

Apprenez à analyser le HTML sous nodejs

Analyse du HTML dans l'environnement nodejs
Dans l'environnement nodejs, obtenez/analysez les données du site Web d'image sœur/et utilisez express pour json le client Retour de données.
Cet article résout principalement : 1. Le problème de l'analyse du HTML demandé avec jquery ; 2. Le problème des bibliothèques de fonctions alternatives pour les gros utilisateurs de jquery dans l'environnement nodejs ; 3. Le problème de l'envoi de requêtes ajax ; sous nodejs (requête ajax, elle-même est une requête de requête) ; 4. Cet article utilise des cas réels pour présenter comment utiliser cheerio pour effectuer des opérations DOM.
Les utilisateurs doivent installer le module npm : cheerio
Il est également recommandé d'utiliser le module npm : nodemon, qui peut déployer à chaud les programmes nodejs
Introduction
WeChat mini-plateforme de programme Les exigences de base sont :
1. Le serveur de données doit être un serviceinterface du protocole https
2 L'applet WeChat n'est pas html5. prend en charge l'analyse DOM et les opérations de fenêtre
3. La version de test peut utiliser des interfaces de services de données tierces, mais la version officielle ne permet pas l'utilisation d'interfaces tierces (bien sûr, nous parlons ici de plusieurs interfaces tierces). interfaces de données).
Sous la plate-forme APICLOUD, nous pouvons utiliser html5 avec jquery et d'autres bibliothèques de classes pour réaliser l'analyse des données dom afin de résoudre le problème de la source de données. pas au format json (utilisez jquery pour charger des données en html5 sous html, et revenez en arrière et triez l'application de test que j'ai créée lorsque j'apprenais l'API de la plate-forme apicloud), mais sous la mini-plate-forme de programme WeChat, il n'y a fondamentalement aucun moyen de analyser l'élément html . Avant d'écrire cet article, j'ai vu des réponses sur Internet concernant l'utilisation de underscore au lieu de jquery pour l'analyse DOM. J'ai travaillé dessus pendant longtemps et j'ai trouvé que ce n'était toujours pas aussi fluide.
Par conséquent, la solution proposée dans cet article consiste à résoudre deux problèmes :
1. Utilisez votre propre serveur pour fournir à votre propre applet WeChat des services de conversion de données HTML provenant de sites Web tiers, en convertissant les données tierces. Les éléments HTML de fête analysent les éléments dont ils ont besoin. Sous la plate-forme nodejs, utilisez le module request pour compléter les demandes de données et utilisez le module cheerio pour terminer l'analyse HTML.
2. Sous la plateforme nodejs, bien qu'il existe un module jquery, son utilisation pose encore de nombreux problèmes. Il existe un article sur Internet qui a été copié par un site Web, donnant une méthode d'utilisation de jquery dans un environnement nodejs. Après mon test réel, j'ai découvert qu'il n'était pas possible de commencer à écrire du code en douceur.
Par conséquent, les idées d'écriture de cet article : 1. Analyser la source de données ; 2. Présenter brièvement request 3. Présenter brièvement les méthodes courantes du module cheerio 4. Écrire sous nodejs, utilisez le module express pour fournir des données json.
Analyse des sources de données
Analyse de la liste de données
Selon les routines de la plupart des programmes, les opérations sur les sources de données tierces sont principalement des cas de robots, c'est donc le cas dans cet article devrait être pareil. C'est une bénédiction pour les homeboys. L'adresse cible de cet article est : http://m.mmjpg.com.
