

De nos jours, le mot framework est devenu populaire. La conception architecture de la société xx peut être vue partout, mais la plupart d'entre elles sont juste pour le plaisir. D'où viennent ces frameworks. et comment les détails sont-ils pris en compte ? Quelle est la base de l'isolement mutuel... Je pense que de nombreux amis ont encore leurs propres doutes, en particulier avec les microservices de plus en plus populaires et les produits de passerelle de microservices dérivés. J'ai récemment prévu d'écrire un petit framework open source. OSS.Core , j'ai eu quelques réflexions au cours du processus, et je vais les enregistrer à travers cet article, et j'espère que cela pourra aider tout le monde à le comprendre autant que possible, qui tourne probablement autour des questions suivantes :
1. L'origine des microservices
2. L'idée de conception des microservices
3 La conception et la mise en œuvre du framework OSS.Core
Avant de commencer à en parler, j'espère que tout le monde comprendra d'abord l'architecture traditionnelle et les microservices. Les architectures de services ne sont pas indépendantes/opposées les unes aux autres. Les microservices sont un concept logique dérivé du cadre traditionnel pour traiter des problèmes tels que la maintenance simultanée. Il s'agit davantage de changements dans la manière de penser et de résoudre des problèmes à différentes étapes du projet. Deuxièmement, distinguer l'architecture logique de l'architecture physique (fichier). La plupart du temps, l'architecture logique correspond à l'architecture physique, mais parfois une architecture physique peut contenir plusieurs architectures logiques.
1. L'origine des microservices
Les microservices démontent principalement certaines applications volumineuses et complexes en plusieurs combinaisons de services, chaque service est autonome Pour obtenir plus de flexibilité et une maintenance plus facile.
Pour une meilleure compréhension, examinons d'abord trois façons courantes de résoudre la concurrence :
1. Ajouter une séparation maître-esclave de base de données, ou même des mécanismes d'écriture ou de partitionnement multi-maîtres, dans Modifier en conséquence la chaîne de connexion ou ajouter un accès middleware dans l'application pour améliorer la capacité de traitement de la base de données.
2. Étant donné que les ressources de la base de données sont relativement limitées et prennent du temps, afin d'améliorer la vitesse d'accès, des caches distribués etc. sont généralement utilisés pour réduire l'accès à la couche sous-jacente.
3. Le traitement de déchargement d'équilibrage de charge, avant qu'un grand nombre de requêtes n'arrivent à l'application, est distribué sur différentes machines pour résoudre le problème de la bande passante d'une seule machine et des goulots d'étranglement des performances.
Bien sûr, il existe de nombreuses autres façons de résoudre la concurrence, telles que la compression frontale statique de fichiers, l'accélération CDN, le contrôle du débit IP, etc., qui seront ignorées ici.
De nombreux amis auraient dû voir les trois méthodes ci-dessus. La raison pour laquelle elles sont répertoriées ici est que, combinées à cette image, il peut être plus facile de comparer les changements entre les services entiers traditionnels et les microservices :
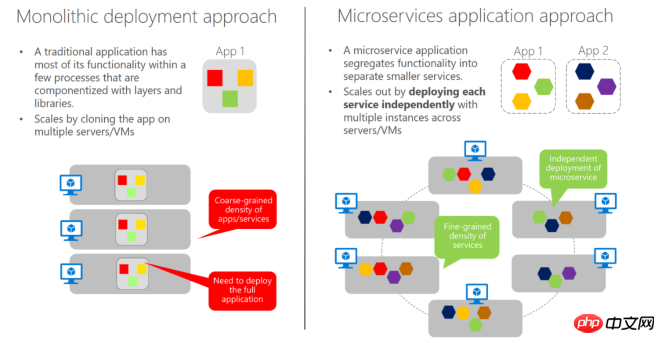
Dans le cadre global de service traditionnel, il existe un excellent couplage entre les modules, les appels mutuels au sein du projet et diverses opérations d'agrégation complexes, donc dans la plupart des cas, cela peut ne doit être déployé que dans son ensemble. Dans l'image de gauche, nous pouvons voir que lors de l'équilibrage de charge, nous devons le déployer dans son ensemble sur plusieurs machines. Il en va de même pour les bases de données et les exigences de chaque module d'un projet. sont différents.
