
Combien d'octets un objet occupe-t-il ?
Concernant la taille de l'objet, pour C/C++, il existe une fonction sizeof qui peut être obtenue directement, mais Java ne semble pas disposer d'une telle méthode. Heureusement, la classe Instrumentation a été introduite après JDK 1.5. Cette classe fournit une méthode pour calculer l'empreinte mémoire d'un objet. Quant à la façon d'utiliser la classe Instrumentation spécifique, je n'entrerai pas dans les détails. Vous pouvez vous référer à cet article sur la façon de mesurer avec précision la taille des objets Java.
Mais une différence est que cet article utilise la ligne de commande pour transmettre les paramètres JVM afin de spécifier l'agent. Ici, j'ai défini les paramètres JVM via Eclipse :

Ce qui suit est le chemin spécifique vers l'agent.jar que j'ai tapé. Je ne parlerai pas du reste, mais jetez un oeil au code du test :
1 public class JVMSizeofTest { 2 3 @Test 4 public void testSize() { 5 System.out.println("Object对象的大小:" + JVMSizeof.sizeOf(new Object()) + "字节"); 6 System.out.println("字符a的大小:" + JVMSizeof.sizeOf('a') + "字节"); 7 System.out.println("整型1的大小:" + JVMSizeof.sizeOf(new Integer(1)) + "字节"); 8 System.out.println("字符串aaaaa的大小:" + JVMSizeof.sizeOf(new String("aaaaa")) + "字节"); 9 System.out.println("char型数组(长度为1)的大小:" + JVMSizeof.sizeOf(new char[1]) + "字节");10 }11 12 }Le résultat en cours d'exécution est :
Object对象的大小:16字节 字符a的大小:16字节 整型1的大小:16字节 字符串aaaaa的大小:24字节 char型数组(长度为1)的大小:24字节
Ensuite, le code reste inchangé, ajoutez un paramètre de machine virtuelle "-XX:-UseCompressedOops", et exécutez à nouveau la classe de test, le résultat en cours d'exécution est :
Object对象的大小:16字节 字符a的大小:24字节 整型1的大小:24字节 字符串aaaaa的大小:32字节 char型数组(长度为1)的大小:32字节
La raison sera expliquée en détail plus tard.
Méthode de calcul de la taille des objets Java
Taille JVM pour les objets ordinaires et les objets tableau. la méthode de calcul est différente, j'ai fait un dessin pour illustrer :
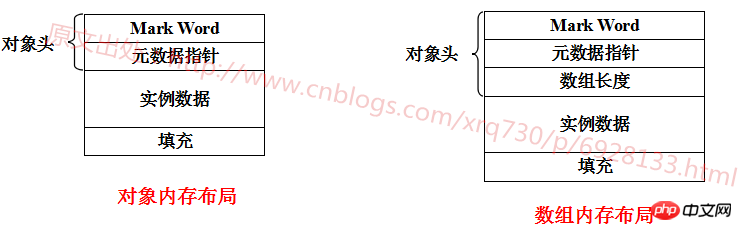
Expliquez chaque partie :
Marquer le mot : stocke les informations enregistrées lors de l'exécution de l'objet, et la taille de la mémoire occupée est la même que le nombre de chiffres de la machine, soit 32 -bit machine occupe 4 octets, 64 bits machine occupe 8 octets
Pointeur de métadonnées : pointe vers l'objet Klass décrivant le type ( l'homologue C++ du pointeur de classe Java), l'objet Klass contient des métadonnées du type auquel appartient l'objet d'instance, ce champ est donc appelé pointeur de métadonnées. La JVM utilisera fréquemment ce pointeur pour localiser les informations de type situées dans la méthode. zone pendant l’exécution. La taille de ces données sera discutée plus tard
Longueur du tableau : unique aux objets tableau, un type de référence pointant vers le type int, utilisé pour décrire la longueur du tableau, la taille de ces données La même taille que le pointeur de métadonnées, dit également plus tard
données d'instance : les données d'instance sont Les huit types de données de base sont byte, short, int, long, float, double, char et boolean (les types d'objets sont également composés de ces huit types de données de base. Combien d'octets occupe chaque type de données). n'est pas répertorié un par un