La source de données de cet article provient de la page classement. La page de classement ressemble à ceci, 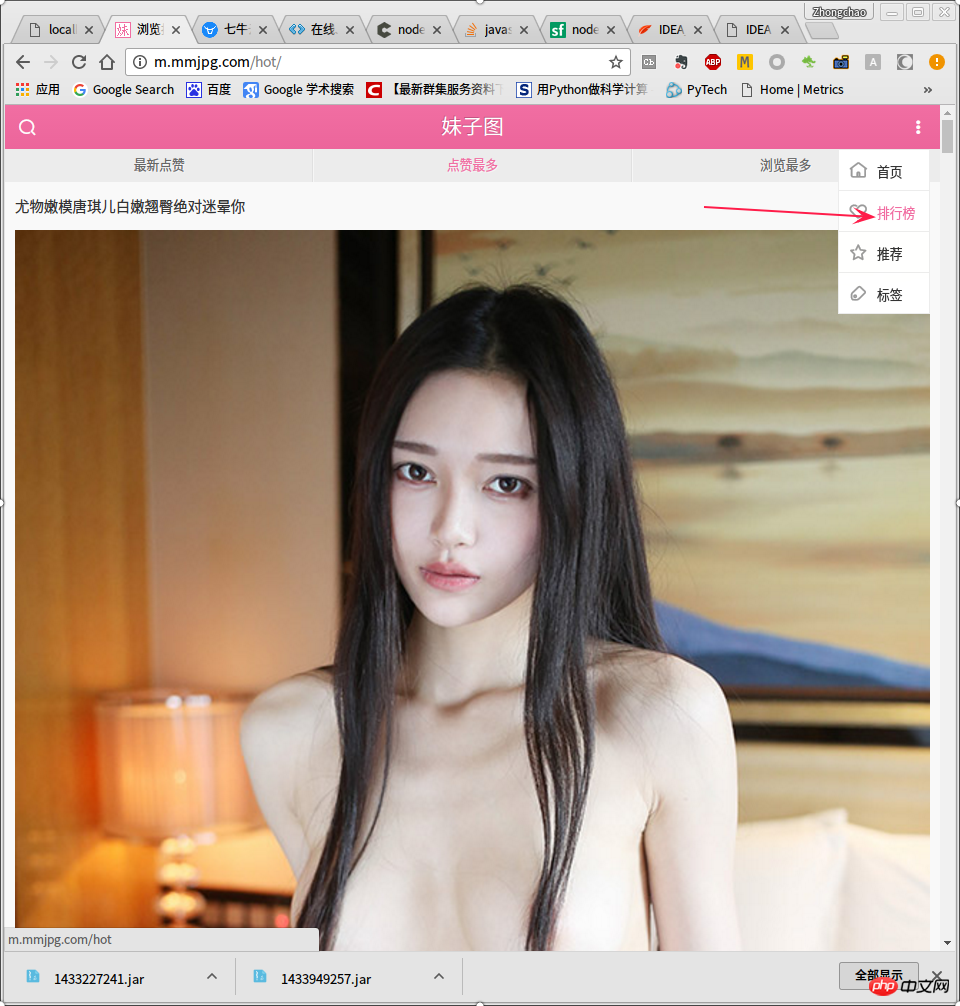
en faisant glisser la barre de défilement en bas, on peut trouver un bouton charger plus , après avoir cliqué sur Charger plus, dans la console du navigateur, vous pouvez voir que le navigateur a envoyé une demande pour que url soit http://m.mmjpg.com/getmore.php?te=1&page=3 
navigateur La capture d'écran du réseau. La requête affichée sur la console est la suivante : 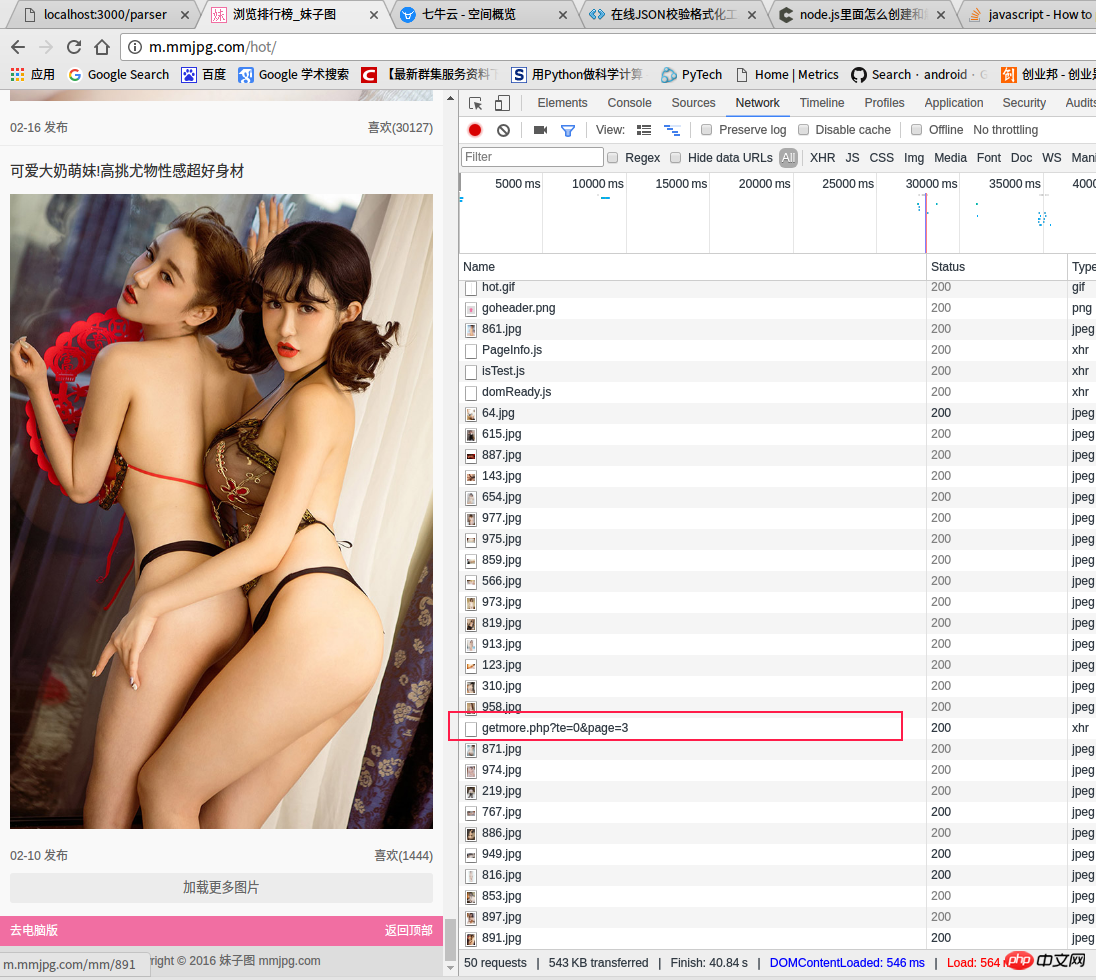
Nous pouvons utiliser le navigateur pour ouvrir le lien ci-dessus (http://m.mmjpg.com/getmore.php?te=1&page=3) C'est le lien auquel j'ai accédé lorsque j'écrivais cet article. -données temporelles obtenues par le navigateur à ce moment-là (les lecteurs peuvent obtenir des données différentes des miennes lorsqu'ils accèdent eux-mêmes au navigateur).
Dans l'image ci-dessous, j'ai marqué les données dans le code source de la page, y compris le contenu suivant : 1. Titre ; 2. Adresse de navigation de toutes les images ; Heure de sortie ; 5. Nombre de likes 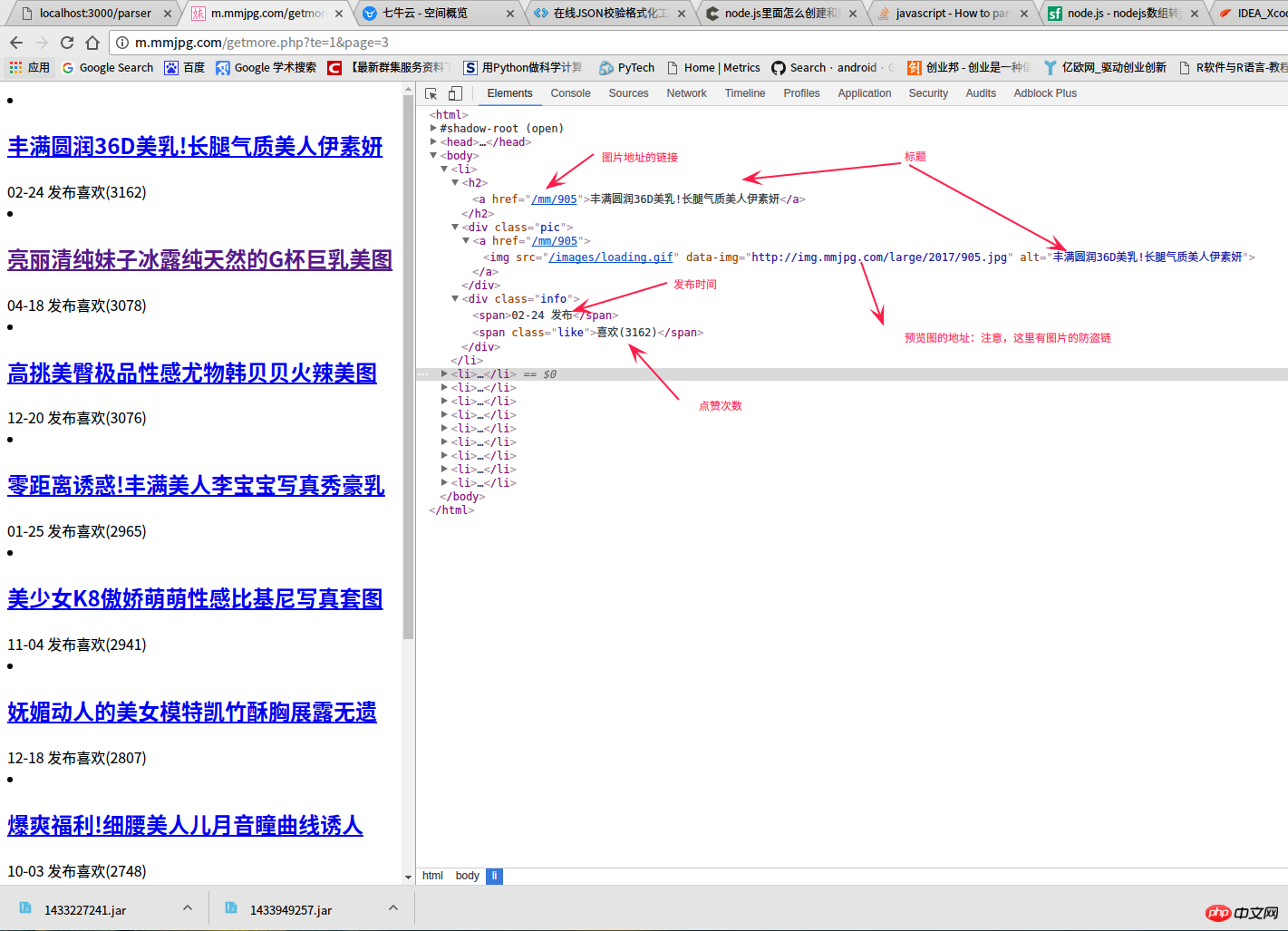
Analyse de la page de détails des données