Par exemple : la fréquence d'accès aux produits et aux modules de commande et la complexité du processus sont très différentes. La fréquence des commandes est relativement faible et la complexité est élevée. Nous préférons fonctionner dans un environnement relativement petit et élevé. capacité budgétaire. Sur la machine, il est également pratique pour un dépannage et une maintenance plus rapides. Comme vous pouvez le voir sur l'image de droite, après avoir affiné les services, nous pouvons utiliser des unités de déploiement plus petites pour les combiner en fonction de la situation.
Dans le même temps, à l'ère actuelle d'itération rapide des produits Internet, un produit doit avoir la capacité de lancer rapidement différentes fonctions d'application pour différents terminaux, et en même temps, des ajustements commerciaux peuvent être rapidement lancés. Le modèle de service global traditionnel ne suffit plus. Étant donné que les microservices ont été divisés en plusieurs parties, chaque module peut être rapidement combiné les uns avec les autres en raison de son indépendance, et chaque module peut utiliser des langages de programmation avec des caractéristiques différentes en fonction de différents points de demande.
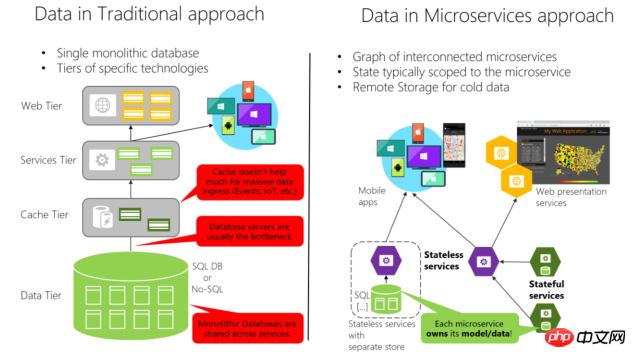
2. Idées de conception de microservices
Parce que chaque produit a ses propres normes et les points clés sont différent lors de la conception des unités de service, mais il y a les points les plus fondamentaux : Autonomie du service
Lorsque vous concevez un module de microservice, vous devez garantir l'indépendance du service actuel, notamment le module de données est indépendant. Les autres services n'ont pas le droit d'exploiter directement le module de base de données sous le service actuel. L'interaction externe ne peut être effectuée que via l'interface du service . Les modules étant indépendants, vous pouvez choisir le langage de programmation approprié et l'échelle de déploiement correspondante. Obtenez une optimisation locale flexible. Si l'indépendance des microservices apporte les commodités ci-dessus, elle pose également certains problèmes auxquels nous devons faire face :
Tout d'abord : Comment définir les limites du service actuel et comment déterminer la portée de la gouvernance actuelle du service.
L'unité de service devant être minimisée, il est nécessaire de déterminer la limite de responsabilité du service. Il est recommandé de combiner cette problématique avec : ServiceCycle de vieProcessus, Champ et Échelle estimée Ces points sont pris en compte de manière exhaustive, tels que les services aux utilisateurs, lors des visites Lorsque la charge de travail est faible et que le personnel est petit, les informations de base sur les utilisateurs et les comptes de solde peuvent être placés sous un module de service pour réduire la charge de travail et les distractions. Lorsque l’échelle est grande, elle peut être divisée en services de base et services d’actifs.
