
2. Partition de mémoire Java

Compteur de programme (Registre du nombre de programmes) : également appelé registre de programme. La JVM prend en charge plusieurs threads exécutés en même temps. Lorsque chaque nouveau thread est créé, il obtiendra son propre registre PC (compteur de programme). Si le thread exécute une méthode Java (non native), alors la valeur du registre PC pointera toujours vers la prochaine instruction à exécuter. Si la méthode est native, la valeur du registre du compteur de programme ne sera pas définie. Le registre du compteur de programme de la JVM est suffisamment large pour contenir une adresse de retour ou un pointeur natif. La JVM alloue une pile pour chaque thread nouvellement créé. Autrement dit, pour un programme Java, son fonctionnement s’effectue grâce au fonctionnement de la pile. La pile enregistre l' • -Xss --Définir la valeur maximale de la pile de méthodes Zone de méthode Analysez les informations de type dans la méthode, puis placez les informations de type (y compris les informations de classe, les constantes, les variables statiques Heap (Heap) : Java Heap (Java Heap) est le plus grand morceau de mémoire géré par la machine virtuelle Java. Le tas Java est une zone mémoire partagée par tous les threads. Le seul but de cette zone est de stocker les instances d'objet. Presque toutes les instances d'objet allouent de la mémoire ici, mais la référence à cet objet est allouée sur la pile. Par conséquent, lors de l'exécution de String s = new String("s"), la mémoire doit être allouée à deux endroits : la mémoire est allouée à l'objet String dans le tas, et est une référence dans la pile (l'adresse mémoire de cet objet de tas, c'est-à-dire le pointeur ) alloue de la mémoire, comme le montre la figure ci-dessous. • -Xms -- Définir la taille initiale de la mémoire du tas • -XX :MaxTenuringThreshold -- Définit le nombre de fois qu'un objet survit dans la nouvelle génération Le tas Java est la zone principale gérée par le garbage collector, c'est pourquoi on l'appelle aussi le "GC Heap" (Garbage Collectioned Heap). Les garbage collector d'aujourd'hui utilisent essentiellement des algorithmes de collecte générationnelle, de sorte que le tas Java peut être subdivisé en : Jeune génération et Ancienne génération, comme le montre la figure ci-dessous. L'idée d'un algorithme de collecte générationnelle : La première méthode consiste à scanner et recycler les objets jeunes (jeune génération) à une fréquence plus élevée. C'est ce qu'on appelle la collecte mineure, tandis que la fréquence de contrôle et de recyclage des objets anciens (ancienne génération) est plus faible. Beaucoup, appelé grande collection. De cette façon, il n'est pas nécessaire de vérifier tous les objets en mémoire à chaque fois que GC est utilisé, afin de mettre davantage de ressources système à la disposition du système d'application. En d'autres termes, lorsque l'objet alloué rencontre une mémoire insuffisante, la nouvelle génération le fera. être GCed en premier (Young GC) ; lorsque le GC de nouvelle génération ne peut toujours pas répondre aux exigences d'allocation d'espace mémoire, le GC (Full GC) sera effectué sur l'ensemble de l'espace du tas et de la zone de méthode. Certains lecteurs peuvent avoir des questions ici : rappelez-vous qu'il existe une génération permanente (Permanent Generation), n'appartient-elle pas au tas Java ? Cher, tu as bien compris ! En fait, la génération permanente légendaire est la zone de méthode