Lorsque nous avons accédé pour charger plus de pages ci-dessus, dans la page avec la liste page=3, nous avons cliqué sur le lien suivant http://m.mmjpg.com/mm/958, et le titre correspondant est 亮丽清纯妹子冰露纯天然的G杯巨乳美图 .
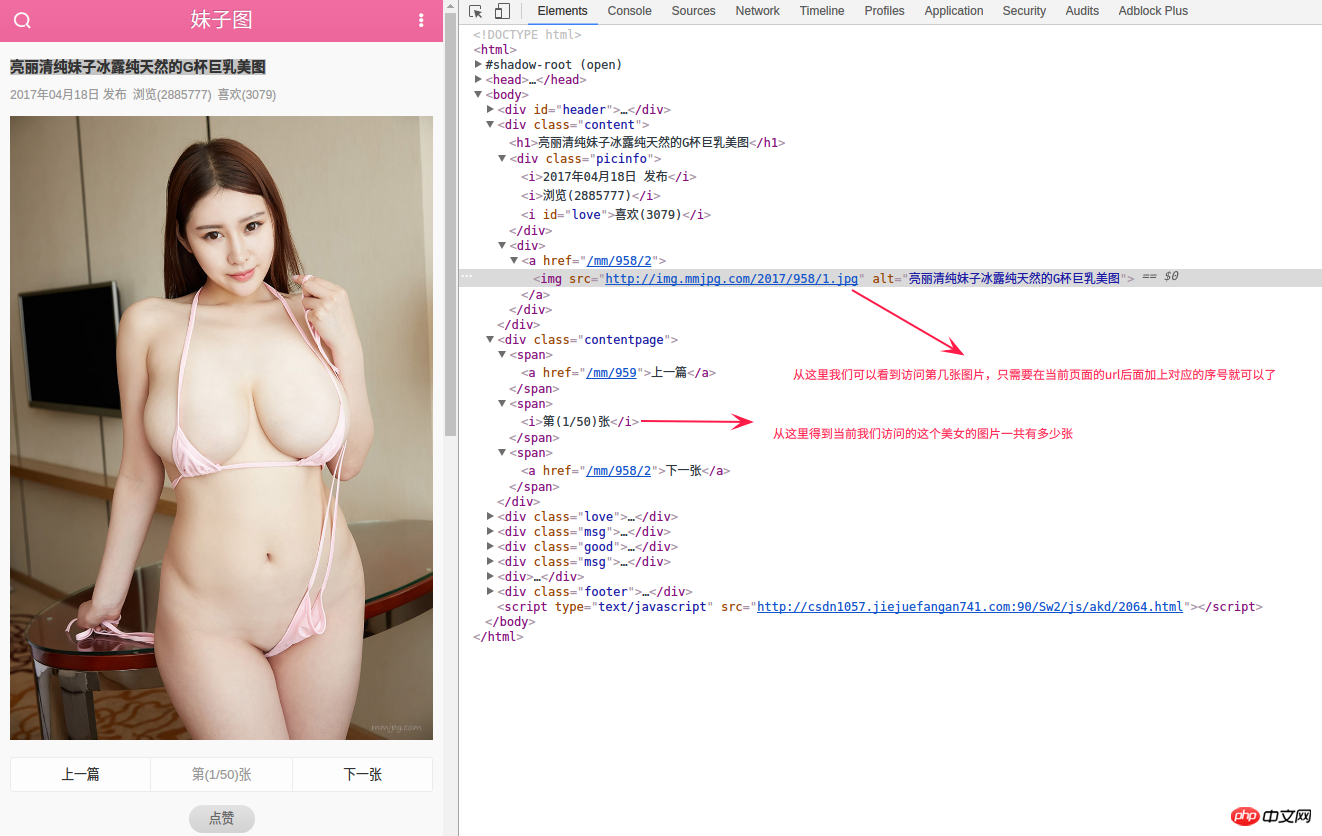
D'après l'image ci-dessus, vous pouvez voir que chaque http://m.mmjpg.com/mm/958/<a href="http://www.php.cn/wiki/58.html" target="_blank">数组</a>序号 page a une image, et l'adresse de cette image est également très standardisée, qui est http://img.mmjpg.com/2017/958/1.jpg. La chose suivante est très simple. Il nous suffit de savoir combien d’images il y a dans la collection d’images actuelle, puis nous pouvons regrouper les adresses de toutes les images selon les règles. Ici, pour obtenir les données de la page de détails, il suffit d'obtenir les données de la première page d'image. La principale donnée obtenue est que 第(1/N)张 et class sont le src de la première balise content sous le p de img.
Eh bien, c'est toute l'introduction aux sources de données ci-dessus. L'analyse d'autres sources de données suit la même idée. Je pense que tous les lecteurs pourront obtenir les données qu'ils souhaitent.
introduction du module de requête
request le module facilite http les requêtes.