Deuxièmement : Données interservicesRequêteProblèmes
Par exemple, dans le client, 1.APIPasserelle
Cette situation est adaptée lorsqu'il y a trop d'unités de service et que le client doit interroger et utiliser différents services. Pour les données de l'unité, nous pouvons actuellement créer une passerelle de service API (veuillez noter qu'elle est différente de la passerelle APP. Grâce à cette passerelle, plusieurs services sont agrégés avec lesquels le client doit uniquement interagir). la passerelle actuelle, et la passerelle les regroupe et les transmet à différents microservices. Comme indiqué ci-dessous :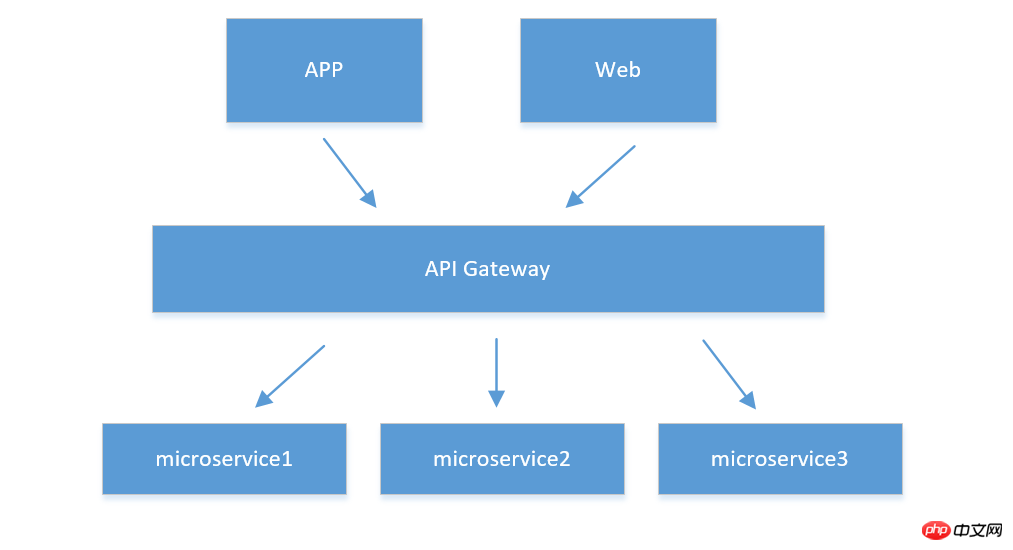
objets complètement différents, qui n'ont pas de performances en temps réel élevées. Ensuite, je suggère de créer un service statistique et une base de données statistique correspondante, et autre. services via l'interaction de message Événement , mise à jour des données statistiques correspondantes et la requête peut être complétée via les propres données du service de statistiques.
Encore une fois : Comment résoudre le problème de communication entre les services
