

Les caractéristiques de distribution des données déterminent l'efficacité de la compression spatiale. Si le taux de répétition des données stockées est plus élevé, le taux de compression sera généralement plus élevé Type de caractèreles données (CHAR, VARCHAR, TEXT ou BLOB) ; un taux de compression plus élevé, alors que le taux de compression de certaines données binaires ou de certaines données déjà compressées ne sera pas très bon
Introduction
Description Scénarios et solutions d'utilisation de la compression MySQL, y compris les protocoles de transmission compressés, les solutions de colonnes compressées et les solutions de tables compressées.
En ce qui concerne le contenu lié à la compression MySQL, nous pouvons penser aux scénarios suivants liés à la compression :
1 La quantité de données transmises entre le client et le serveur est trop importante. La compression est nécessaire pour économiser la bande passante
2. Le volume de données d'une certaine colonne dans MySQL est important et seules les données d'une certaine colonne sont compressées
3. Il y a trop de données dans une ou plusieurs tables MySQL, les données des tables doivent être compressées et stockées pour réduire l'utilisation de l'espace disque
Ces problèmes ont de bonnes solutions du côté MySQL Pour le premier problème, vous pouvez utiliser le protocole de compression de MySQL pour le résoudre ; pour le premier problème, vous pouvez utiliser le protocole de compression de MySQL pour le résoudre ; les deux problèmes peuvent être parfaitement résolus en utilisant les fonctions de compression et de décompression de MySQL tandis que le troisième problème, le plus complexe, peut être résolu au niveau du moteur ; innodb, tokudb, MyRocks et d'autres moteurs prennent en charge la compression de table. Cet article abordera en détail les problèmes liés au mécanisme de compression MySQL. Voici le contenu principal :
1. Introduction au protocole de compression MySQL
1. Scénarios applicables
Le protocole de compression MySQL convient aux scénarios dans lesquels la quantité de données transmises entre le serveur MySQL et le client est importante, ou la bande passante disponible n'est pas élevée. Les scénarios typiques incluent les deux suivants :
.a. Lors de l'interrogation d'une grande quantité de données, la bande passante n'est pas suffisante (comme lors de l'exportation de données)
b. Lors de la copie, le volume du journal binaire est trop grand. compression et copie.
2. Introduction au protocole de compression
Le protocole de compression fait partie du protocole de communication MySQL Pour activer le protocole de compression pour la transmission de données, le serveur MySQL et le client doivent prendre en charge l'algorithme zlib. . L'activation du protocole de compression entraîne une légère augmentation de la charge CPU. Utilisez Enable Compression Protocol pour activer la fonction de compression du client à l'aide du paramètre -C ou du paramètre --compress=true. Si l'option -C ou compress=true est activée, alors lors de la connexion au segment du serveur, le bit d'indicateur de capacité du serveur de 0x0020 (CLIENT_COMPRESS) sera envoyé après négociation avec le serveur (après 3 poignées de main), le protocole de compression sera. soutenu. En raison de l'utilisation de la compression, le format du paquet de données changera. Les changements spécifiques sont les suivants :
Format du paquet de données non compressé :

Compressé. Format du paquet de données :

Vous avez peut-être remarqué que le format du datagramme compressé est divisé en formats compressés et non compressés. Il s'agit d'une optimisation réalisée par MySQL pour réduire la surcharge du processeur. Si le contenu fait moins de 50 octets, le contenu ne sera pas compressé, mais s'il est supérieur à 50 octets, la fonction de compression sera activée. Les règles spécifiques sont les suivantes :
Lorsque la valeur du troisième champ est égale à 0x00, cela signifie que le paquet courant n'est pas compressé, donc le contenu de n * octet est de 1 * octet ,n * octet, c'est-à-dire type de demande et demande de contenu.
Lorsque la valeur du troisième champ est supérieure à 0x00, cela signifie que le package actuel a été compressé par zlib, donc lors de son utilisation, n * octet doit être décompressé, et le contenu décompressé est 1 * octet, n * octet, qui correspond au type de requête et au contenu de la requête.
3. Pratique de la solution
Ajoutez le paramètre -C ou --compress=true lorsque le client se connecte. Si vous ajoutez la prise en charge du protocole de compression pour la synchronisation, vous devez configurer slave_compressed_protocol=1. Voici un exemple d'utilisation du protocole de compression pour vous connecter au serveur MySQL :
MySQL -h hostip -uroot -p password --compress MySQLdump -h hostip -uroot -p password -default-character-set=utf8 --compress --single-transaction dbname tablename > tablename.sql
Si vous devez activer la transmission compressée dans la réplication maître-esclave, activez l'option slave_compressed_protocol=1 paramètre sur la machine esclave OK.