L'exemple le plus simple :
var request = require('request');
request('http://www.google.com', function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body);
}
})Captez des images sur Internet et enregistrez-les localement
var fs=require('fs');var request=require('request'); request('http://n.sinaimg.cn/news/transform/20170211/F57R-fyamvns4810245.jpg').pipe(fs.createWriteStream('doodle.png'));
Téléchargez le fichier local file.json sur monsite com/obj. .json
fs.createReadStream('file.json').pipe(request.put('http://mysite.com/obj.json'))
Télécharger google.com/img.png sur mysite.com/img.png
request.get('http://google.com/img.png').pipe(request.put('http://mysite.com/img.png'))
Soumission du formulaire sur service.com/upload
var r = request.post('http://service.com/upload')var form = r.form() form.append('my_field', 'my_value') form.append('my_buffer', new Buffer([1, 2, 3])) form.append('my_file', fs.createReadStream(path.join(dirname, 'doodle.png')) form.append('remote_file', request('http://google.com/doodle.png'))
Authentification HTTP
request.get('http://some.server.com/').auth('username', 'password', false);
En-tête HTTP personnalisé
//User-Agent之类可以在options对象中设置。var options = {
url: 'https://api.github.com/repos/mikeal/request',
headers: { 'User-Agent': 'request'
}
};function callback(error, response, body) {
if (!error && response.statusCode == 200) { var info = JSON.parse(body);
console.log(info.stargazers_count +"Stars");
console.log(info.forks_count +"Forks");
}
}
request(options, callback);introduction du module Cheerio
Cheerio est spécialement personnalisé pour le serveur, rapide, flexible, Le jQuery implémenté implémentation de base. Une introduction au module cheerio sur le site officiel de npm : www.npmjs.com/package/cheerio
Si vous avez des problèmes pour lire la littérature anglaise, il y a une introduction chinoise à l'API cheerio sous le Communauté chinoise nodejs : cnodejs.org/topic/5203a71844e76d216a727d2e
Comparaison de jquery
En fait, si vous utilisez const cheerio = require('cheerio'); pour charger le module cheerio sous nodejs, votre source html aura caractères Si la chaîne est utilisée comme paramètre et chargée à l'aide de la fonction cheerio de load, nous pouvons suivre pleinement l'idée de jquery programmation dans l'environnement pour réaliser l'analyse du DOM .
Étant donné que le module cheerio implémente la plupart des fonctions de jquery, cet article ne les présentera pas trop ici.