mentionnée ci-dessus, qui stocke certaines informations de type (y compris les informations de classe, les constantes, les variables statiques, etc.) chargées par le chargeur lors de l'initialisation de la jvm. Le cycle de vie de ces informations est relativement. long, et GC ne PermGen Space sera nettoyé pendant l'exécution du programme principal, donc s'il y a beaucoup de CLASS dans votre application, des erreurs PermGen Space sont susceptibles de se produire. Ses paramètres de réglage associés : • -XX:PermSize --Définir la taille initiale de la zone Perm • -XX:MaxPermSize --Définir la valeur maximale de la zone Perm 🎜>La nouvelle génération (Jeune Génération) est divisée en : Zone Eden et Zone Survivant. La zone Survivant est divisée en From Space et To Space. La zone Eden est l'endroit où l'objet est initialement alloué ; par défaut, les zones From Space et To Space sont de taille égale. Lorsque la JVM effectue un GC mineur, elle copie les objets survivants d'Eden vers la zone Survivant, et copie également les objets survivants de la zone Survivant vers la zone Tenured. Dans ce mode GC, afin d'améliorer l'efficacité du GC, la JVM divise Survivor en From Space et To Space, afin que le recyclage des objets et la promotion des objets puissent être séparés. Il existe deux paramètres liés pour le réglage de la taille de la nouvelle génération : 3. Analyse approfondie du type String Commençons par les types de données Java ! Les types de données Java sont généralement divisés en deux catégories (avec différentes méthodes de classification) : les types de base et les types de référence. Les variables des types de base contiennent des valeurs primitives, et les variables des types de référence représentent généralement des références à des objets réels. l'objet. Ouvrez le code source de String, il y a un tel passage dans la classe commentaire Par conséquent, nous examinons la méthode concat de la classe String. La première étape pour implémenter cette méthode doit être d'étendre la capacité de la valeur de la variable membre. La méthode d'expansion redéfinit un tableau de caractères buf de grande capacité. La deuxième étape consiste à copier les caractères de la valeur d'origine dans buf, puis à copier la valeur de chaîne qui doit être concaténée dans buf. De cette façon, buf contient la valeur de chaîne après la concaténation. Voici la clé du problème. Si la valeur n'est pas finale, pointez directement la valeur sur buf, puis renvoyez-la, vous avez terminé. Il n'est pas nécessaire de renvoyer un nouvel objet String. mais. . . pitié. . . Puisque la valeur est finale, elle ne peut pas pointer vers le tableau buf de grande capacité nouvellement défini. Que devons-nous faire ? "return new String(0, count + otherLen, buf);", il s'agit de la dernière instruction de la méthode d'implémentation concat de la classe String et renvoie un nouvel objet String. Maintenant, la vérité est révélée ! Résumé : String est essentiellement un tableau de caractères avec deux caractéristiques : 1. Cette classe ne peut pas être héritée ; 2. Immuable. 