Padding : variable, L'alignement de HotSpot est un alignement sur 8 octets, c'est-à-dire qu'un objet doit être un multiple entier de 8 octets , donc si la dernière taille de données est de 17, remplissez-la avec 7, et si la taille de données précédente est de 18, remplissez-la avec 6, et ainsi de suite
Parlons enfin de la taille du pointeur de métadonnées. Le pointeur de métadonnées est un type de référence, donc normalement le pointeur de métadonnées machine 64 bits doit être de 8 octets et le pointeur de métadonnées machine 32 bits doit être de 4 octets, mais il existe une optimisation dans HotSpot qui compresse le pointeur de type de métadonnées Storage. , utilisez les paramètres JVM :
-XX:+UseCompressedOops pour activer la compression
- XX:-UseCompressedOops désactive la compression
HotSpot utilise par défaut la première option, ce qui signifie activer la compression du pointeur de métadonnées. Lorsque la compression est activée, le pointeur de métadonnées est activé. une machine 64 bits occupera 4 octets. En d'autres termes, Lorsque la compression est activée, la référence sur la machine 64 bits occupera 4 octets, sinon ce sera les 8 octets normaux .
Calcul de la taille de la mémoire des objets Java
Avec la base théorique ci-dessus, nous vous peut analyser les résultats d'exécution de la classe JVMSizeofTest et pourquoi la taille du même objet est différente après l'ajout du paramètre "-XX:-UseCompressedOops".
Le premier est la taille de l'objet :
Lorsque la compression du pointeur est activée, 8 octets marquent le mot + 4 mots Pointeur de métadonnées de section = 12 octets, puisque 12 octets n'est pas un multiple de 8, donc 4 octets sont remplis, et l'objet Objet occupe 16 octets de mémoire
Fermer Lorsque les pointeurs sont compressés, Mark Word de 8 octets + pointeur de métadonnées de 8 octets = 16 octets Puisque 16 octets sont exactement un multiple de 8, il n'est pas nécessaire de remplir les octets. L'objet Object occupe 16 octets de mémoire.
Puis la taille du caractère 'a' :
Lorsque la compression du pointeur est activé, Mark Word de 8 octets + pointeur de métadonnées de 4 octets + 1 octet de caractère = 13 octets, puisque 13 octets ne sont pas un multiple de 8, donc 3 octets sont complétés, le caractère 'a' occupe 16 octets de mémoire
Lorsque la compression du pointeur est désactivée, 8 octets Mark Word + 8 octets de pointeur de métadonnées + 1 octet de caractère = 17 octets, puisque 17 octets n'est pas un multiple de 8, il est complété par 7 octets, le caractère 'a' occupe 24 octets de mémoire
Puis la taille de l'entier 1 :
Lorsque la compression du pointeur est activée, Mark Word de 8 octets + pointeur de métadonnées de 4 octets + entier de 4 octets = 16 octets Puisque 16 octets sont exactement un multiple de 8, il n'est pas nécessaire de remplir les octets. , le type entier 1 occupe 16 octets de mémoire
Lorsque la compression du pointeur est désactivée, Mark Word de 8 octets + pointeur de métadonnées de 8 octets + 4 octets. int = 20 octets Puisque 20 octets est exactement un multiple de 8, il est complété par 4 octets. L'entier 1 occupe 24 octets de mémoire
