
 base de données
tutoriel mysql
Introduction détaillée aux quatre niveaux d'isolation des transactions dans MySQL (image et texte)
base de données
tutoriel mysql
Introduction détaillée aux quatre niveaux d'isolation des transactions dans MySQL (image et texte)
Introduction détaillée aux quatre niveaux d'isolation des transactions dans MySQL (image et texte)

Cet article présente principalement en détail les informations pertinentes sur les quatre niveaux d'isolation des transactions de MySQL, qui ont une certaine valeur de référence. Les amis intéressés peuvent se référer à
L'environnement de test de l'expérience de cet article : Windows 10+cmd+MySQL5. .6.36+InnoDB
1. Éléments de base de la transaction (ACID)
1. Atomicité : toutes les opérations après le démarrage de la transaction, faites tout ou ne faites pas faites-le du tout, et il est impossible de rester coincé au milieu. Si une erreur se produit lors de l'exécution de la transaction, elle sera restaurée à l'état avant le début de la transaction et toutes les opérations se dérouleront comme si elles ne s'étaient pas produites. C’est-à-dire que les choses forment un tout indivisible, tout comme les atomes appris en chimie, qui sont les unités de base de la matière.
2. Cohérence : Avant et après le début et la fin de la transaction, l'intégrité de la base de données contrainte n'a pas été détruite. Par exemple, si A transfère de l’argent à B, il est impossible pour A de déduire l’argent mais B de ne pas le recevoir.
3. Isolement : dans le même temps, une seule transaction est autorisée à demander les mêmes données, et il n'y a aucune interférence entre les différentes transactions. Par exemple, A retire de l'argent d'une carte bancaire. B ne peut pas transférer d'argent sur cette carte avant que le processus de retrait de A ne soit terminé.