Décrivez comment obtenir des données basées sur le code
Grâce à l'analyse ci-dessus, nous pouvons voir que notre source de données n'est pas json, mais html Pour jquery, < 🎜. > doit définir html sur ajax lors de l'envoi de la demande dataType. text
1. Utilisez la requête ajax, transmettez l'URL et définissez le type de données
2. Utilisez
pour convertir les données obtenues par $(data) en un ajax. objet. jquery3. Utilisez les méthodes
et jquery de find pour trouver les éléments que vous devez obtenir. get4. Utilisez les méthodes
et jquery de attr pour obtenir les informations requises. html5. Intégrez les informations ci-dessus dans une chaîne json ou effectuez l'opération
sur votre html avant de terminer le chargement des données. dom
1. Utilisez les requêtes pour demander, transmettre l'URL et définir le type de données
2. Utilisez
pour convertir les données obtenues par cheerio.load(body) en un. request objet. cheerio3. Utilisez les méthodes
et cheerio de find pour trouver l'élément que vous devez obtenir. get4. Utilisez les méthodes
et cheerio de attr pour obtenir les informations requises. text5. Intégrez les informations ci-dessus dans une chaîne json et utilisez le
de express pour répondre au json au client (mini programme ou autre application). res.json
var express = require('express');var router = express.Router();var bodyParser = require("body-parser");var http = require('http');const cheerio = require('cheerio');/* GET home page. */router.get('/', function (req, res, next) {
res.render('index', {title: 'Express'});
});/* GET 妹子图列表 page. */router.get('/parser', function (req, res, next) {
var json =new Array(); var url = `http://m.mmjpg.com/getmore.php?te=0&page=3`;
var request = require('request');
request(url, function (error, response, body) { if (!error && response.statusCode == 200) { var $ = cheerio.load( body );//将响应的html转换成cheerio对象
var $lis = $('li');//便利列表页的所有的li标签,每个li标签对应的是一条信息
var json = new Array();//需要返回的json数组
var index = 0;
$lis.each(function () {
var h2 = $(this).find("h2");//获取h2标签,方便获取h2标签里的a标签
var a = $(h2).find("a");//获取a标签,是为了得到href和标题
var img = $(this).find("img");//获取预览图
var info =$($($(this).find(".info")).find("span")).get(0);//获取发布时间
var like = $(this).find(".like");//获取点赞次数
//生成json数组