4. Effet de compression
Vous pouvez observer l'effet de la transmission par compression en utilisant l'option --compress dans MySQLdump, ou en utilisant le paramètre slave_compressed_protocol dans la réplication maître-esclave, c'est facile. pour voir l'effet, aucune capture d'écran ne sera donnée ici.
2. La solution de compression de colonnes MySQL
MySQL ne prend actuellement pas en charge la compression directe de colonnes. Le TMySQL de Tencent dans l'image peut compresser directement les colonnes. Ici, nous introduisons principalement un moyen de sauver le pays, qui consiste à utiliser les fonctions de compression et de décompression fournies par MySQL au niveau métier pour effectuer des opérations de compression et de décompression sur les colonnes. C'est-à-dire que pour compresser une certaine colonne, vous devez appeler la fonction COMPRESS pour compresser le contenu de cette colonne lors de l'écriture, puis le stocker dans la colonne correspondante. Lors de la lecture, utilisez la fonction UNCOMPRESSED pour décompresser le contenu compressé.
1. Scénarios applicables
针对 MySQL 中某个列或者某几个列数据量特别大,一般都是 varchar、text、char 等数据类型。
2、压缩函数简介
MySQL 的压缩函数 COMPRESS 压缩一个字符串,然后返回一个二进制串。使用该函数需要 MySQL 服务端支持压缩,否则会返回 NULL,压缩字段最好采用 varbinary 或者 blob 字段类型保存。使用 UNCOMPRESSED 函数对压缩过的数据进行解压。注意,采用这种方式需要在业务侧做少量改造。压缩后的内容存储方式如下:
a、空字符串就以空字符串存储
b、非空字符串存储方式为前 4 个 bype 保存未压缩的字符串,紧接着保存压缩的字符串
3、方案实践
字段压缩方案涉及到的几个相关的函数如下:
压缩函数
COMPRESS()
解压缩函数
UNCOMPRESS()
字符串长度函数
LENGTH()
未解压字符串长度函数
UNCOMPRESSED_LENGTH()
实践步骤:
a、创建一张测试表
CREATE TABLE IF NOT EXISTS `test`.`test_compress` ( `id` int unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `content` blob NOT NULL COMMENT '内容列', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 COMMENT='压缩测试表';
b、网表中插入压缩的数据
insert into `test`.`test_compress`(content) values(COMPRESS(REPEAT('a',1000)));
c、读取压缩的数据
select UNCOMPRESS(content) from `test`.`test_compress`;
d、查询对应的长度和内容
复制代码 代码如下:
SELECT UNCOMPRESSED_LENGTH(content) AS length, LENGTH(content) AS compress_length, UNCOMPRESS(content), content FROM `test`.`test_compress`
4、压缩效果
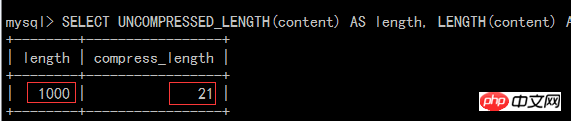
从上面截图可以看出压缩效果比较好,针对 text、char、varchr、blob 等,如果里面重复的数据越多压缩效果就越好。
三、InnoDB 表压缩方案解决方案
1、适用场景
采用压缩表一般都用在由于数据量太大,磁盘空间不足,负载主要体现在 IO 上,而服务器的 CPU 又有比较多的余量的场景。
2、表压缩简介 a、为什么需要压缩
目前很多表都支持压缩,比如 Myisam、InnoDB、TokuDB、MyRocks 。由于使用 InnoDB 主要是不需要做什么改动,对线上完全透明,压缩方案也非常成熟,因此这里只对 InnoDB 做详细说明。对于 TokuDB 和 MyRocks 的压缩方案将在 MySQL 的压缩方案(二)中撰文说明。
