

Analyser le code source du Buffer en Java

Cet article présente principalement des informations pertinentes sur l'analyse du code source de Buffer en Java. Les amis qui en ont besoin peuvent se référer à
Analyse du code source de Buffer en Java
Buffer
Le diagramme de classes de Buffer est le suivant :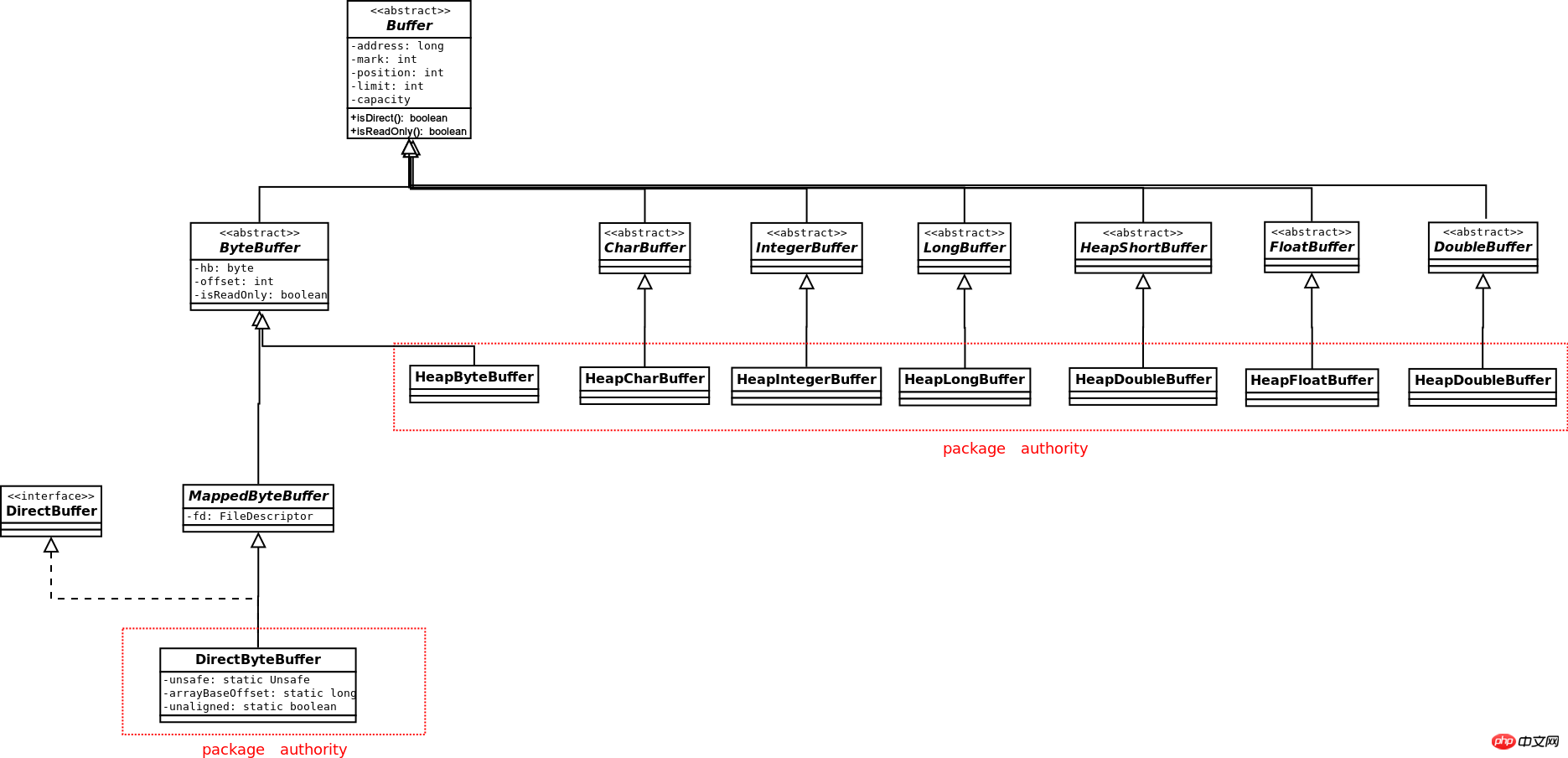
L'essence des tampons de type Direct et Heap
Le premier choix est de parler de la façon dont la JVM effectue les opérations d'E/S. JVM doit effectuer les opérations d'E/S via des appels du système d'exploitation. Par exemple, elle peut terminer la lecture de fichiers via des appels système de lecture. Le prototype de read est :ssize_t read(int fd, void *buf, size_t nbytes), similaire aux autres appels système IO, nécessite généralement un tampon comme l'un des paramètres, et le tampon doit être continu.
Buffer est divisé en deux catégories : Direct et Heap. Ces deux types de tampons sont expliqués ci-dessous.Tas
Type de tas Buffer existe sur le tas JVM Le recyclage et la disposition de cette partie de la mémoire sont les mêmes que ceux des objets ordinaires. Les objets Buffer de type Heap contiennent tous un attribut de tableau correspondant à un type de données de base (par exemple : final **[] hb), et le tableau est le tampon sous-jacent du Buffer de type Heap.- JVM peut déplacer le tampon (copier-organiser) pendant le GC, et l'adresse du tampon n'est pas fixe.
