
 développement back-end
Tutoriel Python
Implémentation Python du cas du robot d'exploration de pages de paragraphes réseau
développement back-end
Tutoriel Python
Implémentation Python du cas du robot d'exploration de pages de paragraphes réseau
Implémentation Python du cas du robot d'exploration de pages de paragraphes réseau

La plupart des tutoriels Python sur Internet sont la version 2.X. Par rapport à python3.X, python2.X a beaucoup changé. J'ai installé python3.X. . Exemple
0x01
Je n'avais rien à faire pendant la Fête du Printemps (comme je suis libre), alors j'ai écrit un programme simple pour lire quelques blagues et enregistrer le processus d'écriture du programme. La première fois que je suis entré en contact avec des robots, c'est lorsque j'ai vu un article comme celui-ci. C'était un article amusant sur l'exploration de photos de filles sur Omelette. Ce n'était pas très pratique. J'ai donc commencé à imiter moi-même les chats et les tigres et j'ai pris quelques photos.
La technologie inspire l'avenir. En tant que programmeur, comment pouvez-vous faire une telle chose ? Il est préférable de faire des blagues meilleures pour votre santé physique et mentale.

0x02
Avant de retrousser nos manches et de commencer, vulgarisons quelques connaissances théoriques.
Pour faire simple, nous devons dérouler le contenu à un endroit spécifique de la page Web. Comment le dérouler Nous devons d'abord analyser la page Web pour voir quel élément de contenu nous avons. besoin. Par exemple, ce que nous avons exploré cette fois, ce sont les blagues du site Web hilarant. Lorsque nous ouvrons la page des blagues du site Web hilarant, nous pouvons voir beaucoup de blagues. Notre objectif est d'obtenir ces contenus. Revenez vous calmer après l'avoir lu. Si vous continuez à rire comme ça, nous ne pouvons pas écrire de code. Dans chromeome, nous ouvrons l'élément inspect puis développons les balises HTML niveau par niveau, ou cliquons sur la petite souris pour localiser l'élément dont nous avons besoin.
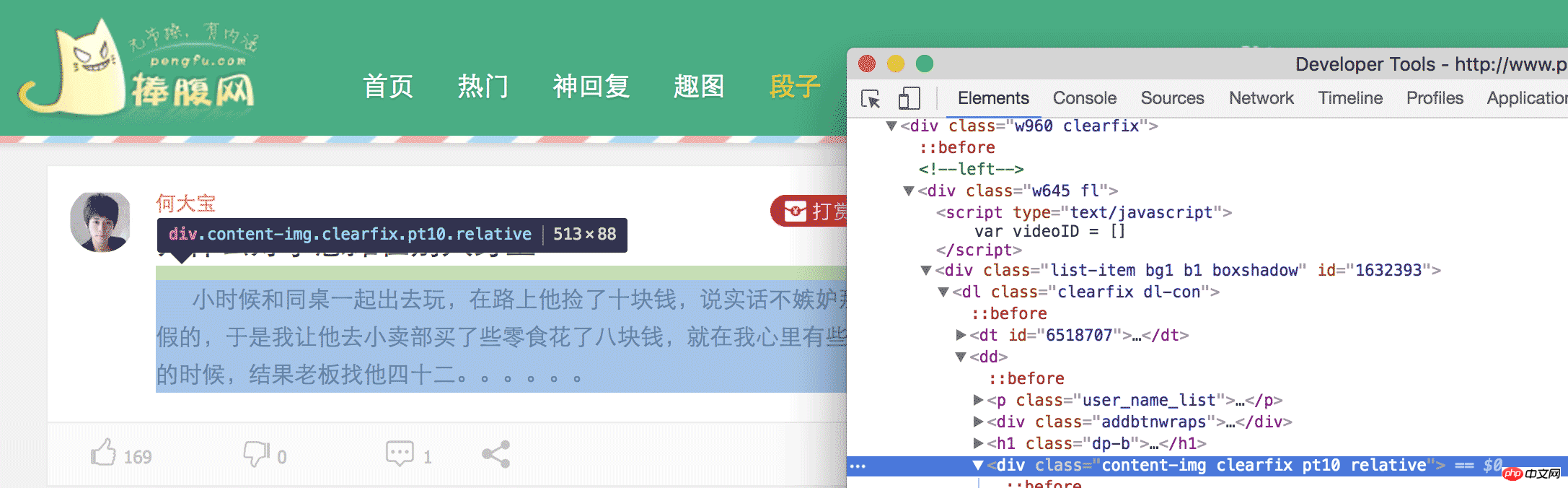
Enfin, nous pouvons constater que le contenu de
est la blague dont nous avons besoin. La même chose est vraie lorsque l'on regarde la deuxième blague. . Ainsi, nous pouvons trouver tous les
dans cette page Web, puis extraire le contenu à l'intérieur, et nous avons terminé.
0x03
D'accord, maintenant que nous connaissons notre objectif, nous pouvons retrousser nos manches et commencer. J'utilise python3 ici. Concernant le choix de python2 et python3, chacun peut décider par lui-même. Les fonctions peuvent être réalisées, mais il existe quelques différences. Mais il est toujours recommandé d'utiliser python3.
Nous voulons extraire le contenu dont nous avons besoin. Nous devons d'abord extraire cette page Web. Comment la extraire ? Ici, nous devons utiliser une bibliothèque appelée urllib. page Web entière.