suivi de. la chaîne La taille de "aaaaa", tous les champs statiques n'ont pas besoin d'être contrôlés, seuls les champs d'instance sont ciblés. Les champs d'instance dans l'objet String incluent "char value[]" et "int hash", cela peut être. vu de ceci :
Lorsque la compression du pointeur est activée, Mark Word de 8 octets + pointeur de métadonnées de 4 octets + référence de 4 octets + entier de 4 octets = 20 octets. Puisque 20 octets n'est pas un multiple de 8, donc Remplissage de 4 octets, la chaîne "aaaaa" occupe 24 octets de mémoire
Lors de la compression du pointeur. est désactivé, Mark Word de 8 octets + pointeur de métadonnées de 8 octets + référence de 8 octets + 4 octets int = 28 octets, puisque 28 octets n'est pas un multiple de 8, donc 4 octets sont complétés, la chaîne "aaaaa" occupe 32 octets de mémoire
Le dernier est la taille du tableau de caractères de longueur 1 :
Lorsque la compression du pointeur est activée, Mark Word de 8 octets + pointeur de métadonnées de 4 octets + référence de taille de tableau de 4 octets + caractère de 1 octet = 17 octets Puisque 17 octets ne sont pas un multiple de 8, 7 octets sont complétés. . Un tableau de caractères de longueur 1 occupe 24 mots Section Memory
Lorsque la compression du pointeur est désactivée, 8 octets de Mark Word + 8 octets de pointeur de métadonnées +. 8 octets de référence de taille de tableau + 1 mot Section char = 25 octets Puisque 25 octets n'est pas un multiple de 8, il est rempli de 7 octets. Le tableau de caractères de longueur 1 occupe 32 octets de mémoire
<.>Mark Word
Mark Word a déjà été vu, c'est une partie très importante de l'en-tête de l'objet Java. Mark Word stocke les données en cours d'exécution de l'objet lui-même, telles que le code de hachage (HashCode), l'âge de génération GC, l'identification de l'état du verrou, les verrous détenus par les threads, l'ID de thread biaisé, l'horodatage biaisé, etc.
Cependant, comme l'objet doit stocker beaucoup de données d'exécution, il dépasse en fait la limite que les structures Bitmap 32 bits et 64 bits peuvent enregistrer. Cependant, l'en-tête de l'objet. sont des données définies avec l'objet lui-même. Quel que soit le coût de stockage supplémentaire, compte tenu de l'efficacité spatiale de la machine virtuelle, Mark Word est conçu comme une structure de données non fixe afin de stocker autant d’informations que possible dans un très petit espace. Par exemple, lorsque l'objet dans la machine virtuelle HotSpot 32 bits n'est pas verrouillé, 25 bits dans l'espace 32 bits de Mark Word sont utilisés pour stocker le code de hachage de l'objet (HashCode), 4 bits sont utilisés pour stocker l'âge de génération de l'objet. , et 2 bits sont utilisés pour stocker l'âge de génération de l'objet, le bit d'identification du verrou de stockage, 1 bit fixe 0. Le contenu de stockage des objets dans d'autres états (verrouillage léger, verrouillage lourd, marque GC, biaisable) est comme indiqué ci-dessous :
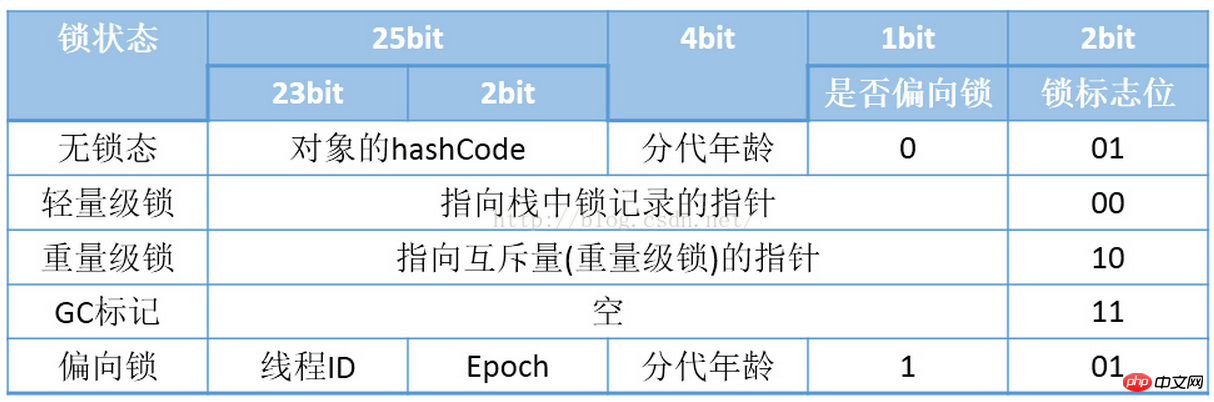
Ce qui nécessite une attention particulière ici, c'est l'état de verrouillage. L'état de verrouillage et les modifications de l'état de verrouillage seront étudiés plus tard.
