

Analyse approfondie du code source Buffer de Java

Environnement natif : Linux 4.4.0-21-generic #37-Ubuntu SMP Mon Apr 18 18:33:37 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
Buffer
Le diagramme de classes de Buffer est le suivant :
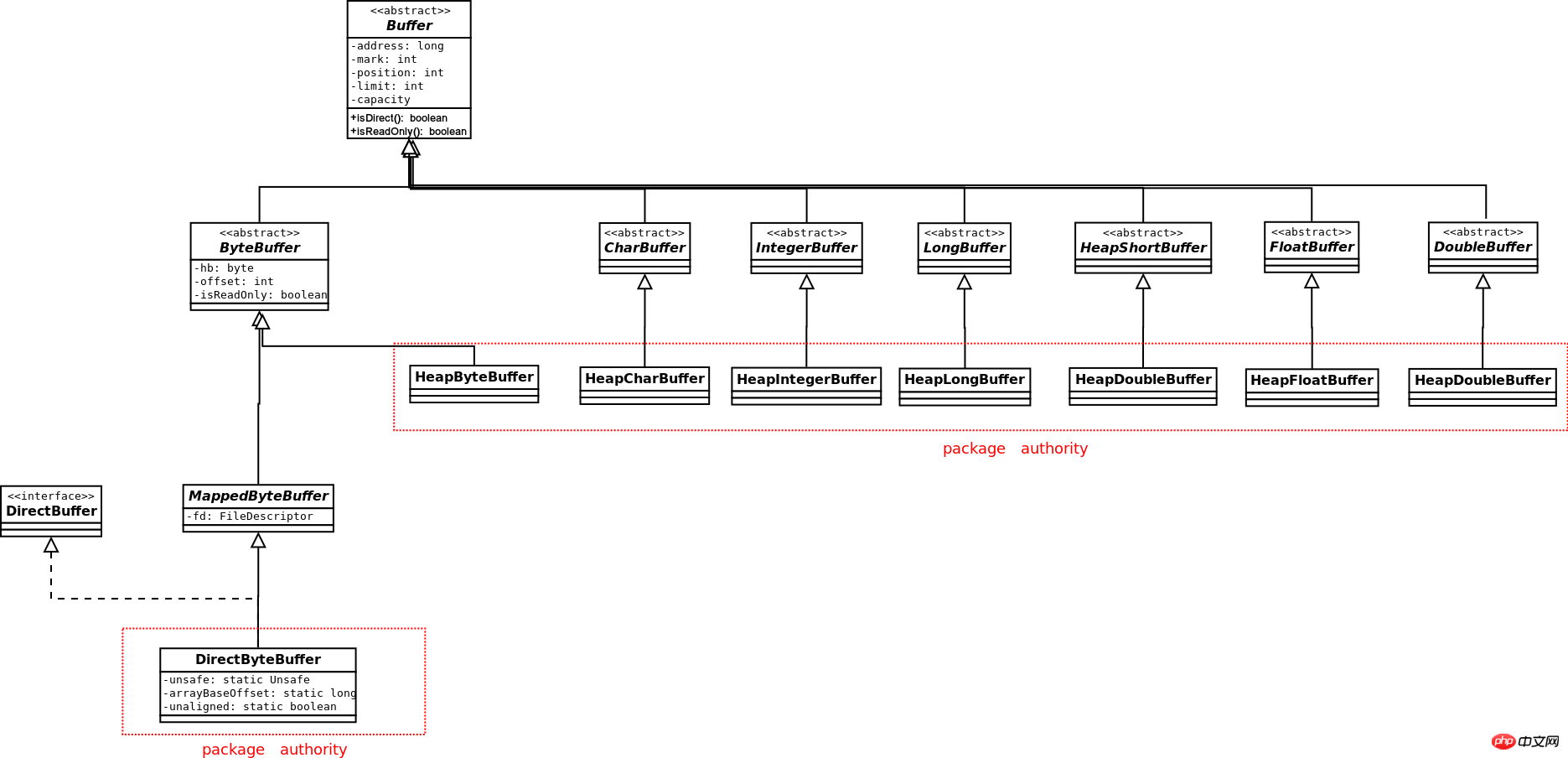
Dans En plus du booléen, d'autres types de données de base ont des tampons correspondants, mais seul ByteBuffer peut interagir avec Channel. Seul ByteBuffer peut générer un tampon direct Les tampons d'autres types de données ne peuvent générer que des tampons de type Heap. ByteBuffer peut générer des tampons de vue d'autres types de données. Si le ByteBuffer lui-même est Direct, alors les tampons de vue générés sont également Direct .