4. Durabilité : une fois la transaction terminée, toutes les mises à jour de la base de données par la transaction seront enregistrées dans la base de données et ne pourront pas être annulées.
Résumé : L'atomicité est la base de l'isolement des transactions, l'isolement et la durabilité sont des moyens, et le but ultime est de maintenir la cohérence des données.
2. Problèmes de concurrence des transactions
1. Lecture sale : la transaction A lit les données mises à jour par la transaction B, puis B annule l'opération, puis A lit The les données reçues sont des données sales
2. Lecture non répétable : la transaction A lit les mêmes données plusieurs fois, et la transaction B met à jour et soumet les données lors des multiples lectures de la transaction A, ce qui entraîne une transaction lorsque A lit les mêmes données plusieurs fois, les résultats sont incohérents.
3. Lecture fantôme : l'administrateur système A a modifié les scores de tous les étudiants dans la base de données des scores spécifiques aux notes ABCDE, mais l'administrateur système B a inséré un enregistrement des scores spécifiques à ce moment-là lorsque l'administrateur système a terminé. le changement était terminé, le membre A a découvert qu'il y avait encore un enregistrement qui n'avait pas été modifié. C'était comme s'il avait halluciné.
Résumé : La lecture non répétable et la lecture fantôme sont faciles à confondre. La lecture non répétable se concentre sur la modification, tandis que la lecture fantôme se concentre sur l'ajout ou la suppression. Pour résoudre le problème des lectures non répétables, il vous suffit de verrouiller les lignes qui remplissent les conditions. Pour résoudre le problème des lectures fantômes, vous devez verrouiller la table

. 3. Niveau d'isolement des transactions MySQL