Tout d'abord, on importe urllib
Le code est le suivant :
import urllib.request as request
Ensuite, on peut utiliser request pour obtenir la page web,
Le code est le suivant :
return request.urlopen(url).read()
La vie est courte, j'utilise python, une ligne de code, téléchargez la page Web, dites-vous, quelle autre raison de ne pas utiliser python.
Après avoir téléchargé la page Web, nous devons analyser la page Web pour obtenir les éléments dont nous avons besoin. Afin d'analyser les éléments, nous devons utiliser un autre outil appelé Beautiful Soup. Avec lui, nous pouvons analyser rapidement le HTML et le XML et obtenir les éléments dont nous avons besoin.
Le code est le suivant :
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html"))Utiliser BeautifulSoup pour analyser une page Web n'est qu'une phrase, mais lorsque vous exécutez le code, un tel avertissement apparaîtra, vous invitant vous devez spécifier un serveur d'analyseur, sinon des erreurs pourraient être signalées sur d'autres plates-formes ou systèmes.
Le code est le suivant :
/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/bs4/init.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 64 of the file joke.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))Les types d'analyseurs et les différences entre les différents analyseurs sont expliqués en détail dans les documents officiels. À l'heure actuelle, il est plus fiable d'utiliser lxml. analyse.
Après modification
le code est le suivant :
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html", 'lxml'))De cette façon, il n'y aura pas d'avertissement ci-dessus.
Le code est le suivant :
p_array = soup.find_all('p', {'class':"content-img clearfix pt10 relative"})Utilisez la fonction find_all pour trouver toutes les balises p de class = content-img clearfix pt10 relative puis parcourez ceci array
Le code est le suivant :
for x in p_array: content = x.string
De cette façon, on obtient le contenu du but p. À ce stade, nous avons atteint notre objectif et atteint notre plaisanterie.
Mais lors de l'exploration de la même manière, une telle erreur sera signalée
Le code est le suivant :
raise RemoteDisconnected("Remote end closed connection without" http.client.RemoteDisconnected: Remote end closed connection without response说远端无响应,关闭了链接,看了下网络也没有问题,这是什么情况导致的呢?莫非是我姿势不对?
打开 charles 抓包,果然也没反应。唉,这就奇怪了,好好的一个网站,怎么浏览器可以访问,python 无法访问呢,是不是 UA 的问题呢?看了下 charles,发现,利用 urllib 发起的请求,UA 默认是 Python-urllib/3.5 而在 chrome 中访问 UA 则是 User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36,那会不会是因为服务器根据 UA 来判断拒绝了 python 爬虫。我们来伪装下试试看行不行
代码如下:
def getHTML(url):
head
ers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()这样就把 python 伪装成 chrome 去获取糗百的网页,可以顺利的得到数据。
至此,利用 python 爬取糗百和捧腹网的笑话已经结束,我们只需要分析相应的网页,找到我们感兴趣的元素,利用 python 强大的功能,就可以达到我们的目的,不管是 XXOO 的图,还是内涵段子,都可以一键搞定,不说了,我去找点妹子图看看。
# -*- coding: utf-8 -*-
import sys
import urllib.request as request
from bs4 import BeautifulSoup
def getHTML(url):
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()
def get_pengfu_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
return soup.find_all('p', {'class':"content-img clearfix pt10 relative"})
def get_pengfu_joke():
for x in range(1, 2):
url = 'http://www.pengfu.com/xiaohua_%d.html' % x
for x in get_pengfu_results(url):
content = x.string
try:
string = content.lstrip()
print(string + '\n\n')
except:
continue
return
def get_qiubai_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
contents = soup.find_all('p', {'class':'content'})
restlus = []
for x in contents:
str = x.find('span').getText('\n','<br/>')
restlus.append(str)
return restlus
def get_qiubai_joke():
for x in range(1, 2):
url = 'http://www.qiushibaike.com/8hr/page/%d/?s=4952526' % x
for x in get_qiubai_results(url):
print(x + '\n\n')
return
if name == 'main':
get_pengfu_joke()
get_qiubai_joke()【相关推荐】
1. Python免费视频教程
3. Python基础入门手册
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement mysql est corrompu, que dois-je faire? Hélas, si vous téléchargez MySQL, vous pouvez rencontrer la corruption des fichiers. Ce n'est vraiment pas facile ces jours-ci! Cet article expliquera comment résoudre ce problème afin que tout le monde puisse éviter les détours. Après l'avoir lu, vous pouvez non seulement réparer le package d'installation MySQL endommagé, mais aussi avoir une compréhension plus approfondie du processus de téléchargement et d'installation pour éviter de rester coincé à l'avenir. Parlons d'abord de la raison pour laquelle le téléchargement des fichiers est endommagé. Il y a de nombreuses raisons à cela. Les problèmes de réseau sont le coupable. L'interruption du processus de téléchargement et l'instabilité du réseau peut conduire à la corruption des fichiers. Il y a aussi le problème avec la source de téléchargement elle-même. Le fichier serveur lui-même est cassé, et bien sûr, il est également cassé si vous le téléchargez. De plus, la numérisation excessive "passionnée" de certains logiciels antivirus peut également entraîner une corruption des fichiers. Problème de diagnostic: déterminer si le fichier est vraiment corrompu
 Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
