

Notes JAVA WEB - Caractères chinois tronqués
Analyse des problèmes de code tronqué JAVA WEB
Cause du code tronqué
Dans le processus de développement Web Java, nous rencontrons souvent le problème du code tronqué La raison du code tronqué. peut être résumé comme un codage de caractères. Ne correspond pas à la méthode de décodage.
Puisque la raison des caractères tronqués est que les méthodes d'encodage et de décodage des caractères ne correspondent pas, alors pourquoi devons-nous encoder les caractères ? Est-il acceptable de ne pas les encoder ? En effet, l'unité de base de stockage des données dans un ordinateur est de 1 octet, soit 8 bits, donc le nombre maximum de caractères qu'il peut exprimer est de 28=256, et dans notre société réelle, il y a beaucoup plus de caractères (caractères chinois, anglais, autres caractères, etc.) que ce nombre, donc afin de résoudre le conflit entre caractères et octets, les caractères doivent être codés avant de pouvoir être stockés dans l'ordinateur.
Encodage et décodage
Les méthodes d'encodage courantes dans les ordinateurs incluent ASCII, ISO-8859-1, GB2312, UTF-16 et UTF-8.
Le code ASCII est représenté par les 7 bits inférieurs d'un octet, donc le nombre maximum de caractères pouvant être exprimés est de 27=128 . ISO-8859-1 est une extension de l'organisation ISO basée sur le code ASCII. Elle est compatible avec le code ASCII et couvre la plupart des caractères d'Europe occidentale. ISO8859-1 utilise un octet pour représenter, il peut donc exprimer jusqu'à 256 caractères. GB2312 utilise un codage sur deux octets. La plage de codage est A1-F7, où A1-A9 est la zone de symboles et B0-F7 est la zone de caractères chinois, contenant 6 763 caractères chinois. GBK consiste à étendre le codage GB2312 et à ajouter davantage de caractères chinois. Il existe 21 003 caractères chinois pouvant être exprimés. UTF-16 utilise une méthode de codage de longueur fixe. Quel que soit le caractère représenté, il est représenté par 2 octets. C'est également le format de stockage des caractères dans la mémoire JAVA. Contrairement à UTF-16, UTF-8 utilise une méthode de codage de longueur variable et différents types de caractères peuvent être composés de 1 à 6 octets.
Jetons un coup d'œil à l'encodage des différentes méthodes d'encodage dans l'ordinateur en utilisant la chaîne "Hyuuga Hinata", comme indiqué ci-dessous.

Analyse et solution du code tronqué
Pour le problème du code tronqué dans JAVA WEB, nous divisons les caractères tronqués causés par les requêtes et les caractères tronqués causés par les réponses. Pour différents caractères tronqués, nous devons analyser les causes des caractères tronqués, c'est-à-dire quelle est la méthode de codage des caractères et quelle est la méthode de décodage. .
Pour le code tronqué provoqué par la requête, nous devons analyser la requête HTTP et vérifier sa méthode d'encodage Étant donné que les requêtes HTTP sont divisées en requêtes Get et requêtes Post, nous en discuterons. séparément ensuite.
Pour la requête Get, il s'agit de la méthode de requête par défaut du navigateur, et de la méthode de soumission lorsque le formulaire est défini sur "Get". Nous vérifions le contenu spécifique via le navigateur Firefox comme suit :
La barre d'adresse est : 
Le contenu de la demande est :

Nous pouvons voir à partir de la requête ci-dessus que la chaîne de requête dans la requête GET est stockée dans la ligne de requête et envoyée au Serveur WEB, grâce à l'encodage "Hyuga Hinata" on peut voir que la méthode d'encodage utilisée par le navigateur pour cette chaîne est "UTF-8".
En regardant le code du serveur, nous pouvons voir des caractères tronqués (comme indiqué ci-dessous) En effet, le serveur décode les données après avoir reçu l'encodage de chaîne par défaut en utilisant ISO-8859-1. . , donc les méthodes de codage et de décodage ne sont pas unifiées.