Le niveau d'isolement des transactions par défaut de MySQL est en lecture répétable
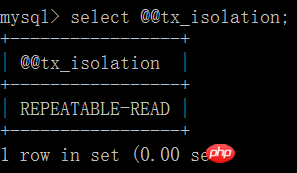
4. Utilisez des exemples pour. illustrer chaque niveau d'isolement
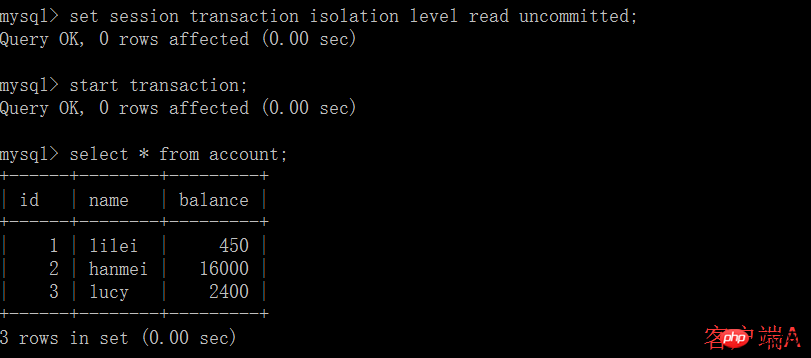
1. Lecture non validée :
(1) Ouvrez un client A et définissez le mode de transaction actuel pour lire non validé (lecture non validée). ), interroger la table Valeur initiale du compte :
(2) Avant que la transaction du client A ne soit validée, ouvrez un autre client B et mettez à jour le compte de la table :
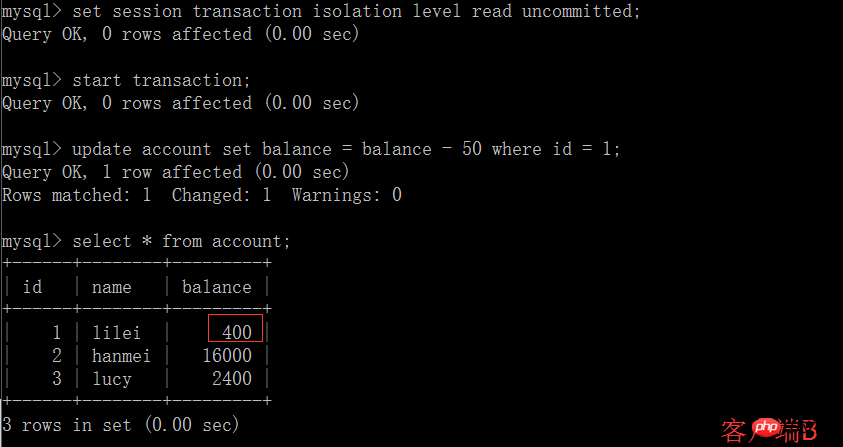
(3) À ce stade, bien que la transaction du client B n'ait pas encore été soumise, le client A peut interroger les données mises à jour de B :
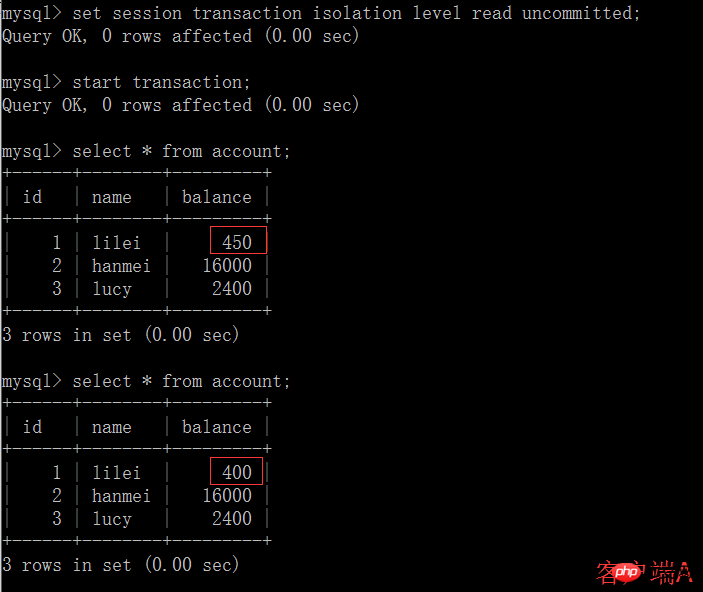
(4) Une fois la transaction du client B annulée pour une raison quelconque, toutes les opérations seront annulées et les données interrogées par le client A sont en fait des données sales :
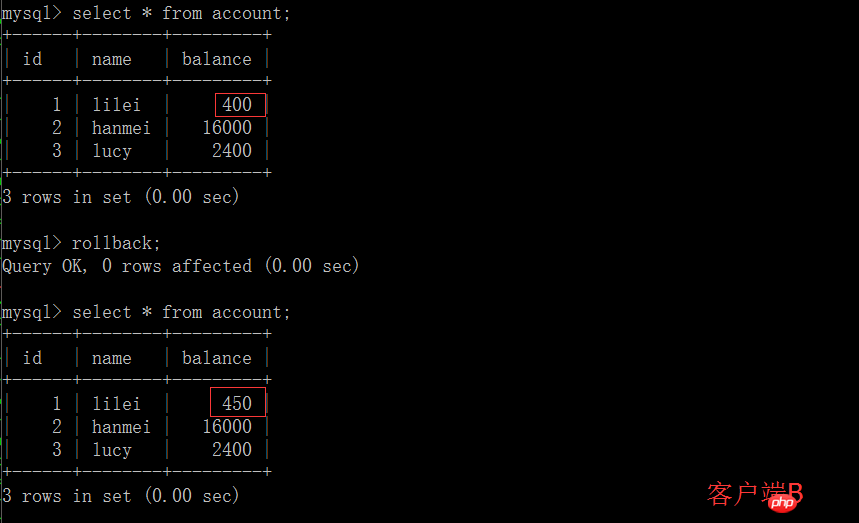
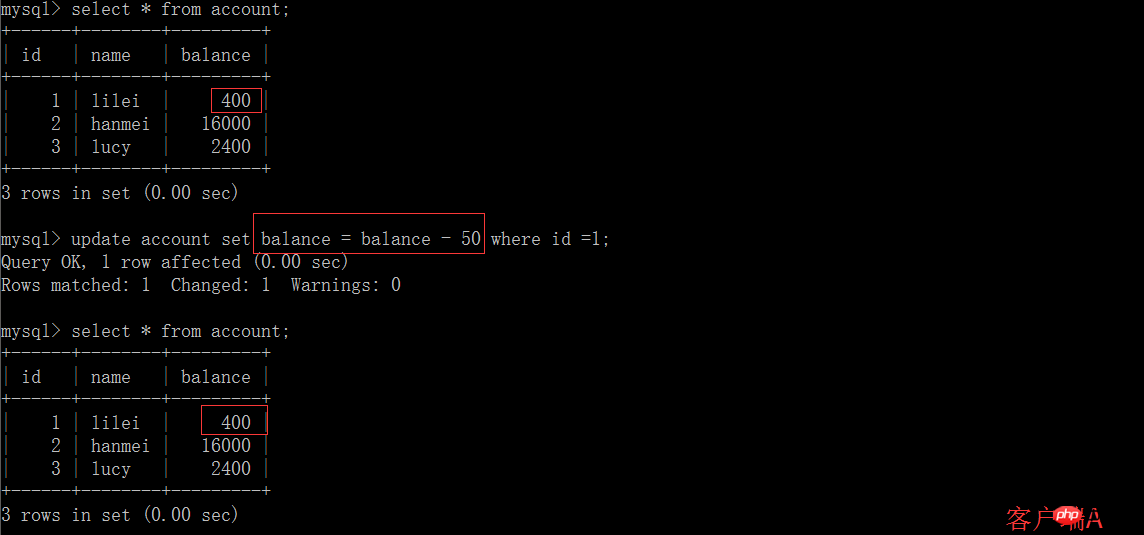
(5) Exécutez l'instruction de mise à jour update account set balance = balance - 50 où id =1 sur le client A. Le solde de lilei n'est pas devenu 350, mais en fait 400. N'est-ce pas étrange que je n'ai pas demandé la cohérence des données ? , Si vous le pensez, vous êtes trop naïf. Dans l'application, nous utiliserons 400-50=350, et nous ne savons pas que d'autres sessions ont été annulées. Pour résoudre ce problème, vous pouvez lire le. soumis Niveau d'isolement
2. Lire validé
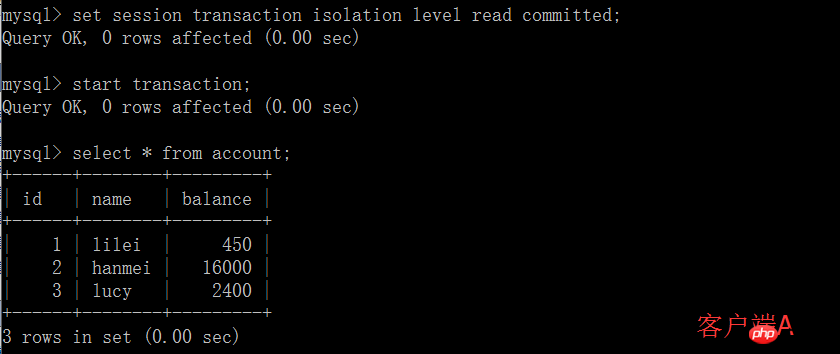
(1) Ouvrez un client A et définissez le mode de transaction actuel sur lire validé (et non soumettre lire), interroger la valeur initiale du compte de table :
(2) Avant que la transaction du client A ne soit validée, ouvrez un autre client B et mettez à jour le compte de table :