Mise à niveau du verrou
Comme le montre l'image ci-dessus, il y a quatre verrous : Aucun état de verrouillage, verrous biaisés, verrous légers et verrous lourds. Les verrous biaisés et les verrous légers ont été introduits à partir du JDK 1.6 pour réduire la consommation de performances causée par l'acquisition et la libération des verrous.
Le statut des quatre verrous augmentera progressivement avec la concurrence. Les verrous peuvent être améliorés mais ne peuvent pas être dégradés, ce qui signifie que les verrous biaisés peuvent être améliorés en verrous légers mais que les verrous légers ne peuvent pas être déclassés. . Pour biaiser le verrou, le but est d'améliorer l'efficacité de l'acquisition et du déverrouillage. Utilisez un diagramme pour représenter cette relation :

Verrouillage des biais
Auteur HotSpot réussi Des recherches antérieures ont montré que dans la plupart des cas, non seulement il n'y a pas de concurrence multithread pour les verrous, mais qu'ils sont également toujours acquis plusieurs fois par le même thread. Afin de réduire le code permettant aux threads d'acquérir des verrous, des verrous biaisés sont introduits. Le processus d'obtention du verrouillage de biais est :
Accédez à Mark Word pour voir si l'indicateur de verrouillage de biais est défini sur 1 et si le bit d'indicateur est 01-- --Confirmez qu'il s'agit d'un état biaisable
S'il s'agit d'un état biaisable, testez si l'identifiant du thread pointe vers le thread actuel, si c'est le cas, exécutez (5) , sinon exécutez (3)
Si l'identifiant du thread ne pointe pas vers le thread actuel, rivalisez pour le verrou via l'opération CAS. Si le concours réussit, définissez l'identifiant du fil dans Mark Word sur l'identifiant du fil actuel, puis exécutez (5) si le concours échoue, exécutez (4)
Si le CAS ne parvient pas à acquérir le verrou biaisé, c'est qu'il y a de la concurrence. Lorsque le point de sécurité global (safepoint) est atteint, le thread qui a obtenu le verrou biaisé est suspendu et le verrou biaisé est mis à niveau vers un verrou léger (car le verrou biaisé ne suppose aucune concurrence, mais il y a de la concurrence ici, et le verrou biaisé a besoin à mettre à niveau), puis Le fil bloqué au point sûr continue d'exécuter le code de synchronisation
exécuter le code de synchronisation
Dès qu'il est acquis, il est libéré. Le point de libération du verrou biaisé se situe à l'étape (4) ci-dessus Uniquement lorsque d'autres threads tentent de rivaliser. le verrou biaisé, le fil tenant le verrou biaisé libérera le verrou, le fil ne libérera pas activement le verrou biaisé. Le processus de libération du verrou biaisé est :
Besoin d'attendre le point de sécurité global (aucun bytecode n'est en cours d'exécution à ce stade)
Il mettra d'abord en pause le fil qui possède le verrou de biais et déterminera si l'objet de verrouillage est verrouillé