L'essence des tampons de type Direct et Heap
Le premier choix est de parler de la façon dont la JVM effectue les opérations d'E/S.
JVM doit effectuer les opérations d'E/S via des appels du système d'exploitation. Par exemple, elle peut terminer la lecture de fichiers via des appels système de lecture. Le prototype de read est : ssize_t read(int fd,void *buf,size_t nbytes), similaire aux autres appels système IO, nécessite généralement un tampon comme l'un des paramètres, et le tampon doit être continu.
Buffer est divisé en deux catégories : Direct et Heap. Ces deux types de tampons sont expliqués ci-dessous.
Tas
Type de tas Buffer existe sur le tas JVM Le recyclage et le tri de cette partie de la mémoire sont les mêmes que pour les objets ordinaires. Les objets Buffer de type Heap contiennent tous un attribut de tableau correspondant à un type de données de base (par exemple : final **[] hb), et le tableau est le tampon sous-jacent du Buffer de type Heap.
Cependant, le Buffer de type Heap ne peut pas être utilisé comme paramètre de tampon pour les appels système directs, principalement pour les deux raisons suivantes.
JVM peut déplacer le tampon (copier-organiser) pendant le GC, et l'adresse du tampon n'est pas fixe.
Lors des appels système, le tampon doit être continu, mais le tableau peut ne pas être continu (l'implémentation JVM ne nécessite pas de continu).
Ainsi, lors de l'utilisation d'un tampon de type Heap pour les E/S, la JVM doit générer un tampon de type Direct temporaire, puis copier les données, puis utiliser le tampon direct temporaire comme paramètre pour créer un appel du système d’exploitation. Cela se traduit par une très faible efficacité, principalement pour deux raisons :
Les données doivent être copiées du tampon de type Heap vers le tampon direct créé temporairement.
peut générer un grand nombre d'objets Buffer, augmentant ainsi la fréquence du GC. Ainsi lors des opérations IO, vous pouvez optimiser en réutilisant le Buffer.
Direct
Le tampon de type direct n'existe pas sur le tas, mais est une mémoire continue allouée directement par la JVM via malloc. Mémoire directe, la JVM utilise la mémoire directe comme tampon lors des appels système IO. -XX:MaxDirectMemorySize, grâce à cette configuration, vous pouvez définir la taille maximale de la mémoire directe autorisée à être allouée (la mémoire allouée par MappedByteBuffer n'est pas affectée par cette configuration).
Le recyclage de la mémoire directe est différent du recyclage de la mémoire tas Si la mémoire directe n'est pas utilisée correctement, il est facile de provoquer une erreur OutOfMemoryError. JAVA ne fournit pas de méthode explicite pour libérer activement de la mémoire directe. La classe sun.misc.Unsafe peut effectuer des opérations de mémoire directe sous-jacentes, et la mémoire directe peut être activement libérée et gérée via cette classe. De même, la mémoire directe doit également être réutilisée pour améliorer l'efficacité.
Relation entre MappedByteBuffer et DirectByteBuffer
C'est un peu à l'envers : MappedByteBuffer devrait être une sous-classe de DirectByteBuffer, mais pour garder la spécification claire et simple, et à des fins d'optimisation, il est plus facile de procéder dans l'autre sens. Cela fonctionne car DirectByteBuffer est une classe privée du package.(Ce paragraphe est tiré du code source de MappedByteBuffer)
En fait, MappedByteBuffer est un tampon mappé (regardez vous-même la mémoire virtuelle), mais DirectByteBuffer indique seulement que cette partie de la mémoire est un tampon continu alloué par la JVM dans la zone mémoire directe, et n'est pas nécessairement mappée. En d'autres termes, MappedByteBuffer devrait être une sous-classe de DirectByteBuffer, mais pour des raisons de commodité et d'optimisation, MappedByteBuffer est utilisée comme classe parent de DirectByteBuffer. De plus, bien que MappedByteBuffer devrait logiquement être une sous-classe de DirectByteBuffer et que le GC mémoire de MappedByteBuffer soit similaire au GC de la mémoire directe (différent du GC du tas), la taille du MappedByteBuffer alloué n'est pas affectée par le -XX:MaxDirectMemorySize paramètre.