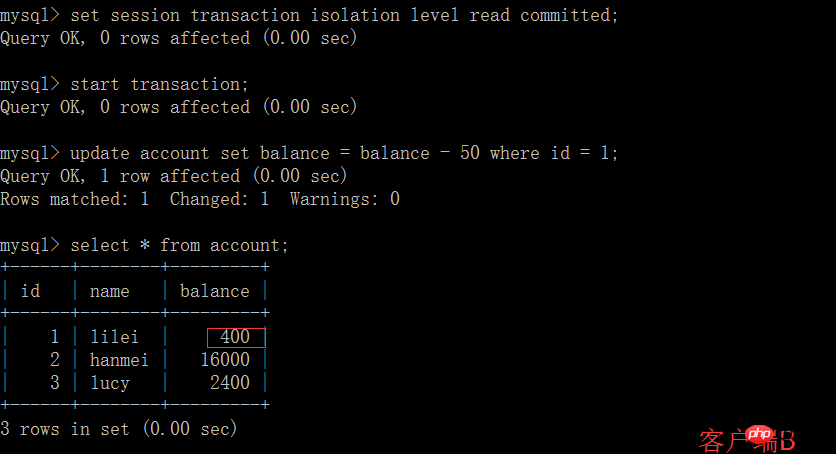
(3) À l'heure actuelle, la transaction du client B n'a pas encore été soumise et le client A ne peut pas interroger les données mises à jour de B, ce qui résout le problème de lecture sale :
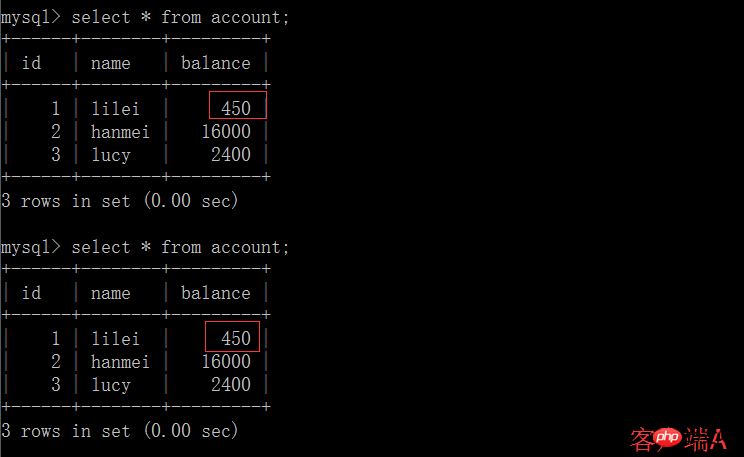
(4) Soumission de la transaction du client B
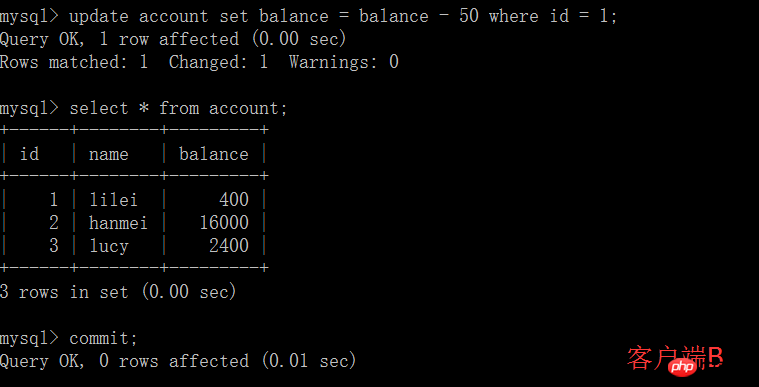
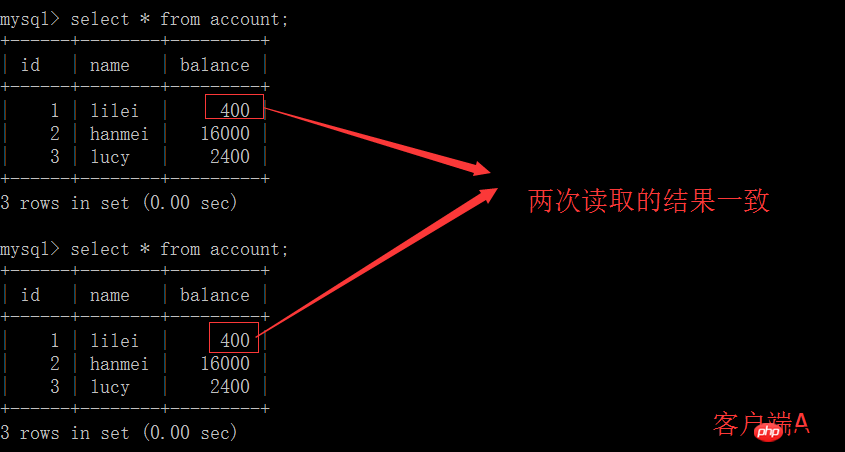
(5) Le client A exécute la même requête qu'à l'étape précédente, et le résultat est L'étape précédente est incohérente, ce qui crée un problème de lecture non reproductible. Dans l'application, en supposant que nous sommes dans la session du client A, nous demandons que le solde de lilei est de 450, mais d'autres transactions modifient la valeur du solde de lilei à 400. Nous ne savons pas qu'il y aura un problème si vous utilisez la valeur 450 pour effectuer d'autres opérations, mais la probabilité est vraiment faible. Pour éviter ce problème, vous pouvez utiliser le niveau d'isolement de lecture répétable
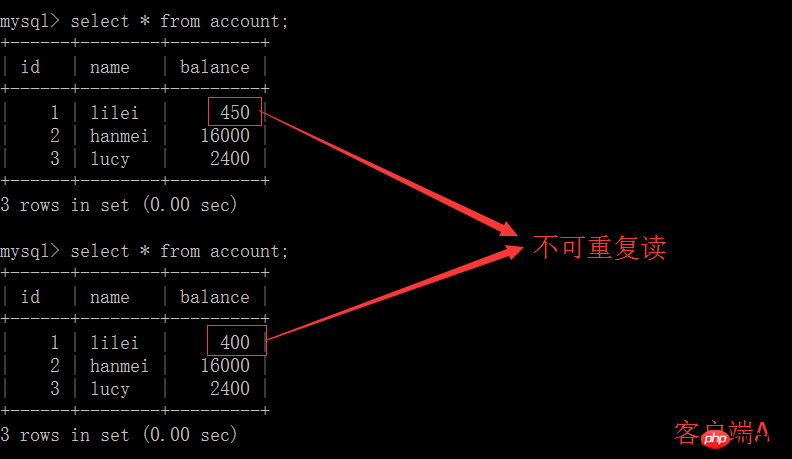
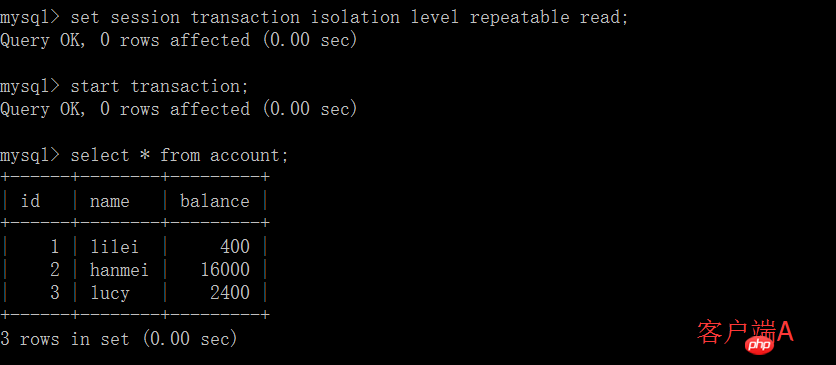
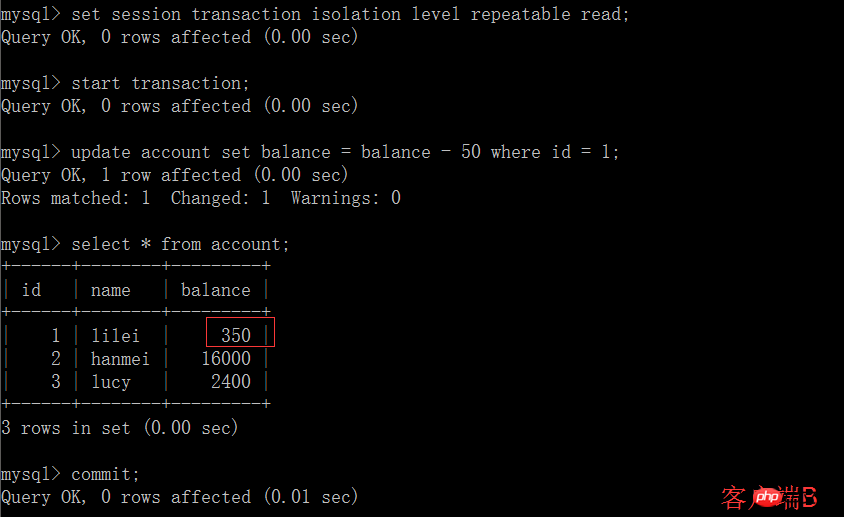
mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 400 | | 2 | hanmei | 16000 | | 3 | lucy | 2400 | +------+--------+---------+ rows in set (0.00 sec) mysql> update account set balance = balance - 50 where id = 1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 300 | | 2 | hanmei | 16000 | | 3 | lucy | 2400 | +------+--------+---------+ rows in set (0.00 sec)
mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 300 | | 2 | hanmei | 16000 | | 3 | lucy | 2400 | +------+--------+---------+ rows in set (0.00 sec)
mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into account values(4,'lily',600); Query OK, 1 row affected (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.01 sec)