Le verrou de polarisation est libéré Puis restaurez l'état déverrouillé (le bit d'identification est 01) ou léger (le bit d'identification est 00)
Serrure légère
Le processus de verrouillage de la serrure légère est :
Entrez le code Lors de la synchronisation d'un bloc, si l'état de verrouillage de l'objet de synchronisation est sans verrouillage, la JVM créera d'abord un espace appelé Lock Record dans le cadre de pile du thread actuel pour stocker une copie du mot de marque actuel de l'objet de verrouillage. Officiellement appelé Displaced Mark Word, l'état de la pile de threads et de l'en-tête de l'objet à ce moment est tel qu'indiqué dans la figure 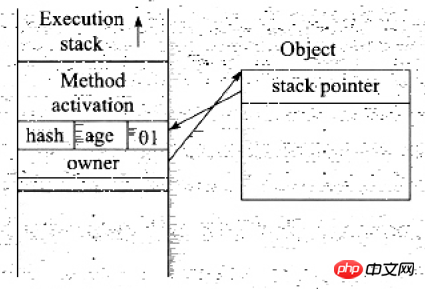
Copier le mot Mark dans le en-tête d'objet vers l'enregistrement de verrouillage
Une fois la copie réussie, la JVM utilisera l'opération CAS pour essayer de mettre à jour le mot de marque de l'objet vers un pointeur vers l'enregistrement de verrouillage et stockez-le dans l'enregistrement de verrouillage. Le pointeur du propriétaire pointe vers le mot de marque d'objet. Si la mise à jour réussit, exécutez l'étape (4), sinon exécutez l'étape (5)
.Si l'action de mise à jour réussit, alors le thread actuel possède le verrou de l'objet et l'indicateur de verrouillage de l'objet Mark Word est défini sur 00, ce qui signifie que l'objet est dans un état de verrouillage léger À ce stade, l'état de la pile de threads et de l'en-tête de l'objet est tel qu'indiqué dans la figure 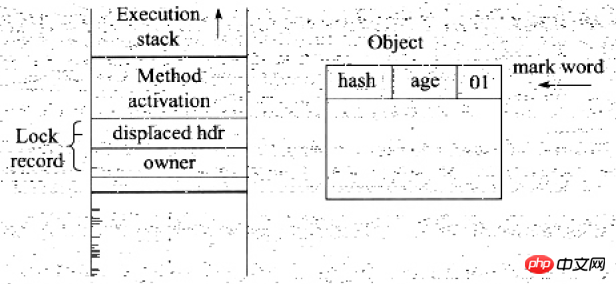
Si l'action de mise à jour échoue, la JVM vérifiera d'abord si le Mark Word de l'objet pointe vers le cadre de pile du thread actuel. Si tel est le cas, cela signifie que le thread actuel possède déjà le verrou de cet objet, vous pouvez alors entrer directement dans le bloc synchronisé pour continuer. exécution. Sinon, cela signifie que plusieurs threads sont en compétition pour le verrou, et le verrou léger se transformera en un verrou lourd, et la valeur d'état de l'identifiant du verrou deviendra 10. Ce qui est stocké dans le Mark Word est le pointeur vers le verrou lourd, et les threads en attente du verrou entreront également dans un état de blocage plus tard. Le thread actuel essaie d'utiliser spin pour acquérir le verrou. Spin consiste à empêcher le thread de se bloquer et utilise une boucle pour acquérir le verrou
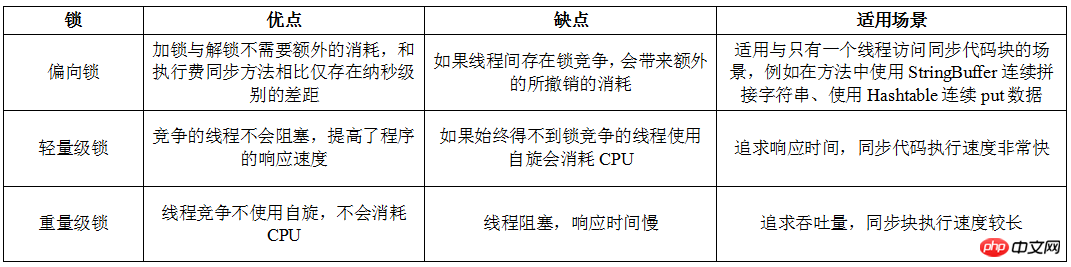
Comparaison des serrures biaisées, des serrures légères et des serrures lourdes
Ce qui suit utilise un tableau pour comparer les serrures biaisées et les serrures légères. Serrures de classe et poids lourd locks, je les ai vus en ligne et je les ai trouvés très bien écrits. Pour approfondir ma mémoire, je les ai retapés à la main :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