La solution est la suivante :
Obtenez d'abord l'utilisateur de chaîne avant de décoder l'encodage, puis spécifiez la méthode d'encodage de la chaîne, comme indiqué ci-dessous :

Le diagramme de solution est le suivant suit :

Dans le processus de développement Web Java, nous transmettons des paramètres dans des hyperliens et rencontrons souvent des situations chinoises. Dans ce cas, nous devons encoder le chinois, nous pouvons le définir sur UTF-8 et le schéma de décodage est le même que ci-dessus.
<a href="${pageContext.request.contextPath}/Test?user=<%=URLEncoder.encode("日向雏田", "UTF-8")%>">点击</a>Pour la demande de publication, c'est la méthode de soumission lorsque la soumission du formulaire est définie sur " Poste" . Nous utilisons Firefox pour vérifier son contenu spécifique comme suit :
La barre d'adresse et sa page sont :

Le contenu de la demande de publication est :
, mettez le contenu de la demande directement dans le corps de la demande et envoyez-le au serveur Web, ainsi que la méthode d'encodage est "utf-8". 
Dans cette Servlet de réponse, le corps de la méthode doPost est le suivant :
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String user=request.getParameter("user");
System.out.println(user);//输出为æ¥åéç°
}
L'analyse ci-dessus du code tronqué a provoqué par la demande complète.
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setCharacterEncoding("utf-8"); //设置请求体的编码/解码方案为UTF-8 但是请求行的编码解码方案不会受影响
String user=request.getParameter("user");
System.out.println(user); //输出为日向雏田
}Dans le code tronqué provoqué par l'impact, le serveur Web écrira le contenu de la réponse dans le corps de la réponse et le renverra au client sans impliquer la ligne d'état. Par exemple, si « HelloWorld » est affiché sur le navigateur, la réponse est celle indiquée dans la figure ci-dessous.
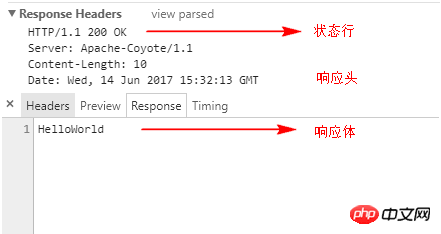 Nous devons impliquer quatre méthodes pour le code tronqué provoqué par la réponse, comme suit :
Nous devons impliquer quatre méthodes pour le code tronqué provoqué par la réponse, comme suit :
response.setHeader("Content-Type", "text/html;cahrset=utf-8");//设置发送到客户端的响应的内容类型和响应内容的编码类型(响应体的编码类型)
response.setCharacterEncoding("utf-8");//设置响应体的编码类型
response.getWriter(); //获取响应的输出字符流
response.getOutputStream(); //获取响应的输出字节流Mais ces deux méthodes sont un peu différentes, c'est-à-dire que la méthode setHeader("Content-Type", "text/html;cahrset=utf-8") sera automatiquement utilisée par le navigateur. La méthode d'encodage du corps de la réponse est décodée et la méthode setCharacterEncoding() n'est pas utilisée par tous les navigateurs pour décoder en utilisant la méthode d'encodage de cette méthode. Les deux méthodes suivantes sont testées et les résultats sont les suivants :
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setHeader("Content-Type", "text/html;charset=utf-8");
response.getWriter().write("日向雏田");
}
从上面可以看到第一个方法对于浏览器来说,支持的较好,提倡采用第一种方法设置响应体的字符编码方式。 对于获取响应字符输出流的方法,如果在此之前没有设置响应体的编码方式,那么默认为null,即ISO-8859-1方式进行编码。而且后面设置的编码方式会覆盖前面设置的编码方式。在getWriter()方法之后设置的编码无效。 对于获取响应输出字节流,我们在输出字符串时,我们需要设置字符串的编码方式如果没有那么默认ISO-8859-1。 对于前面2个输出流,由于只有一个输出缓存,所以这两个方法互斥。 以上,为了保证响应无乱码,需要保证字符编码和解码方法的统一,方案如下: 此外在Java web开发过程中,我们还会遇到当进行文件下载时,中文文件名导致的问题,如下图所示: 采用火狐浏览器进行测试,查看页面效果,及其响应结果如下: 经过查看响应头分析,下载文件名存放在响应头中,且对于中文文字没有采用UTF-8、UTF-16、GBK等等能识别中文的编码,那么对于中文文件名导致采用哪种编码方式呢?查看REF 7578得知,在此处采用ASCII编码,但是REF规定,如果不可避免的要使用非ASCII码的字符,程序员应该均匀的使用UTF-8,来最小化交互操作的问题。 所以,解决方案就是把文件名编码成UTF-8,传递给响应头,浏览器(部分)默认对该文件名进行UTF-8解码处理。 效果如下:其中火狐浏览器并没有对其解码 Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 方案1
// response.setHeader("Content-Type", "text/html;charset=utf-8");
// response.getWriter().write("日向雏田");
// 方案2
// response.getOutputStream().write("日向雏田".getBytes("UTF-8"));
// 方案1,2互斥
} public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
response.setHeader("content-disposition", "attachment;filename="+fileName);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}