- Lorsque le système est appelé, le tampon doit être continu, mais le tableau peut ne pas être continu (l'implémentation JVM ne nécessite pas de continuité).
Buffer est utilisé comme paramètre pour effectuer des appels au système d'exploitation. Cela se traduit par une très faible efficacité, principalement pour deux raisons :
- Les données doivent être copiées du tampon de type Heap vers le tampon direct créé temporairement.
- peut générer un grand nombre d'objets Buffer, augmentant ainsi la fréquence du GC. Par conséquent, lors des opérations d'E/S, l'optimisation peut être effectuée en réutilisant le Buffer.
Direct
Le tampon de type direct n'existe pas sur le tas, mais est un segment continu alloué directement par la JVM via malloc . Mémoire, cette partie de la mémoire devient la mémoire directe et la JVM utilise la mémoire directe comme tampon lors des appels système IO.Relation entre MappedByteBuffer et DirectByteBuffer
C'est un peu à l'envers : MappedByteBuffer devrait être une sous-classe de DirectByteBuffer, mais pour garder la spécification claire et simple, et à des fins d'optimisation, il est plus facile de procéder dans l'autre sens. Cela fonctionne car DirectByteBuffer est une classe privée du package (ce paragraphe est tiré du code source de MappedByteBuffer)MappedByteBuffer
Obtenez MappedByteBuffer via FileChannel.map (mode MapMode, longue position, taille longue). Le processus de génération de MappedByteBuffer est expliqué ci-dessous avec le code source.
Code source de FileChannel.map :
public MappedByteBuffer map(MapMode mode, long position, long size)
throws IOException
{
ensureOpen();
if (position < 0L)
throw new IllegalArgumentException("Negative position");
if (size < 0L)
throw new IllegalArgumentException("Negative size");
if (position + size < 0)
throw new IllegalArgumentException("Position + size overflow");
//最大2G
if (size > Integer.MAX_VALUE)
throw new IllegalArgumentException("Size exceeds Integer.MAX_VALUE");
int imode = -1;
if (mode == MapMode.READ_ONLY)
imode = MAP_RO;
else if (mode == MapMode.READ_WRITE)
imode = MAP_RW;
else if (mode == MapMode.PRIVATE)
imode = MAP_PV;
assert (imode >= 0);
if ((mode != MapMode.READ_ONLY) && !writable)
throw new NonWritableChannelException();
if (!readable)
throw new NonReadableChannelException();
long addr = -1;
int ti = -1;
try {
begin();
ti = threads.add();
if (!isOpen())
return null;
//size()返回实际的文件大小
//如果实际文件大小不符合,则增大文件的大小,文件的大小被改变,文件增大的部分默认设置为0。
if (size() < position + size) { // Extend file size
if (!writable) {
throw new IOException("Channel not open for writing " +
"- cannot extend file to required size");
}
int rv;
do {
//增大文件的大小
rv = nd.truncate(fd, position + size);
} while ((rv == IOStatus.INTERRUPTED) && isOpen());
}
//如果要求映射的文件大小为0,则不调用操作系统的mmap调用,只是生成一个空间容量为0的DirectByteBuffer
//并返回
if (size == 0) {
addr = 0;
// a valid file descriptor is not required
FileDescriptor dummy = new FileDescriptor();
if ((!writable) || (imode == MAP_RO))
return Util.newMappedByteBufferR(0, 0, dummy, null);
else
return Util.newMappedByteBuffer(0, 0, dummy, null);
}
//allocationGranularity的大小在我的系统上是4K
//页对齐,pagePosition为第多少页
int pagePosition = (int)(position % allocationGranularity);
//从页的最开始映射
long mapPosition = position - pagePosition;
//因为从页的最开始映射,增大映射空间
long mapSize = size + pagePosition;
try {
// If no exception was thrown from map0, the address is valid
//native方法,源代码在openjdk/jdk/src/solaris/native/sun/nio/ch/FileChannelImpl.c,
//参见下面的说明
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {
// An OutOfMemoryError may indicate that we've exhausted memory
// so force gc and re-attempt map
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {
// After a second OOME, fail
throw new IOException("Map failed", y);
}
}
// On Windows, and potentially other platforms, we need an open
// file descriptor for some mapping operations.