2. La méthode de définition de String Avant de discuter de la méthode de définition de String, comprenons d'abord le concept de pool constant La méthode. est introduit plus tôt. Cela a déjà été mentionné dans le quartier. Donnons une définition un peu formelle. Le pool constant fait référence à certaines données déterminées lors de la compilation et enregistrées dans le fichier .class compilé. Il comprend des constantes dans les classes, méthodes, interfaces, etc., ainsi que des constantes de chaîne. Le pool de constantes est également dynamique et de nouvelles constantes peuvent être placées dans le pool pendant l'exécution. La méthode intern() de la classe String est une application typique de cette fonctionnalité. Vous ne comprenez pas ? La méthode interne sera présentée plus tard. La machine virtuelle gère un pool de constantes pour chaque type chargé. Le pool est une collection ordonnée de constantes utilisées par le type, y compris des constantes directes (constantes de chaîne, entières et flottantes) et des références symboliques à d'autres types, champs et méthodes (What est la différence entre celui-ci et la référence d'objet ? Les lecteurs peuvent le découvrir par eux-mêmes). La méthode de définition de chaîne est résumée au total : • Utilisez des mots-clés Nouveau, tels que : chaîne s1 = nouvelle chaîne ("machaîne" ("machaîne") ; • Définition directe, telle que : String s1 = "myString" ; • Génération de concaténation, telle que : String s1 = "my" + "String" ; Cette méthode est plus compliquée ; . Je n’entrerai pas dans les détails ici. La première façon est de définir le processus via le mot-clé new : lors de la compilation du programme, le compilateur vérifie d'abord le pool de constantes de chaîne pour voir si "myString" existe. S'il n'existe pas, ouvrez une mémoire dans le. pool de constantes. L'espace stocke "myString" ; s'il existe, il n'est pas nécessaire de rouvrir l'espace pour s'assurer qu'il n'y a qu'une seule constante "myString" dans le pool de constantes, économisant ainsi de l'espace mémoire. Ensuite, ouvrez un espace dans le tas de mémoire pour stocker la nouvelle instance de String. Créez un espace dans la pile et nommez-le "s1". La valeur stockée est l'adresse mémoire de l'instance de String dans le tas. référencez s1 à la nouvelle instance de chaîne. La deuxième façon est de définir directement le processus : lors de la compilation du programme, le compilateur vérifie d'abord le pool de constantes de chaîne pour voir si "myString" existe. S'il n'existe pas, ouvrez une mémoire dans le. pool constant. L'espace stocke "myString" ; s'il existe, il n'est pas nécessaire de rouvrir l'espace. Ensuite, ouvrez un espace dans la pile, nommez-le « s1 » et stockez la valeur comme adresse mémoire de « myString » dans le pool de constantes. Avec de nombreuses questions, je discuterai avec vous de la relation entre les objets String dans le tas et les constantes String dans le pool de constantes. N'oubliez pas qu'il ne s'agit que d'une discussion, car je suis également relativement vague à ce sujet. ce sujet. 第一种猜想:因为直接定义的字符串也可以调用String对象的各种方法,那么可以认为其实在常量池中创建的也是一个String实例(对象)。 这种猜想认为:常量池中的字符串常量实质上是一个String实例,与堆中的String实例是克隆关系。 第二种猜想也是目前网上阐述的最多的,但是思路都不清晰,有些问题解释不通。下面引用《JAVA String对象和字符串常量的关系解析》一段内容。 在解析阶段,虚拟机发现字符串常量"myString",它会在一个内部字符串常量列表中查找,如果没有找到,那么会在堆里面创建一个包含字符序列[myString]的String对象s1,然后把这个字符序列和对应的String对象作为名值对( [myString], s1 )保存到内部字符串常量列表中。如下图所示: 如果虚拟机后面又发现了一个相同的字符串常量myString,它会在这个内部字符串常量列表内找到相同的字符序列,然后返回对应的String对象的引用。维护这个内部列表的关键是任何特定的字符序列在这个列表上只出现一次。 这个猜想有一个比较明显的问题,红色字体标示的地方就是问题的所在。证明方式很简单,下面这段代码的执行结果,javaer都应该知道。
état
, etc.) dans la zone de méthode. Cette zone mémoire est partagée par tous les threads, comme le montre la figure ci-dessous. Il existe une zone mémoire spéciale dans la zone de méthode locale appelée Constant Pool. Cette mémoire sera étroitement liée à l'analyse du type String. 

