

Pendant le processus d'exploration, il est interdit d'explorer certaines pages avant de vous connecter. À ce stade, vous devez simuler la connexion. L'article suivant présente principalement comment utiliser le robot d'exploration Python pour simuler la connexion Zhihu. Le tutoriel de la méthode est très détaillé dans l'article. Les amis dans le besoin peuvent s'y référer.
Avant-propos
Comme tous ceux qui écrivent souvent des robots le savent, il est interdit d'explorer certaines pages avant de se connecter, comme la page sujet de Zhihu. les utilisateurs doivent se connecter pour accéder, et la « connexion » est indissociable de la technologie Cookie en HTTP.
Principe de connexion
Le principe du Cookie est très simple, car HTTP est un protocole sans état, donc afin d'utiliser le protocole HTTP sans état Le statut de session est maintenu ci-dessus, permettant au serveur de savoir avec quel client il traite actuellement. La technologie Cookie est apparue comme un identifiant attribué par le serveur au client.
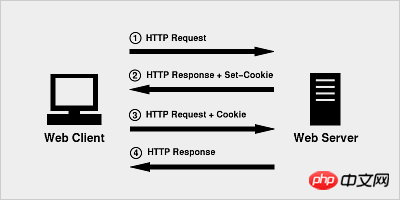
Lorsque le navigateur lance une requête HTTP pour la première fois, il ne transporte aucune information de cookie
Le serveur gère la réponse HTTP, ainsi que les informations de cookie, qui sont renvoyées au navigateur ensemble
Le navigateur envoie les informations de cookie renvoyées par le serveur au serveur avec la deuxième requête
Le serveur reçoit la requête HTTP et constate qu'il y a un champ Cookie dans l'en-tête de la requête, il sait donc qu'il a déjà traité avec cet utilisateur.
Application pratique
Tous ceux qui ont utilisé Zhihu le savent tant que vous fournissez votre nom d'utilisateur et mot de passe et vérification Après avoir entré le code, vous pouvez vous connecter. Bien sûr, c’est exactement ce que nous voyons. Les détails techniques cachés derrière doivent être découverts à l'aide d'un navigateur. Utilisons maintenant Chrome pour voir ce qui se passe une fois que nous avons rempli le formulaire ?
(Si vous êtes déjà connecté, déconnectez-vous d'abord) Accédez d'abord à la page de connexion de Zhihu www.zhihu.com/#signin et ouvrez la barre d'outils du développeur Chrome (appuyez sur F12 ) Essayez d'abord de saisir un code de vérification incorrect et observez comment le navigateur envoie la demande.
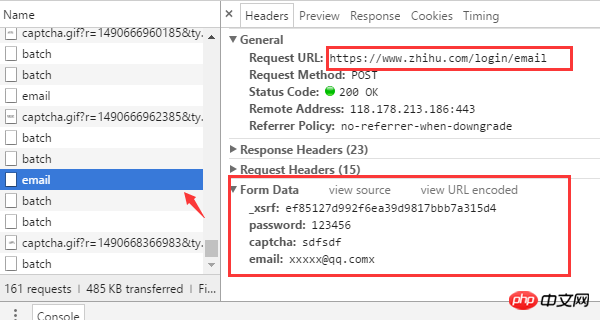
Plusieurs informations clés peuvent être trouvées à partir de la demande du navigateur
L'adresse URL de connexion est https://www. com/login/email
Il y a 4 données de formulaire requises pour la connexion : nom d'utilisateur (e-mail), mot de passe (mot de passe), code de vérification (captcha), _xsrf.
L'adresse URL pour obtenir le code de vérification est https://www.zhihu.com/captcha.gif?r=1490690391695&type=login
Qu'est-ce que _xsrf ? Si vous êtes très familier avec les attaques CSRF (cross-site request forgery), alors vous devez connaître son rôle. xsrf est une chaîne de nombres pseudo-aléatoires, utilisée pour empêcher la falsification de requêtes intersites. Il existe généralement dans la balise form form de la page Web. Pour le confirmer, vous pouvez rechercher "xsrf" sur la page. Effectivement, _xsrf est dans une balise d'entrée cachée
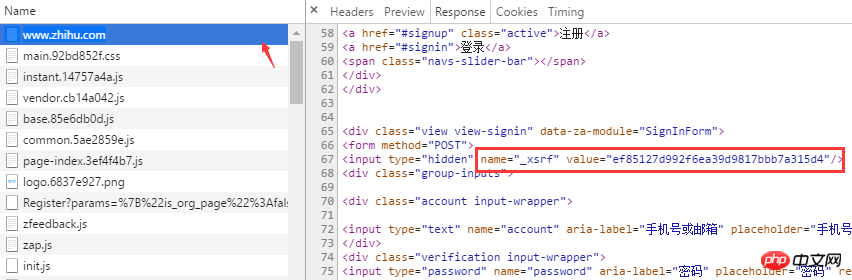
Après avoir clarifié comment obtenir les données requises pour la connexion au navigateur, vous pouvez maintenant commencer à écrire du code pour simuler la connexion au navigateur à l'aide de Python. Les deux bibliothèques tierces utilisées lors de la connexion sont les requêtes et le module BeautifulSoup First
pip install beautifulsoup4==4.5.3 pip install requests==2.13.0
from http import cookiejar
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
session.cookies.load(ignore_discard=True)
except LoadError:
print("load cookies failed")Obtenir xsrf
La balise où se trouve xsrf a été trouvée plus tôt. Vous pouvez utiliser la méthode de recherche de BeatifulSoup pour obtenir. le xsrf très facilement. Valeurdef get_xsrf():
response = session.get("https://www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrfObtenir le code de vérification
Le code de vérification est renvoyé. via l'interface /captcha.gif Oui, ici nous téléchargeons et enregistrons l'image du code de vérification dans le répertoire actuel pour une identification manuelle. Bien sûr, vous pouvez utiliser une bibliothèque de support tierce pour l'identifier automatiquement, comme pytesser.def get_captcha():
"""
把验证码图片保存到当前目录,手动识别验证码
:return:
"""
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
captcha = input("验证码:")
return captchaConnexion
一切参数准备就绪之后,就可以请求登录接口了。
def login(email, password):
login_url = 'www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
for i in session.cookies:
print(i)
session.cookies.save()请求成功后,session 会自动把 服务端的返回的cookie 信息填充到 session.cookies 对象中,下次请求时,客户端就可以自动携带这些cookie去访问那些需要登录的页面了。
auto_login.py 示例代码
# encoding: utf-8
# !/usr/bin/env python
"""
作者:liuzhijun
"""
import time
from http import cookiejar
import requests
from bs4 import BeautifulSoup
headers = {
"Host": "www.zhihu.com",
"Referer": "www.zhihu.com/",
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87'
}
# 使用登录cookie信息
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
print(session.cookies)
session.cookies.load(ignore_discard=True)
except:
print("还没有cookie信息")
def get_xsrf():
response = session.get("www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrf
def get_captcha():
"""
把验证码图片保存到当前目录,手动识别验证码
:return:
"""
t = str(int(time.time() * 1000))
captcha_url = 'www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
captcha = input("验证码:")
return captcha
def login(email, password):
login_url = 'www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
for i in session.cookies:
print(i)
session.cookies.save()
if name == 'main':
email = "xxxx"
password = "xxxxx"
login(email, password)【相关推荐】
1. python爬虫入门(4)--详解HTML文本的解析库BeautifulSoup
2. python爬虫入门(3)--利用requests构建知乎API
3. python爬虫入门(2)--HTTP库requests
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