FileDescriptor mfd;
try {
mfd = nd.duplicateForMapping(fd);
} catch (IOException ioe) {
unmap0(addr, mapSize);
throw ioe;
}
assert (IOStatus.checkAll(addr));
assert (addr % allocationGranularity == 0);
int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);
if ((!writable) || (imode == MAP_RO)) {
return Util.newMappedByteBufferR(isize,
addr + pagePosition,
mfd,
um);
} else {
return Util.newMappedByteBuffer(isize,
addr + pagePosition,
mfd,
um);
}
} finally {
threads.remove(ti);
end(IOStatus.checkAll(addr));
}
}Implémentation du code source de map0 :
JNIEXPORT jlong JNICALL
Java_sun_nio_ch_FileChannelImpl_map0(JNIEnv *env, jobject this,
jint prot, jlong off, jlong len)
{
void *mapAddress = 0;
jobject fdo = (*env)->GetObjectField(env, this, chan_fd);
//linux系统调用是通过整型的文件id引用文件的,这里得到文件id
jint fd = fdval(env, fdo);
int protections = 0;
int flags = 0;
if (prot == sun_nio_ch_FileChannelImpl_MAP_RO) {
protections = PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_RW) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_PV) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_PRIVATE;
}
//这里就是操作系统调用了,mmap64是宏定义,实际最后调用的是mmap
mapAddress = mmap64(
0, /* Let OS decide location */
len, /* Number of bytes to map */
protections, /* File permissions */
flags, /* Changes are shared */
fd, /* File descriptor of mapped file */
off); /* Offset into file */
if (mapAddress == MAP_FAILED) {
if (errno == ENOMEM) {
//如果没有映射成功,直接抛出OutOfMemoryError
JNU_ThrowOutOfMemoryError(env, "Map failed");
return IOS_THROWN;
}
return handle(env, -1, "Map failed");
}
return ((jlong) (unsigned long) mapAddress);
}Bien que le paramètre zise de FileChannel.map() soit long, la taille maximale de size est Integer.MAX_VALUE, ce qui signifie qu'il ne peut mapper qu'un espace maximum de la 2G. En fait, le MMAP fourni par le système d'exploitation peut allouer un espace plus grand, mais JAVA est limité à 2G, et les tampons tels que ByteBuffer ne peuvent allouer qu'une taille de tampon maximale de 2G.
MappedByteBuffer est un buffer généré via mmap Cette partie du buffer est directement créée et gérée par le système d'exploitation Enfin, la JVM permet au système d'exploitation de libérer directement cette partie de la mémoire via unmmap. .
Haep****Buffer
Ce qui suit utilise ByteBuffer comme exemple pour illustrer les détails du tampon de type Heap.
Ce type de Buffer peut être généré de la manière suivante :
ByteBuffer.allocate(int capacité)
ByteBuffer.wrap(byte[] array) utilise le tableau entrant comme tampon sous-jacent. La modification du tableau affectera le tampon, et la modification du tampon affectera également le tableau.
ByteBuffer.wrap(byte[] array, int offset, int length)
Utiliser une partie du tableau transmis comme tampon sous-jacent, changer la partie correspondante du tableau affectera le tampon, et changer le tampon affectera également le tableau.
DirectByteBuffer
DirectByteBuffer ne peut être généré que par ByteBuffer.allocateDirect (capacité int).
Le code source de ByteBuffer.allocateDirect() est le suivant :
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}Le code source de DirectByteBuffer() est le suivant :
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
//直接内存是否要页对齐,我本机测试的不用
boolean pa = VM.isDirectMemoryPageAligned();
//页的大小,本机测试的是4K
int ps = Bits.pageSize();
//如果页对齐,则size的大小是ps+cap,ps是一页,cap也是从新的一页开始,也就是页对齐了
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//JVM维护所有直接内存的大小,如果已分配的直接内存加上本次要分配的大小超过允许分配的直接内存的最大值会
//引起GC,否则允许分配并把已分配的直接内存总量加上本次分配的大小。如果GC之后,还是超过所允许的最大值,
//则throw new OutOfMemoryError("Direct buffer memory");
Bits.reserveMemory(size, cap);
long base = 0;
try {
//是吧,unsafe可以直接操作底层内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {、
//没有分配成功,把刚刚加上的已分配的直接内存的大小减去。
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}Le code source de unsafe.allocateMemory() se trouve dans openjdk/src/openjdk/hotspot/src/share/vm/prims/unsafe.cpp. Le code source spécifique est le suivant :
UNSAFE_ENTRY(jlong, Unsafe_AllocateMemory(JNIEnv *env, jobject unsafe, jlong size))
UnsafeWrapper("Unsafe_AllocateMemory");
size_t sz = (size_t)size;
if (sz != (julong)size || size < 0) {
THROW_0(vmSymbols::java_lang_IllegalArgumentException());
}
if (sz == 0) {
return 0;
}
sz = round_to(sz, HeapWordSize);
//最后调用的是 u_char* ptr = (u_char*)::malloc(size + space_before + space_after),也就是malloc。
void* x = os::malloc(sz, mtInternal);
if (x == NULL) {
THROW_0(vmSymbols::java_lang_OutOfMemoryError());
}
//Copy::fill_to_words((HeapWord*)x, sz / HeapWordSize);
return addr_to_java(x);
UNSAFE_ENDLa JVM alloue un tampon continu via malloc. Cette partie du tampon peut être directement utilisée comme paramètre de tampon pour le fonctionnement. appels système.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Guide du générateur de nombres aléatoires en Java. Nous discutons ici des fonctions en Java avec des exemples et de deux générateurs différents avec d'autres exemples.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