public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
String utf_8Name=URLEncoder.encode(fileName,"utf-8");//解决方案
response.setHeader("content-disposition", "attachment;filename="+utf_8Name);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment supprimer les notes Xiaohongshu
Mar 21, 2024 pm 08:12 PM
Comment supprimer les notes Xiaohongshu
Mar 21, 2024 pm 08:12 PM
Comment supprimer les notes de Xiaohongshu ? Les notes peuvent être modifiées dans l'application Xiaohongshu. La plupart des utilisateurs ne savent pas comment supprimer les notes de Xiaohongshu. Ensuite, l'éditeur propose aux utilisateurs des images et des textes expliquant comment supprimer les notes de Xiaohongshu. un regard ensemble ! Tutoriel d'utilisation de Xiaohongshu Comment supprimer les notes de Xiaohongshu 1. Ouvrez d'abord l'application Xiaohongshu et entrez dans la page principale, sélectionnez [Moi] dans le coin inférieur droit pour accéder à la zone spéciale 2. Ensuite, dans la zone Ma, cliquez sur la page de note comme suit : indiqué ci-dessous, sélectionnez la note que vous souhaitez supprimer ; 3. Accédez à la page de notes, cliquez sur [trois points] dans le coin supérieur droit ; 4. Enfin, la barre de fonctions s'agrandira en bas, cliquez sur [Supprimer] pour terminer.
 Comment définir le chinois dans le jeu mobile Call of Duty: Warzone
Mar 22, 2024 am 08:41 AM
Comment définir le chinois dans le jeu mobile Call of Duty: Warzone
Mar 22, 2024 am 08:41 AM
Call of Duty Warzone est un jeu mobile récemment lancé. De nombreux joueurs sont très curieux de savoir comment définir la langue de ce jeu sur le chinois. En fait, c'est très simple. Il suffit aux joueurs de télécharger le pack de langue chinoise, puis vous pouvez le faire. modifiez-le après l'avoir utilisé. Le contenu détaillé peut être appris dans cette introduction à la méthode de réglage chinoise. Comment définir la langue chinoise pour le jeu mobile Call of Duty : Warzone 1. Entrez d'abord dans le jeu et cliquez sur l'icône des paramètres dans le coin supérieur droit de l'interface. 2. Dans la barre de menu qui apparaît, recherchez l'option [Télécharger] et cliquez dessus. 3. Sélectionnez [SIMPLIFIEDCHINESE] (chinois simplifié) sur cette page pour télécharger le package d'installation en chinois simplifié. 4. Revenir aux paramètres
 Configurer le chinois avec VSCode : le guide complet
Mar 25, 2024 am 11:18 AM
Configurer le chinois avec VSCode : le guide complet
Mar 25, 2024 am 11:18 AM
Configuration de VSCode en chinois : un guide complet Dans le développement de logiciels, Visual Studio Code (VSCode en abrégé) est un environnement de développement intégré couramment utilisé. Pour les développeurs qui utilisent le chinois, la configuration de VSCode sur l'interface chinoise peut améliorer l'efficacité du travail. Cet article vous fournira un guide complet, détaillant comment définir VSCode sur une interface chinoise et fournissant des exemples de code spécifiques. Étape 1 : Téléchargez et installez le pack de langue. Après avoir ouvert VSCode, cliquez sur la gauche.
 Comment configurer le tableau Excel pour afficher le chinois ? Tutoriel sur les opérations de commutation en chinois avec Excel
Mar 14, 2024 pm 03:28 PM
Comment configurer le tableau Excel pour afficher le chinois ? Tutoriel sur les opérations de commutation en chinois avec Excel
Mar 14, 2024 pm 03:28 PM
La feuille de calcul Excel est l'un des logiciels de bureau que de nombreuses personnes utilisent actuellement. Certains utilisateurs, parce que leur ordinateur est un système Win11, donc l'interface anglaise s'affiche, ils souhaitent passer à l'interface chinoise, mais ils ne savent pas comment l'utiliser. Pour résoudre ce problème, ce problème L'éditeur est là pour répondre aux questions de tous les utilisateurs. Jetons un coup d'œil au contenu partagé dans le didacticiel du logiciel d'aujourd'hui. Tutoriel pour passer d'Excel au chinois : 1. Entrez dans le logiciel et cliquez sur l'option "Fichier" sur le côté gauche de la barre d'outils en haut de la page. 2. Sélectionnez « options » parmi les options ci-dessous. 3. Après être entré dans la nouvelle interface, cliquez sur l'option « langue » à gauche
 Que dois-je faire si les notes que j'ai publiées sur Xiaohongshu sont manquantes ? Quelle est la raison pour laquelle les notes qu'il vient d'envoyer sont introuvables ?
Mar 21, 2024 pm 09:30 PM