MappedByteBuffer encapsule les opérations sur les fichiers mappés en mémoire, ce qui signifie qu'il ne peut effectuer que des opérations d'E/S sur les fichiers. MappedByteBuffer est un tampon de mappage généré sur la base de mmap. Cette partie du tampon est mappée à la page de fichier correspondante et appartient à la mémoire directe en mode utilisateur. Le tampon mappé peut être directement exploité via MappedByteBuffer, et cette partie du tampon est mappée. la page du fichier. Sur le système, le système d'exploitation termine l'écriture et l'écriture des fichiers en appelant et en sortant des pages mémoire correspondantes.
MappedByteBuffer
Obtenez MappedByteBuffer via FileChannel.map(MapMode mode,long position, long size) Le processus de génération de MappedByteBuffer est expliqué ci-dessous avec le code source.
FileChannel.map code source :
public MappedByteBuffer map(MapMode mode, long position, long size)throws IOException
{ensureOpen();if (position < 0L)throw new IllegalArgumentException("Negative position");if (size < 0L)throw new IllegalArgumentException("Negative size");if (position + size < 0)throw new IllegalArgumentException("Position + size overflow");//最大2Gif (size > Integer.MAX_VALUE)throw new IllegalArgumentException("Size exceeds Integer.MAX_VALUE");int imode = -1;if (mode == MapMode.READ_ONLY)
imode = MAP_RO;else if (mode == MapMode.READ_WRITE)
imode = MAP_RW;else if (mode == MapMode.PRIVATE)
imode = MAP_PV;assert (imode >= 0);if ((mode != MapMode.READ_ONLY) && !writable)throw new NonWritableChannelException();if (!readable)throw new NonReadableChannelException();long addr = -1;int ti = -1;try {begin();
ti = threads.add();if (!isOpen())return null;//size()返回实际的文件大小//如果实际文件大小不符合,则增大文件的大小,文件的大小被改变,文件增大的部分默认设置为0。if (size() < position + size) { // Extend file sizeif (!writable) {throw new IOException("Channel not open for writing " +"- cannot extend file to required size");
}int rv;do { //增大文件的大小rv = nd.truncate(fd, position + size);
} while ((rv == IOStatus.INTERRUPTED) && isOpen());
}//如果要求映射的文件大小为0,则不调用操作系统的mmap调用,只是生成一个空间容量为0的DirectByteBuffer//并返回if (size == 0) {
addr = 0;// a valid file descriptor is not requiredFileDescriptor dummy = new FileDescriptor();if ((!writable) || (imode == MAP_RO))return Util.newMappedByteBufferR(0, 0, dummy, null);elsereturn Util.newMappedByteBuffer(0, 0, dummy, null);
}//allocationGranularity的大小在我的系统上是4K//页对齐,pagePosition为第多少页int pagePosition = (int)(position % allocationGranularity);//从页的最开始映射long mapPosition = position - pagePosition;//因为从页的最开始映射,增大映射空间long mapSize = size + pagePosition;try {// If no exception was thrown from map0, the address is valid//native方法,源代码在openjdk/jdk/src/solaris/native/sun/nio/ch/FileChannelImpl.c,//参见下面的说明addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {// An OutOfMemoryError may indicate that we've exhausted memory// so force gc and re-attempt mapSystem.gc();try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {// After a second OOME, failthrow new IOException("Map failed", y);
}
}// On Windows, and potentially other platforms, we need an open// file descriptor for some mapping operations.FileDescriptor mfd;try {
mfd = nd.duplicateForMapping(fd);
} catch (IOException ioe) {unmap0(addr, mapSize);throw ioe;