在 SSD 没有大量横行的时候,数据库几乎都是 IO 负载型的,在 CPU 有大量余量的时候,磁盘 IO 的瓶颈就已经凸显出来。而数据的大量存储,尤其是日志型数据和监控类型的数据,会导致磁盘空间快速增长。硬盘不够用也会在很多业务中凸显出来。一种比较好的方式就诞生了,那就是通过牺牲少量 CPU 资源,采用压缩来减少磁盘空间占用,以及优化 IO 和带宽。尤其针对读多些少的业务。
SSD 出来后,数据库的 IO 负载有所降低,但是对于磁盘空间的问题还是没有很好的解决。因此压缩表使用还是非常的广泛。这也就是为什么那么多的引擎都支持压缩的原因。而 innodb 在 MySQL 5.5 的时候就支持了压缩功能,只是压缩比比较低,通常在 50%左右。而 tokuDB 能达到 80%左右,MyRocks 的压缩比能达到 70%左右。
注意:压缩比和你存储的数据组成有很大的关系,并不是所有的数据都能达到上面所说的压缩比。如果大部分都是字符串,并且重复的数据比较多,压缩比会很好。
b、innodb 的压缩介绍
使用 innodb 压缩的前提条件是,innodb_file_per_table 这个参数要启用,innodb_file_format 这个参数设置成 Barracuda。
你可以使用 ROW_FORMAT=COMPRESSED 来 create 或者 alter 表来开启 innodb 的压缩功能,如果没有指定 KEY_BLOCK_SIZE 的大小,默认 KEY_BLOCK_SIZE 为 innodb_page_size 大小的一半,也可以通过指定 KEY_BLOCK_SIZE=n 参数来开启 innodb 的压缩功能,n 可以为 1、2、4、8、16,单位是 K。n 的值越小,压缩比越高,消耗的 CPU 资源也越多。注意 32K 或者 64K 的页不支持压缩。启用压缩后,索引数据也同样会被压缩。
你也可以通过调整 innodb_compression_level 来设置压缩的级别,级别从 1~9,默认是 6。级别越低,意味着压缩比越高,同时也意味着需要更多的 CPU 资源。
c、压缩算法
innodb 压缩借助的是著名的 zlib 库,采用 L777 压缩算法,这种算法在减少数据大小和 CPU 利用方面很成熟高效。同时这种算法是无损的,因此原生的未压缩的数据总是能够从压缩文件中重构,LZ777 实现原理是查找重复数据的序列号然后进行压缩,所以数据模式决定了压缩效率,一般而言,用户的数据能够被压缩 50%以上。
d、压缩表在 buffer_pool 中如何处理
在 buffer_pool 缓冲池中,压缩的数据通过 KEY_BLOCK_SIZE 的大小的页来保存,如果要提取压缩的数据或者要更新压缩数据对应的列,则会创建一个未压缩页来解压缩数据,然后在数据更新完成后,会将为压缩页的数据重新写入到压缩页中。内存不足的时候,MySQL 会讲对应的未压缩页踢出去。因此如果你启用了压缩功能,你的 buffer_pool 缓冲池中可能会存在压缩页和未压缩页,也可能只存在压缩页。不过可能仍然需要将你的 buffer_pool 缓冲池调大,以便能同时能保存压缩页和未压缩页。
MySQL 采用最少使用(LRU)算法来确定将哪些页保留在内存中,哪些页剔除出去,因此热数据会更多地保留在内存中。当压缩表被访问的时候,MySQL 使用自适应的 LRU 算法来维持内存中压缩页和非压缩页的平衡。当系统 IO 负载比较高的时候,这种算法倾向于讲未压缩的页剔除,一面腾出更多的空间来存放更多的压缩页。当系统 CPU 负载比较高的时候,MySQL 倾向于将压缩页和未压缩页都剔除出去,这个时候更多的内存用来保留热的数据,从而减少解压的操作。
e、如何评估 KEY_BLOCK_SIZE 是否合适
为了更深入地了解压缩表对性能的影响,在 Information Schema 库中有对应的表可以用来评估内存的使用和压缩率等指标。INNODB_CMP 是收集的是某一类的 KEY_BLOCK_SIZE 压缩表的整体状况的信息,汇总的是所有 KEY_BLOCK_SIZE 压缩表的统计。而 INNODB_CMP_PER_INDEX 表则是收集各个表和索引的压缩情况信息,这些信息对于在某个时间评估某个表的压缩效率或者诊断性能问题很有帮助。INNODB_CMP_PER_INDEX 表的收集会导致系统性能受到影响,必须 innodb_cmp_per_index_enabled 选项才会记录,生产环境最好不要开启。
我们可以通过观察 INNODB_CMP 表的压缩失败情况,如果失败比较多,则需要调大 KEY_BLOCK_SIZE。一般建议 KEY_BLOCK_SIZE 设置为 8。
3、方案实践
a、设置好 innodb_file_per_table 和 innodb_file_format 参数
SET GLOBAL innodb_file_per_table=1;SET GLOBAL innodb_file_format=Barracuda;
b、创建对应的压缩表
复制代码 代码如下:
CREATE TABLE compress_test (c1 INT PRIMARY KEY,content varchar(255)) ROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZE=8;
如果是已经存在的表,则通过 alter 来修改,SQL 如下:
ALTER TABLE compress_test ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
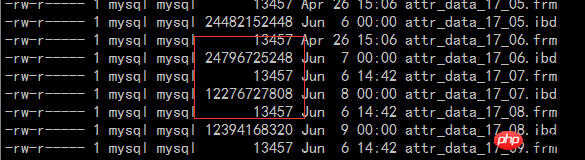
4、压缩效果
压缩效果通过线上的一个监控的表修改为压缩后的文件大小来说明,压缩前后对比如下:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



