
 interface Web
js tutoriel
Exemple d'analyse de code d'un robot d'exploration multipage dans nodejs
interface Web
js tutoriel
Exemple d'analyse de code d'un robot d'exploration multipage dans nodejs
Exemple d'analyse de code d'un robot d'exploration multipage dans nodejs

Cet article présente principalement le robot d'exploration multipage basé sur nodejs L'éditeur pense qu'il est plutôt bon, je vais donc le partager avec vous maintenant et le donner comme référence. Suivons l'éditeur et jetons un oeil.
Préface
J'ai revu le temps du front-endnode.js, donc j'en ai profité de la situation et créé un robot d'exploration. Approfondissez votre compréhension de node.
Les trois modules principalement utilisés sont request, cheerio et async
request
pour demander des adresses et un téléchargement rapide imagesflux.
cheerio
Une implémentation de base jQuery rapide, flexible et implémentée spécialement personnalisée pour le serveur.
Code HTML facile à analyser.
async
Appel asynchrone pour éviter le blocage.
Idée principale
Utilisez la demande pour envoyer une demande. Obtenez le code html et obtenez la balise img et une balise.
Faites un appel récursif à travers l'expression obtenue. Obtenez en continu l'adresse img et une adresse, continuez à récurer
obtenez l'adresse img via request(photo).pipe(fs.createWriteStream(dir + «/» + filename)); pour un téléchargement rapide.
function requestall(url) {
request({
uri: url,
headers: setting.header
}, function (error, response, body) {
if (error) {
console.log(error);
} else {
console.log(response.statusCode);
if (!error && response.statusCode == 200) {
var $ = cheerio.load(body);
var photos = [];
$('img').each(function () {
// 判断地址是否存在
if ($(this).attr('src')) {
var src = $(this).attr('src');
var end = src.substr(-4, 4).toLowerCase();
if (end == '.jpg' || end == '.png' || end == '.jpeg') {
if (IsURL(src)) {
photos.push(src);
}
}
}
});
downloadImg(photos, dir, setting.download_v);
// 递归爬虫
$('a').each(function () {
var murl = $(this).attr('href');
if (IsURL(murl)) {
setTimeout(function () {
fetchre(murl);
}, timeout);
timeout += setting.ajax_timeout;
} else {
setTimeout(function () {
fetchre("http://www.ivsky.com/" + murl);
}, timeout);
timeout += setting.ajax_timeout;
}
})
}
}
});
}Anti-pits
1 Lorsque la demande est téléchargée via l'adresse de l'image, liez l'erreur événement <. 🎜> pour éviter une interruption anormale de Crawler.
hyperliens adresses, qui peuvent être des chemins relatifs (à déterminer s'il existe une solution).
function downloadImg(photos, dir, asyncNum) {
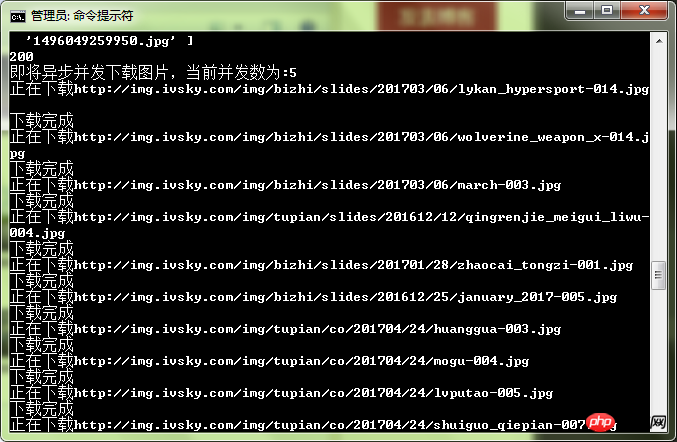
console.log("即将异步并发下载图片,当前并发数为:" + asyncNum);
async.mapLimit(photos, asyncNum, function (photo, callback) {
var filename = (new Date().getTime()) + photo.substr(-4, 4);
if (filename) {
console.log('正在下载' + photo);
// 默认
// fs.createWriteStream(dir + "/" + filename)
// 防止pipe错误
request(photo)
.on('error', function (err) {
console.log(err);
})
.pipe(fs.createWriteStream(dir + "/" + filename));
console.log('下载完成');
callback(null, filename);
}
}, function (err, result) {
if (err) {
console.log(err);
} else {
console.log(" all right ! ");
console.log(result);
}
})
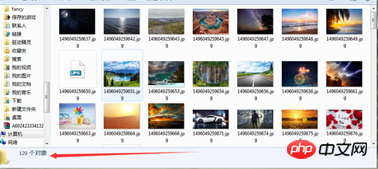
}Test :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La différence entre nodejs et vuejs
Apr 21, 2024 am 04:17 AM
La différence entre nodejs et vuejs
Apr 21, 2024 am 04:17 AM
Node.js est un environnement d'exécution JavaScript côté serveur, tandis que Vue.js est un framework JavaScript côté client permettant de créer des interfaces utilisateur interactives. Node.js est utilisé pour le développement côté serveur, comme le développement d'API de service back-end et le traitement des données, tandis que Vue.js est utilisé pour le développement côté client, comme les applications monopage et les interfaces utilisateur réactives.