mysql> select sum(balance) from account; +--------------+ | sum(balance) | +--------------+ | 18700 | +--------------+ 1 row in set (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> select sum(balance) from account; +--------------+ | sum(balance) | +--------------+ | 19300 | +--------------+ 1 row in set (0.00 sec)
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 10000 | | 2 | hanmei | 10000 | | 3 | lucy | 10000 | | 4 | lily | 10000 | +------+--------+---------+ rows in set (0.00 sec)
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into account values(5,'tom',0); ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
Informations supplémentaires : Différences
2. Lorsque le niveau d'isolement des transactions par défaut dans MySQL est répétable, la lecture est effectuée. les lignes ne seront pas verrouillées 3. Lorsque le niveau d'isolement des transactions est la sérialisation, les données sont lues Verrouillera la table entière 4. Lors de la lecture de cet article, du point de vue d'un développeur, vous pouvez penser que la lecture non répétable et la lecture fantôme n'ont aucun problème logique et que les données finales sont toujours cohérentes. Oui, mais du point de vue de l'utilisateur, il ne peut généralement voir qu'une seule transaction (uniquement le client A, ne connaissant pas l'existence de la transaction). client secret B), et ne prendra pas en compte le phénomène d'exécution simultanée de transactions. Une fois la même transaction effectuée, si les données sont lues plusieurs fois avec des résultats différents, ou si de nouveaux enregistrements apparaissent de nulle part, ils peuvent avoir des doutes. un problème d’expérience utilisateur.5. Lorsqu'une transaction est exécutée dans MySQL, le résultat final n'aura pas de problème de cohérence des données, car dans une