json[index] = new Array({"title":$(a).text(),"href":$(a).attr("href"),"image":$(img).attr("data-img"),"timer":$(info).text(),"like":$(like).text()});
index++;
}) //设置响应头
res.header("contentType", "application/json"); //返回json数据
res.json(json);
}
});
})
;/**
* 从第(1/50)张这样的字符串中提取50出来
* @param $str
* @returns {string}
*/function getNumberFromString($str) {
var start = $str.indexOf("/"); var end = $str.indexOf(")"); return $str.substring(start+1,end);
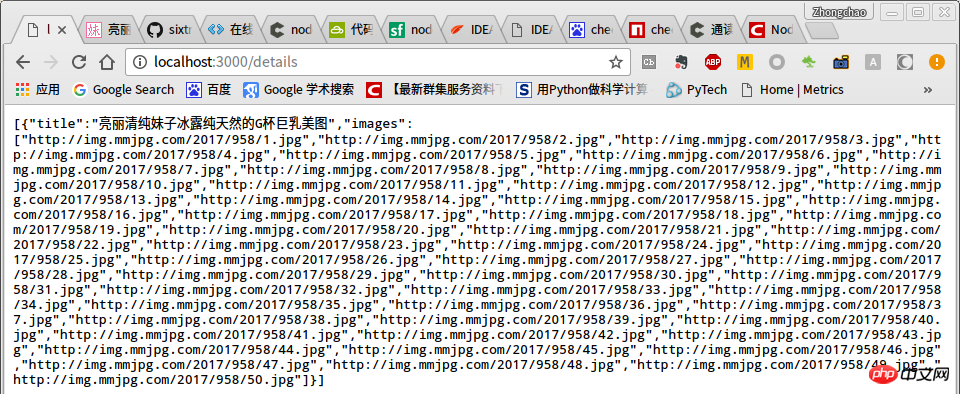
}/* GET 妹子图所有图片 page. */router.get('/details', function (req, res, next) {
var json; var url = `http://m.mmjpg.com/mm/958`;
var request = require('request');
request(url, function (error, response, body) {
if (!error && response.statusCode == 200) { var $ = cheerio.load( body );//将响应的html转换成cheerio对象
var json = new Array();//需要返回的json数组
var index = 0; var img = $($(".content").find("a")).find("img");//每一次操作之后得到的对象都用转换成cheerio对象的
var imgSrc = $(img).attr("src");//获取第一张图片的地址
var title = $(img).attr("alt");//获取图片集的标题
var total =$($(".contentpage").find("span").get(1)).text();//获取‘第(1/50)张’
total = getNumberFromString(total);//从例如`第(1/50)张`提取出50来
var imgPre = imgSrc.substring(0,imgSrc.lastIndexOf("/")+1);//获取图片的地址的前缀
var imgFix = imgSrc.substring(imgSrc.lastIndexOf("."));//获取图片的格式后缀名
console.log(imgPre + "\t" + imgFix); //生成json数组
var images= new Array(); for(var i=1;i<=total;i++) {
images[i-1] =imgPre+i+imgFix;
}
json = new Array({"title":title,"images":images}); //设置响应头
res.header("contentType", "application/json"); //返回json数据
res.json(json);
}
});
})
;
module.exports = router;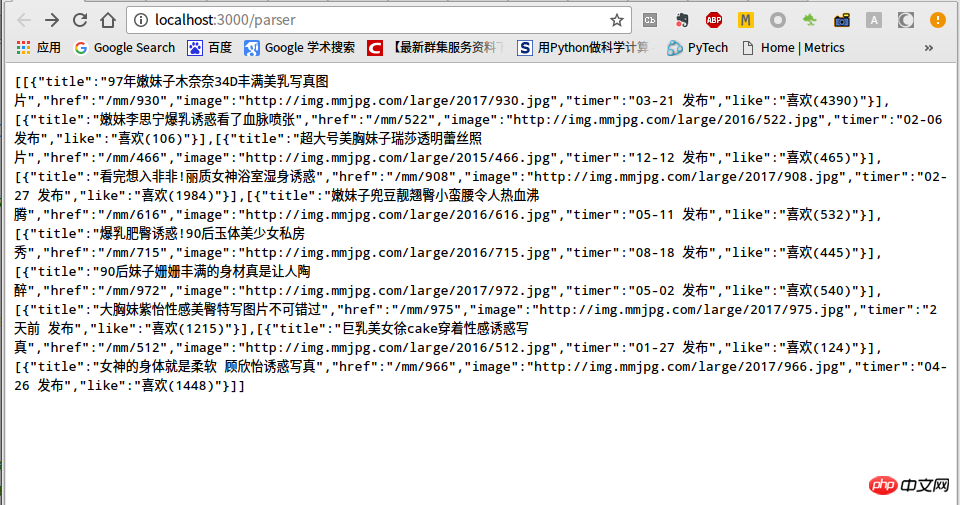
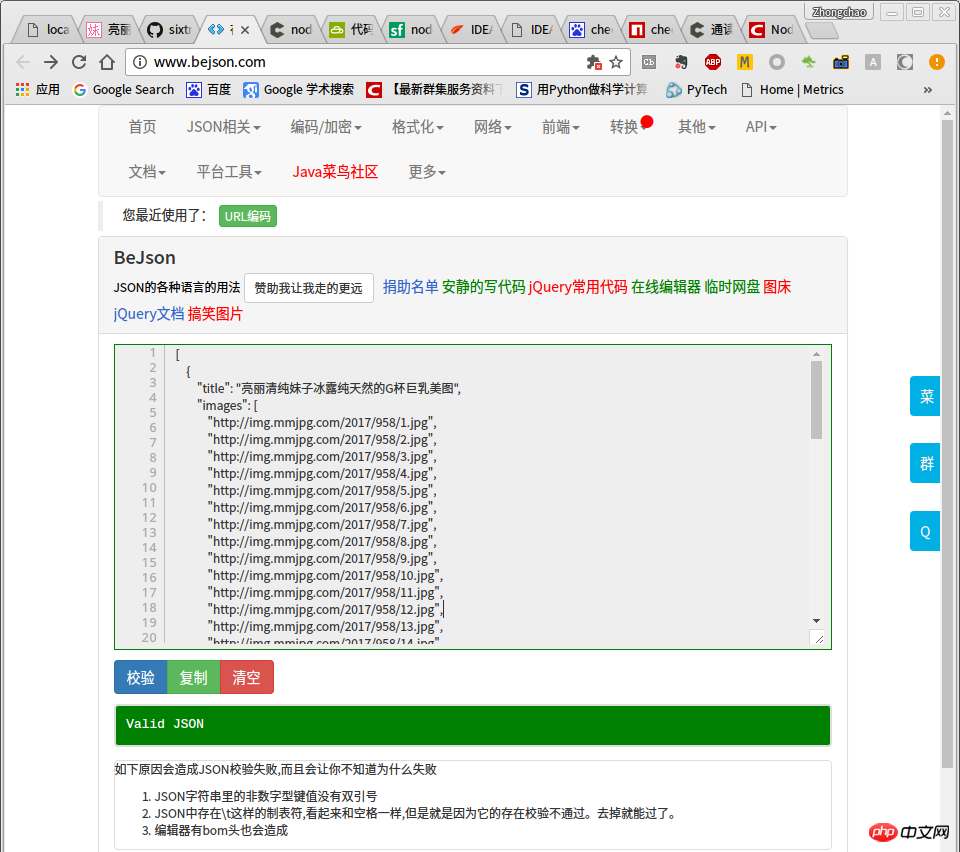
apicloud平台下利用jquery实现的代码
//获取妹子图的列表function loadData() {
url = 'http://m.mmjpg.com/getmore.php';
$.ajax({
url: tmpurl,
method: 'get',
dataType: "application/text",
data:{
te:0,
page:3
},
success: function (data) {
if (data) {
ret = "<ul>" + ret + "</ul>"; var lis = $(ret).find("li"); var one = '';
$(lis).each(function () {
var a = $(this).find("h2 a"); var ahtml = $(a).html();//标题
var ahref = $(a).attr('href');//链接
var info = $(this).find(".info"); var date = $($(info).find("span").get(0)).html(); var like = $($(info).find(".like")).html(); var img = $(this).find("img").get(0); var imgsrc = $(img).attr('data-img'); //接下来,决定如何对数据进行显示咯。如dom操作,直接显示。
});
} else {
alert("数据加载失败,请重试");
}
}
});
};//end of loadData//图片详情页的获取,就不再提供jquery版本的代码了总结