• -Xmx -- Définir la taille maximale de la mémoire du tas 

1. L'essence de String private final char value[];
private final int count;
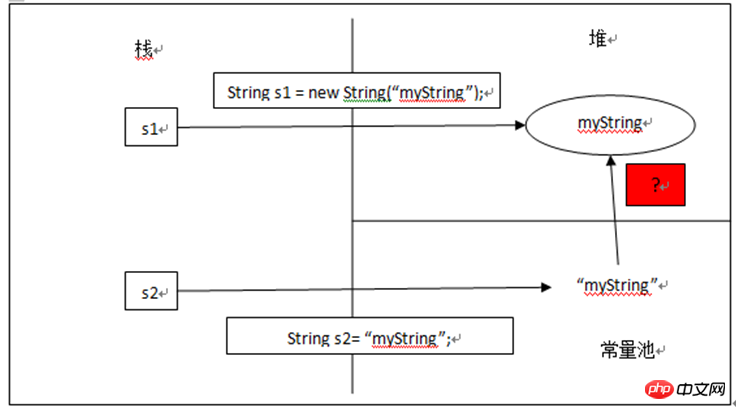
String s1 = new String("myString");先在编译期的时候在常量池创建了一个String实例,然后clone了一个String实例存储在堆中,引用s1指向堆中的这个实例。此时,池中的实例没有被引用。当接着执行String s1 = "myString";时,因为池中已经存在“myString”的实例对象,则s1直接指向池中的实例对象;否则,在池中先创建一个实例对象,s1再指向它。如下图所示: 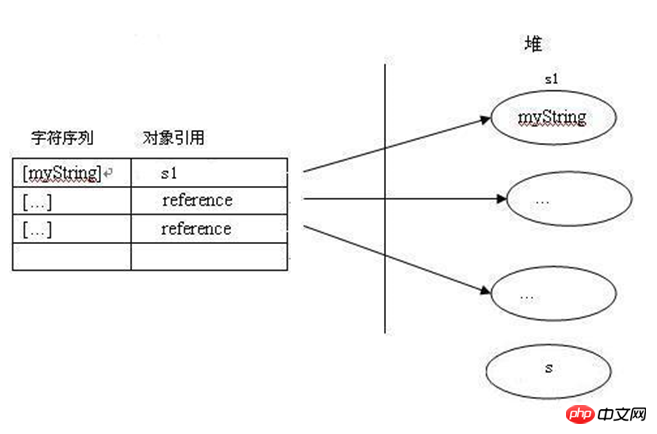
例如,String s2 = "myString",运行时s2会从内部字符串常量列表内得到s1的返回值,所以s2和s1都指向同一个String对象。String s1 = new String("myString");
String s2 = "myString";
System.out.println(s1 == s2); //按照上面的推测逻辑,那么打印的结果为true;而实际上真实的结果是false,因为s1指向的是堆中String对象,而s2指向的是常量池中的String常量。
虽然这段内容不那么有说服力,但是文章提到了一个东西——字符串常量列表,它可能是解释这个问题的关键。
文中提到的三个问题,本文仅仅给出了猜想,具体请自己考证!
• 堆中new出来的实例和常量池中的“myString”是什么关系呢?
• 常量池中的字符串常量与堆中的String对象有什么区别呢?
• 为什么直接定义的字符串同样可以调用String对象的各种方法呢?
3、String、StringBuffer、StringBuilder的联系与区别
上面已经分析了String的本质了,下面简单说说StringBuffer和StringBuilder。
StringBuffer和StringBuilder都继承了抽象类AbstractStringBuilder,这个抽象类和String一样也定义了char[] value和int count,但是与String类不同的是,它们没有final修饰符。因此得出结论:String、StringBuffer和StringBuilder在本质上都是字符数组,不同的是,在进行连接操作时,String每次返回一个新的String实例,而StringBuffer和StringBuilder的append方法直接返回this,所以这就是为什么在进行大量字符串连接运算时,不推荐使用String,而推荐StringBuffer和StringBuilder。那么,哪种情况使用StringBuffe?哪种情况使用StringBuilder呢?
关于StringBuffer和StringBuilder的区别,翻开它们的源码,下面贴出append()方法的实现。

La première image ci-dessus est l'implémentation de la méthode append() dans StringBuffer, et la deuxième image est l'implémentation de append() dans StringBuilder. La différence devrait être claire en un coup d'œil. StringBuffer ajoute une modification synchronisée avant la méthode, qui joue un rôle de synchronisation et peut être utilisée dans un environnement multithread. Le prix à payer pour cela est une efficacité d’exécution réduite. Par conséquent, si vous pouvez utiliser StringBuffer pour les opérations de connexion de chaîne dans un environnement multithread, il est plus efficace d'utiliser StringBuilder dans un environnement monothread.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