transaction, MySQL n'utilise pas nécessairement les résultats intermédiaires de l'opération précédente lors de l'exécution d'une opération. autre La situation réelle des transactions simultanées est traitée, ce qui semble illogique, mais cela garantit la cohérence des données, mais lorsque la transaction est exécutée dans l'application, le résultat d'une opération sera utilisé par l'opération suivante et d'autres calculs seront effectués. C'est pourquoi nous devons être prudents. Nous devons verrouiller les lignes lors de la lecture répétable et verrouiller les tables lors de la sérialisation, sinon la cohérence des données sera détruite.
6. Lorsque les transactions sont exécutées dans MySQL, MySQL traitera complètement chaque transaction en fonction de la situation réelle, ce qui empêchera la cohérence des données d'être détruite, mais l'application suivra des routines logiques, ce qui n'est pas le cas. Aussi intelligent que MySQL, des problèmes de cohérence des données surgiront inévitablement.
7. Plus le niveau d'isolement est élevé, plus les données peuvent être garanties complètes et cohérentes, mais l'impact sur les performances de concurrence sera également plus grand. Vous ne pouvez pas avoir le gâteau et le manger aussi. Pour la plupart des applications, vous pouvez donner la priorité à la définition du niveau d'isolement du système de base de données sur Lecture validée, ce qui peut éviter les lectures incorrectes et offrir de meilleures performances de concurrence. Bien que cela entraîne des problèmes de concurrence tels que des lectures non répétables et des lectures fantômes, dans des situations individuelles où de tels problèmes peuvent survenir, l'application peut utiliser des verrous pessimistes ou optimistes pour les contrôler.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