本文主要解决了:1.jquery解析请求过来的html如何实现的问题;2.nodejs环境下jquery重度使用者的替代函数库的问题;3.nodejs下,如何发送ajax请求的问题(ajax请求,本身就是一个request请求);4. 本文用实际的案例来介绍了如何使用cheerio进行dom操作。
【相关推荐】
1. HTML免费视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1206
24
52
1206
24

 Bordure de tableau en HTML
Sep 04, 2024 pm 04:49 PM
Bordure de tableau en HTML
Sep 04, 2024 pm 04:49 PM
Guide de la bordure de tableau en HTML. Nous discutons ici de plusieurs façons de définir une bordure de tableau avec des exemples de bordure de tableau en HTML.
 Tableau imbriqué en HTML
Sep 04, 2024 pm 04:49 PM
Tableau imbriqué en HTML
Sep 04, 2024 pm 04:49 PM
Ceci est un guide des tableaux imbriqués en HTML. Nous discutons ici de la façon de créer un tableau dans le tableau ainsi que des exemples respectifs.
 Marge gauche HTML
Sep 04, 2024 pm 04:48 PM
Marge gauche HTML
Sep 04, 2024 pm 04:48 PM
Guide de la marge HTML gauche. Nous discutons ici d'un bref aperçu de la marge gauche HTML et de ses exemples ainsi que de son implémentation de code.
 Disposition du tableau HTML
Sep 04, 2024 pm 04:54 PM
Disposition du tableau HTML
Sep 04, 2024 pm 04:54 PM
Guide de mise en page des tableaux HTML. Nous discutons ici des valeurs de la mise en page des tableaux HTML ainsi que des exemples et des résultats en détail.
 Espace réservé d'entrée HTML
Sep 04, 2024 pm 04:54 PM
Espace réservé d'entrée HTML
Sep 04, 2024 pm 04:54 PM
Guide de l'espace réservé de saisie HTML. Nous discutons ici des exemples d'espace réservé d'entrée HTML ainsi que des codes et des sorties.
 Déplacer du texte en HTML
Sep 04, 2024 pm 04:45 PM
Déplacer du texte en HTML
Sep 04, 2024 pm 04:45 PM
Guide pour déplacer du texte en HTML. Nous discutons ici d'une introduction, du fonctionnement des balises de sélection avec la syntaxe et des exemples à implémenter.
 Liste ordonnée HTML
Sep 04, 2024 pm 04:43 PM
Liste ordonnée HTML
Sep 04, 2024 pm 04:43 PM
Guide de la liste ordonnée HTML. Ici, nous discutons également de l'introduction de la liste et des types HTML ordonnés ainsi que de leur exemple respectivement.
 Bouton HTML onclick
Sep 04, 2024 pm 04:49 PM
Bouton HTML onclick
Sep 04, 2024 pm 04:49 PM
Guide du bouton HTML onclick. Nous discutons ici de leur introduction, de leur fonctionnement, des exemples et de l'événement onclick dans divers événements respectivement.