Parce que nous avons rendu les services indépendants les uns des autres et supprimé la possibilité d'exploiter directement différentes bases de données de services . Alors, comment gérer la cohérence des données ? Dans le modèle de service traditionnel, parce qu'ils sont tous mélangés, nous pouvons assurer la cohérence des données via des transactions ou des procédures stockées . Il existe deux méthodes courantes :
1. Message d'événement asynchrone Ce type de solution convient aux scénarios qui ont des exigences relativement faibles en matière de données en temps réel, tels que comme ci-dessus Le service de statistiques est mis à jour. Une fois l'événement de service tel que le passage de commande déclenché, la notification du message de réponse est poussée vers la file d'attente des messages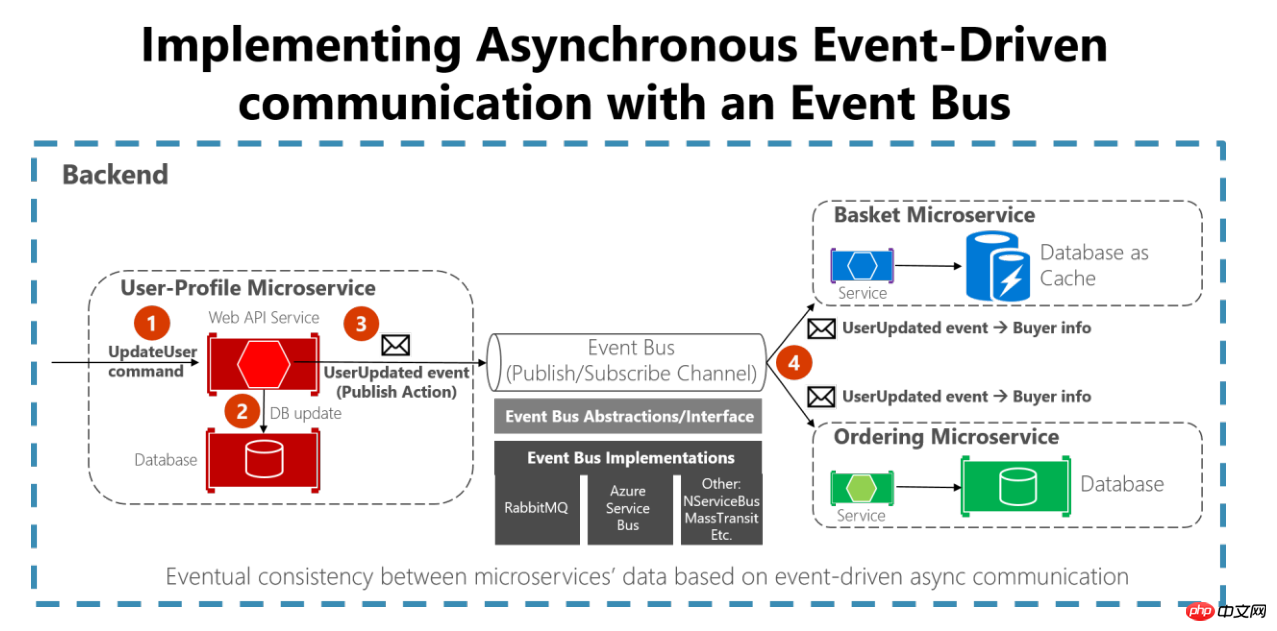
ActionResult> pour réduire la consommation des threads de travail causée par les IO. opérations)
Enfin : Comment le client accède
Après avoir encapsulé le service, la manière dont le service et le client final y accèdent doit être basée sur le sécuritéLes règles et exigences sont déterminées séparément. De manière générale, s'il y