 Nodejs est-il un framework backend ?
Apr 21, 2024 am 05:09 AM
Nodejs est-il un framework backend ?
Apr 21, 2024 am 05:09 AM
Node.js peut être utilisé comme framework backend car il offre des fonctionnalités telles que des performances élevées, l'évolutivité, la prise en charge multiplateforme, un écosystème riche et une facilité de développement.
 Comment connecter Nodejs à la base de données MySQL
Apr 21, 2024 am 06:13 AM
Comment connecter Nodejs à la base de données MySQL
Apr 21, 2024 am 06:13 AM
Pour vous connecter à une base de données MySQL, vous devez suivre ces étapes : Installez le pilote mysql2. Utilisez mysql2.createConnection() pour créer un objet de connexion contenant l'adresse de l'hôte, le port, le nom d'utilisateur, le mot de passe et le nom de la base de données. Utilisez connection.query() pour effectuer des requêtes. Enfin, utilisez connection.end() pour mettre fin à la connexion.
 Quelle est la différence entre les fichiers npm et npm.cmd dans le répertoire d'installation de nodejs ?
Apr 21, 2024 am 05:18 AM
Quelle est la différence entre les fichiers npm et npm.cmd dans le répertoire d'installation de nodejs ?
Apr 21, 2024 am 05:18 AM
Il existe deux fichiers liés à npm dans le répertoire d'installation de Node.js : npm et npm.cmd. Les différences sont les suivantes : différentes extensions : npm est un fichier exécutable et npm.cmd est un raccourci de fenêtre de commande. Utilisateurs Windows : npm.cmd peut être utilisé à partir de l'invite de commande, npm ne peut être exécuté qu'à partir de la ligne de commande. Compatibilité : npm.cmd est spécifique aux systèmes Windows, npm est disponible multiplateforme. Recommandations d'utilisation : les utilisateurs Windows utilisent npm.cmd, les autres systèmes d'exploitation utilisent npm.
 Quelles sont les variables globales dans nodejs
Apr 21, 2024 am 04:54 AM
Quelles sont les variables globales dans nodejs
Apr 21, 2024 am 04:54 AM
Les variables globales suivantes existent dans Node.js : Objet global : global Module principal : processus, console, nécessiter Variables d'environnement d'exécution : __dirname, __filename, __line, __column Constantes : undefined, null, NaN, Infinity, -Infinity
 Y a-t-il une grande différence entre nodejs et java ?
Apr 21, 2024 am 06:12 AM
Y a-t-il une grande différence entre nodejs et java ?
Apr 21, 2024 am 06:12 AM
Les principales différences entre Node.js et Java résident dans la conception et les fonctionnalités : Piloté par les événements ou piloté par les threads : Node.js est piloté par les événements et Java est piloté par les threads. Monothread ou multithread : Node.js utilise une boucle d'événements monothread et Java utilise une architecture multithread. Environnement d'exécution : Node.js s'exécute sur le moteur JavaScript V8, tandis que Java s'exécute sur la JVM. Syntaxe : Node.js utilise la syntaxe JavaScript, tandis que Java utilise la syntaxe Java. Objectif : Node.js convient aux tâches gourmandes en E/S, tandis que Java convient aux applications de grande entreprise.
 Nodejs est-il un langage de développement back-end ?
Apr 21, 2024 am 05:09 AM
Nodejs est-il un langage de développement back-end ?
Apr 21, 2024 am 05:09 AM
Oui, Node.js est un langage de développement backend. Il est utilisé pour le développement back-end, notamment la gestion de la logique métier côté serveur, la gestion des connexions à la base de données et la fourniture d'API.
 Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Étapes de déploiement de serveur pour un projet Node.js : Préparez l'environnement de déploiement : obtenez l'accès au serveur, installez Node.js, configurez un référentiel Git. Créez l'application : utilisez npm run build pour générer du code et des dépendances déployables. Téléchargez le code sur le serveur : via Git ou File Transfer Protocol. Installer les dépendances : connectez-vous en SSH au serveur et installez les dépendances de l'application à l'aide de npm install. Démarrez l'application : utilisez une commande telle que node index.js pour démarrer l'application ou utilisez un gestionnaire de processus tel que pm2. Configurer un proxy inverse (facultatif) : utilisez un proxy inverse tel que Nginx ou Apache pour acheminer le trafic vers votre application