Que dois-je faire si les notes que j'ai publiées sur Xiaohongshu sont manquantes ? Quelle est la raison pour laquelle les notes qu'il vient d'envoyer sont introuvables ?
Mar 21, 2024 pm 09:30 PM
En tant qu'utilisateur de Xiaohongshu, nous avons tous été confrontés à la situation où les notes publiées ont soudainement disparu, ce qui est sans aucun doute déroutant et inquiétant. Dans ce cas, que devons-nous faire ? Cet article se concentrera sur le thème « Que faire si les notes publiées par Xiaohongshu sont manquantes » et vous donnera une réponse détaillée. 1. Que dois-je faire si les notes publiées par Xiaohongshu manquent ? Premièrement, ne paniquez pas. Si vous constatez que vos notes manquent, il est essentiel de rester calme et de ne pas paniquer. Cela peut être dû à une défaillance du système de la plateforme ou à des erreurs opérationnelles. Vérifier les enregistrements de version est facile. Ouvrez simplement l'application Xiaohongshu et cliquez sur « Moi » → « Publier » → « Toutes les publications » pour afficher vos propres enregistrements de publication. Ici, vous pouvez facilement trouver des notes publiées précédemment. 3.Repost. Si trouvé
 Est-ce que wwe2k24 aura du chinois ?
Mar 13, 2024 pm 04:40 PM
Est-ce que wwe2k24 aura du chinois ?
Mar 13, 2024 pm 04:40 PM
"WWE2K24" est un jeu de sports de course créé par Visual Concepts et sorti officiellement le 9 mars 2024. Ce jeu a été très apprécié et de nombreux joueurs souhaitent vivement savoir s'il aura une version chinoise. Malheureusement, jusqu'à présent, "WWE2K24" n'a pas encore lancé de version en langue chinoise. wwe2k24 sera-t-il en chinois ? Réponse : Le chinois n'est pas actuellement pris en charge. La version standard de WWE2K24 dans la région chinoise de Steam est au prix de 199 yuans, la version de luxe est de 329 yuans et l'édition commémorative est de 395 yuans. Le jeu a des exigences de configuration relativement élevées et il existe certaines normes en termes de processeur, de carte graphique ou de mémoire opérationnelle. Configuration officielle recommandée et introduction à la configuration minimale :
 Comment ajouter des liens de produits dans les notes dans Xiaohongshu Tutoriel sur l'ajout de liens de produits dans les notes dans Xiaohongshu
Mar 12, 2024 am 10:40 AM
Comment ajouter des liens de produits dans les notes dans Xiaohongshu Tutoriel sur l'ajout de liens de produits dans les notes dans Xiaohongshu
Mar 12, 2024 am 10:40 AM
Comment ajouter des liens de produits dans les notes dans Xiaohongshu ? Dans l'application Xiaohongshu, les utilisateurs peuvent non seulement parcourir divers contenus mais également faire des achats, il y a donc beaucoup de contenu sur les recommandations d'achat et le bon partage de produits dans cette application si vous êtes un expert. sur cette application, vous pouvez également partager des expériences d'achat, trouver des commerçants pour coopérer, ajouter des liens dans des notes, etc. De nombreuses personnes sont prêtes à utiliser cette application pour faire du shopping, car elle est non seulement pratique, mais elle a également de nombreux experts qui en feront recommandations. Vous pouvez parcourir du contenu intéressant et voir s'il existe des produits vestimentaires qui vous conviennent. Voyons comment ajouter des liens de produits aux notes ! Comment ajouter des liens de produits aux notes de Xiaohongshu Ouvrez l'application sur le bureau de votre téléphone mobile. Cliquez sur la page d'accueil de l'application
 Conseils pour résoudre les caractères chinois tronqués lors de l'écriture de fichiers txt avec PHP
Mar 27, 2024 pm 01:18 PM
Conseils pour résoudre les caractères chinois tronqués lors de l'écriture de fichiers txt avec PHP
Mar 27, 2024 pm 01:18 PM
Conseils pour résoudre les caractères chinois tronqués écrits par PHP dans des fichiers txt Avec le développement rapide d'Internet, PHP, en tant que langage de programmation largement utilisé, est utilisé par de plus en plus de développeurs. Dans le développement PHP, il est souvent nécessaire de lire et d'écrire des fichiers texte, y compris des fichiers txt qui écrivent du contenu chinois. Cependant, en raison de problèmes de format d'encodage, le chinois écrit apparaîtra parfois tronqué. Cet article présentera quelques techniques pour résoudre le problème des caractères chinois tronqués écrits dans des fichiers txt par PHP et fournira des exemples de code spécifiques. Analyse de problèmes en PHP, texte