a relativement peu de services et que les fonctions ne sont pas trop compliquées, l'interface du service peut être directement exposée au client pour y accéder, comme le montre la figure :
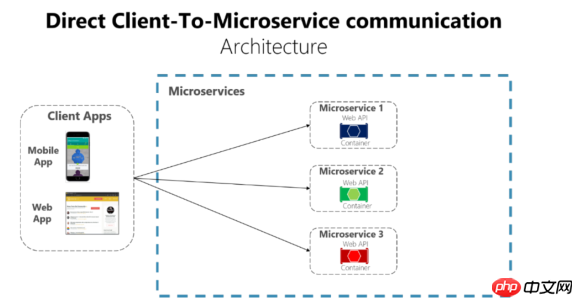 Ou fournissez-le au client sous la forme de
Ou fournissez-le au client sous la forme de
API Gateway mentionné ci-dessus. Bien sûr, il existe également de nombreux microservices matures. des passerelles telles que Service Fabric ou API Management sur le cloud Azure C'est possible.
3. Idées et mise en œuvre du framework OSS.Core Le projet OSS.Core est un petit produit open source que j'ai écrit récemment. Les amis qui le connaissent devraient savoir que j'ai déjà écrit certains composants : OSS.Social, OSS.PayCenter, OSS.Common, OSS.Http. projet J'espère connecter ces composants entre eux. La façon générale de penser les microservices a été présentée ci-dessus. Je ferai de mon mieux pour refléter cela dans l'architecture logique de ce produit. Tout d'abord, montrez le schéma d'architecture physique du projet : Dans ce projet, AdminSite et WebSite sont placés sous le dossier FrontEnds. Les deux sites sont le front-end utilisateur et le front-end de gestion en arrière-plan. end WebApi, Service, DomainMos (Modèles et Interface dans l'image)Bibliothèque de classessous le dossier Layers, formant le base de l'API Infrastructure (classe auxiliaire d'énumération d'entité générale liée à l'entreprise) et Common (classe auxiliaire d'entité non pertinente pour l'entreprise) en tant que bibliothèques de classes d'infrastructure, peuvent être appelées à tous les niveaux des bibliothèques de classes Dépôts (temporairement L'implémentation Mysql d'OSS.Core.RepDapper dans le projet (d'autres supports de bases de données pourront être ajoutés à l'avenir) est principalement l'implémentation spécifique de Rep.. Interface. Les plugs sont des implémentations spécifiques d'interfaces de journalisation, de mise en cache et de configuration sous le plug-in Common, et peuvent être directement appelés à tous les niveaux via Common. Revenons au sujet des microservices, dans ce produit, je ne créerai pas d'ensemble d'implémentations de bibliothèques de classes sous Layers pour chaque service, je séparerai chaque service sous forme d'isolation de dossiers dans ce projet, vous pouvez. considérez WebApi comme une passerelle API. J'espère que la séquence d'appel interne est comme ceci : Diagramme de structure de code actuel : 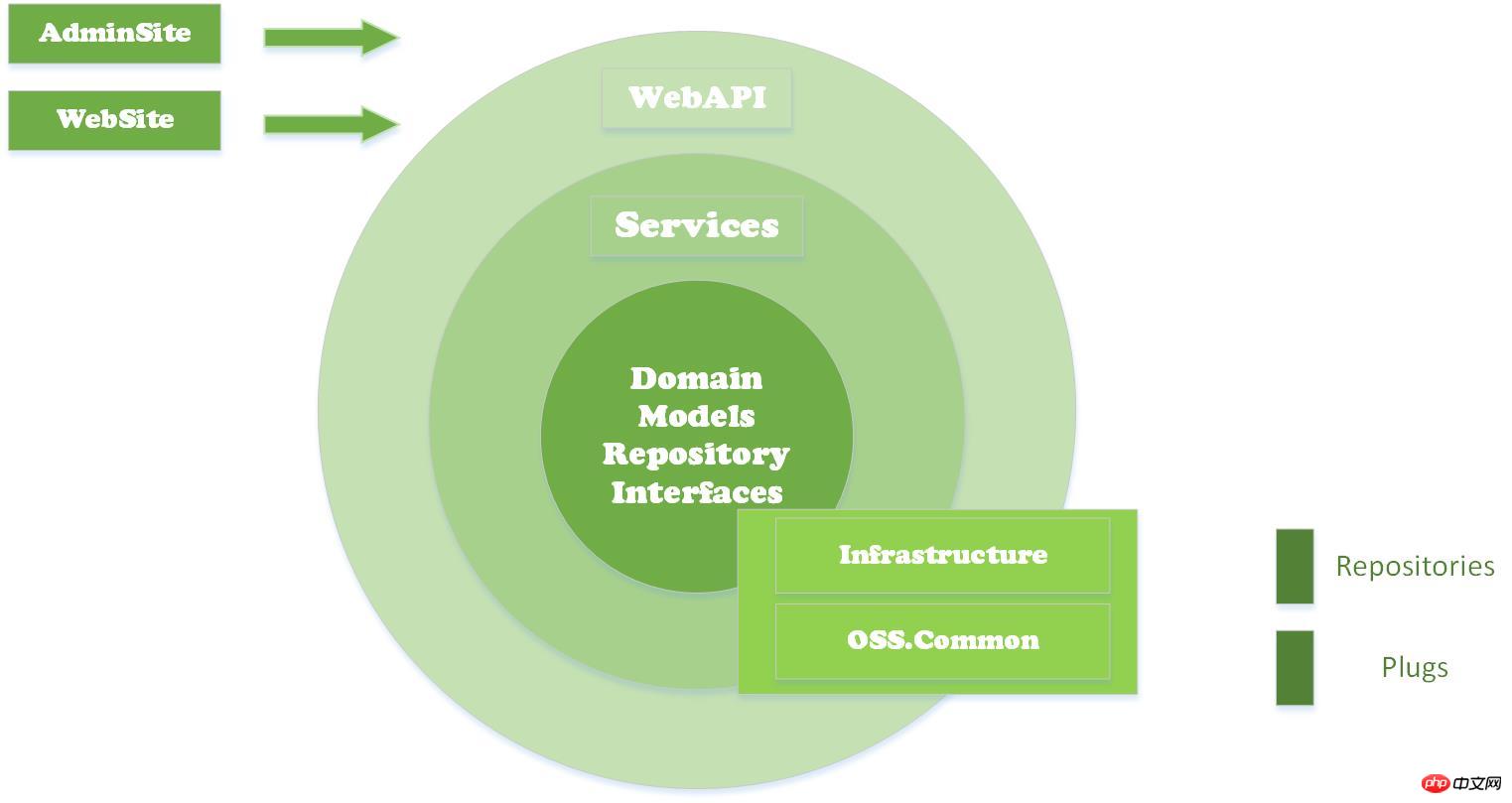
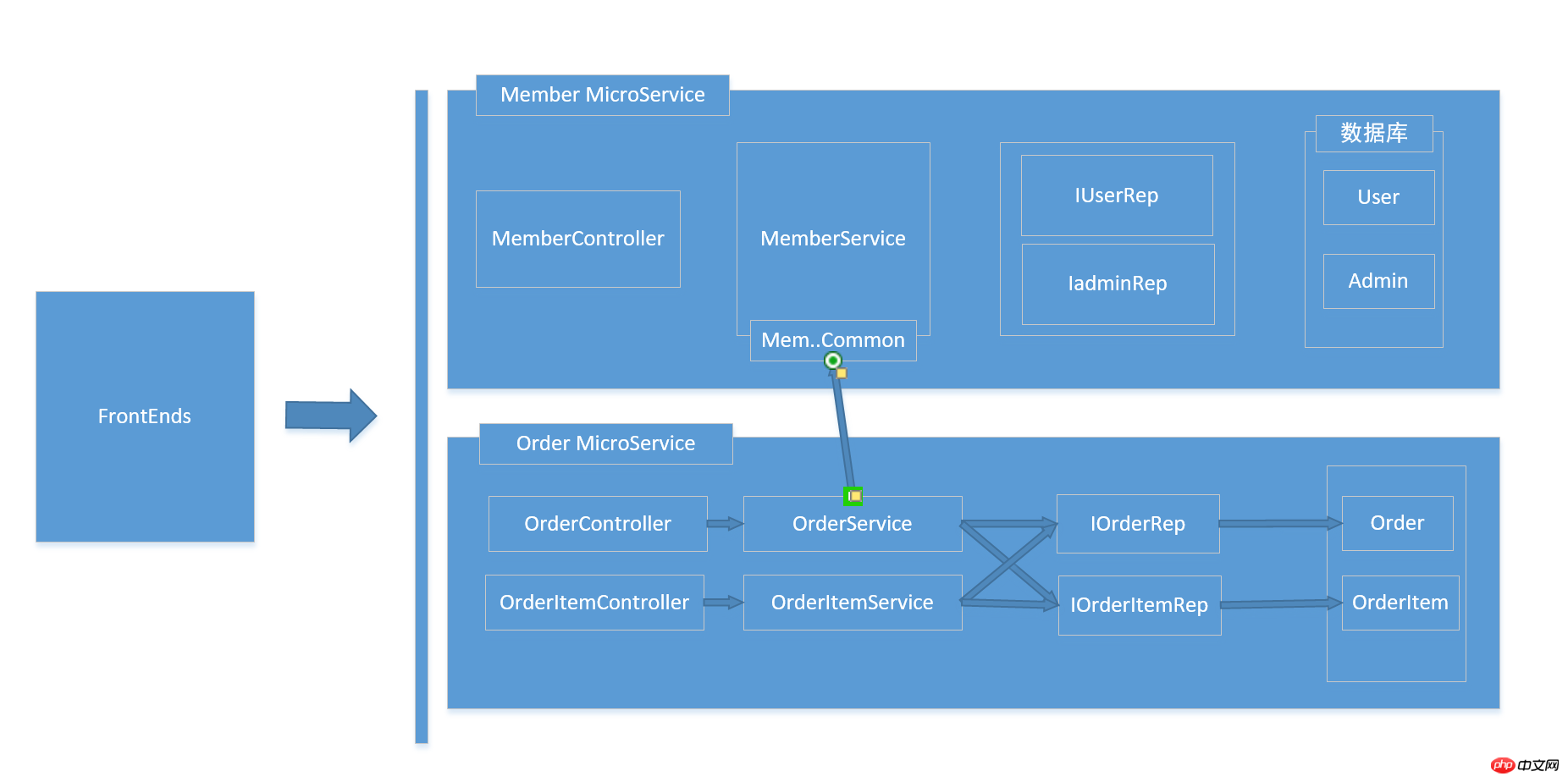
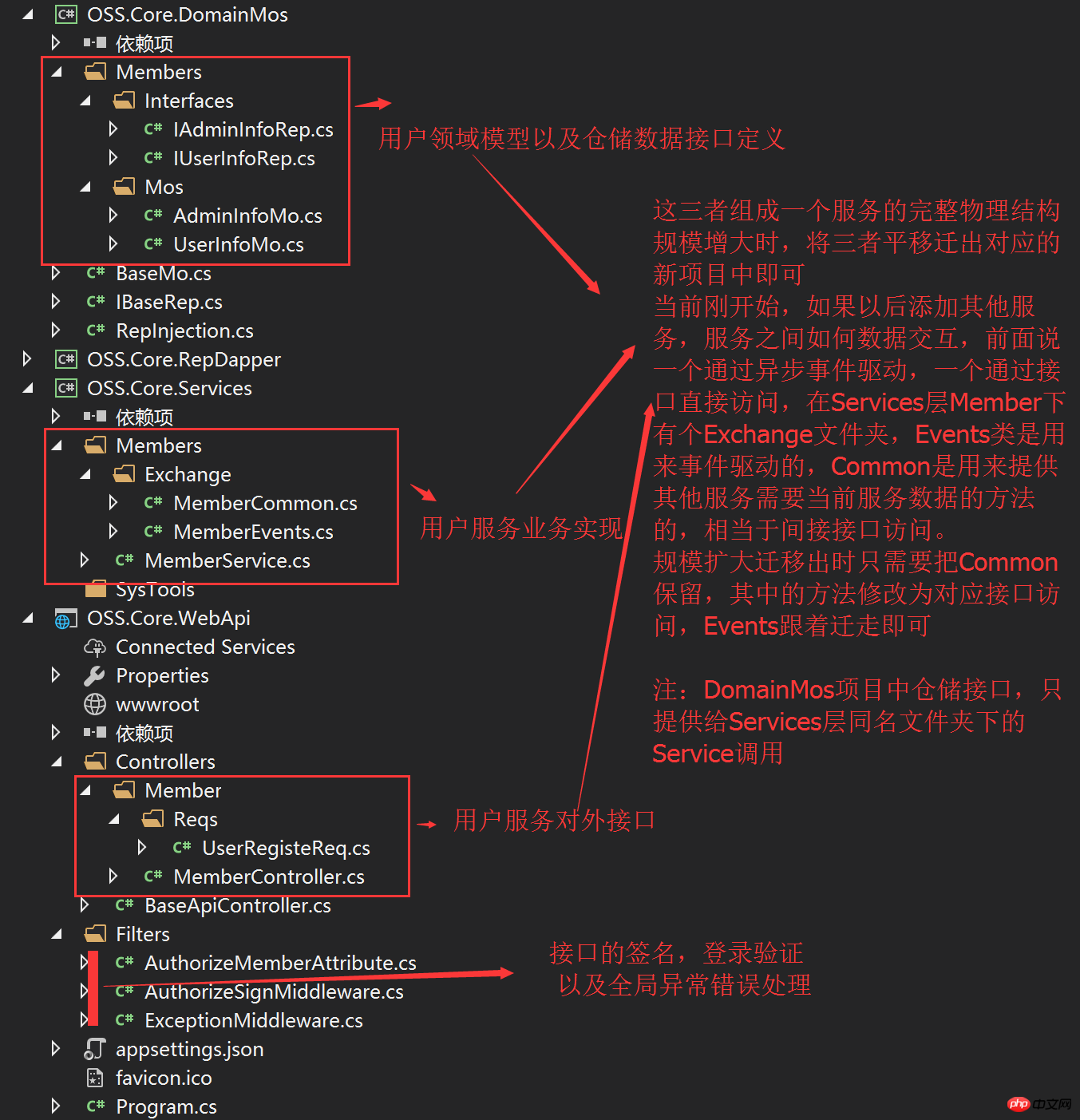
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 conversion RVB en hexadécimal
conversion RVB en hexadécimal
 Quels sont les systèmes d'exploitation mobiles ?
Quels sont les systèmes d'exploitation mobiles ?
 Comment ouvrir le fichier bac
Comment ouvrir le fichier bac
 Le rôle de l'enregistrement d'un serveur cloud
Le rôle de l'enregistrement d'un serveur cloud
 Le lot de script BAT modifie les noms de fichiers
Le lot de script BAT modifie les noms de fichiers
 Frais de location de serveur
Frais de location de serveur
 Quels sont les serveurs exemptés d'enregistrement ?
Quels sont les serveurs exemptés d'enregistrement ?
 Comment fermer la bibliothèque de ressources d'application
Comment fermer la bibliothèque de ressources d'application
 Requête de temps Internet
Requête de temps Internet








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