}assert (IOStatus.checkAll(addr));assert (addr % allocationGranularity == 0);int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);if ((!writable) || (imode == MAP_RO)) {return Util.newMappedByteBufferR(isize,
addr + pagePosition,
mfd,
um);
} else {return Util.newMappedByteBuffer(isize,
addr + pagePosition,
mfd,
um);
}
} finally {
threads.remove(ti);end(IOStatus.checkAll(addr));
}
}map0的源码实现:
JNIEXPORT jlong JNICALL
Java_sun_nio_ch_FileChannelImpl_map0(JNIEnv *env, jobject this,
jint prot, jlong off, jlong len)
{void *mapAddress = 0;
jobject fdo = (*env)->GetObjectField(env, this, chan_fd);//linux系统调用是通过整型的文件id引用文件的,这里得到文件idjint fd = fdval(env, fdo);int protections = 0;int flags = 0;if (prot == sun_nio_ch_FileChannelImpl_MAP_RO) {
protections = PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_RW) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_PV) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_PRIVATE;
}//这里就是操作系统调用了,mmap64是宏定义,实际最后调用的是mmapmapAddress = mmap64(0, /* Let OS decide location */len, /* Number of bytes to map */protections, /* File permissions */flags, /* Changes are shared */fd, /* File descriptor of mapped file */off); /* Offset into file */if (mapAddress == MAP_FAILED) {if (errno == ENOMEM) {//如果没有映射成功,直接抛出OutOfMemoryErrorJNU_ThrowOutOfMemoryError(env, "Map failed");return IOS_THROWN;
}return handle(env, -1, "Map failed");
}return ((jlong) (unsigned long) mapAddress);
}虽然FileChannel.map()的zise参数是long,但是size的大小最大为Integer.MAX_VALUE,也就是最大只能映射最大2G大小的空间。实际上操作系统提供的MMAP可以分配更大的空间,但是JAVA限制在2G,ByteBuffer等Buffer也最大只能分配2G大小的缓冲区。
MappedByteBuffer是通过mmap产生得到的缓冲区,这部分缓冲区是由操作系统直接创建和管理的,最后JVM通过unmmap让操作系统直接释放这部分内存。
Haep****Buffer
下面以ByteBuffer为例,说明Heap类型Buffer的细节。
该类型的Buffer可以通过下面方式产生:
ByteBuffer.allocate(int capacity)ByteBuffer.wrap(byte[] array)
使用传入的数组作为底层缓冲区,变更数组会影响缓冲区,变更缓冲区也会影响数组。ByteBuffer.wrap(byte[] array,int offset, int length)
使用传入的数组的一部分作为底层缓冲区,变更数组的对应部分会影响缓冲区,变更缓冲区也会影响数组。
DirectByteBuffer
DirectByteBuffer只能通过ByteBuffer.allocateDirect(int capacity) 产生。ByteBuffer.allocateDirect()源码如下:
public static ByteBuffer allocateDirect(int capacity) {return new DirectByteBuffer(capacity);
}DirectByteBuffer()源码如下:
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
//直接内存是否要页对齐,我本机测试的不用
boolean pa = VM.isDirectMemoryPageAligned();
//页的大小,本机测试的是4K
int ps = Bits.pageSize();
//如果页对齐,则size的大小是ps+cap,ps是一页,cap也是从新的一页开始,也就是页对齐了
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//JVM维护所有直接内存的大小,如果已分配的直接内存加上本次要分配的大小超过允许分配的直接内存的最大值会
//引起GC,否则允许分配并把已分配的直接内存总量加上本次分配的大小。如果GC之后,还是超过所允许的最大值,
//则throw new OutOfMemoryError("Direct buffer memory");
Bits.reserveMemory(size, cap);
long base = 0;
try {
//是吧,unsafe可以直接操作底层内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {、
//没有分配成功,把刚刚加上的已分配的直接内存的大小减去。
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}unsafe.allocateMemory()的源码在openjdk/src/openjdk/hotspot/src/share/vm/prims/unsafe.cpp中。具体的源码如下:
UNSAFE_ENTRY(jlong, Unsafe_AllocateMemory(JNIEnv *env, jobject unsafe, jlong size))
UnsafeWrapper("Unsafe_AllocateMemory");
size_t sz = (size_t)size; if (sz != (julong)size || size < 0) {
THROW_0(vmSymbols::java_lang_IllegalArgumentException());
} if (sz == 0) {return 0;
}
sz = round_to(sz, HeapWordSize); //最后调用的是 u_char* ptr = (u_char*)::malloc(size + space_before + space_after),也就是malloc。
void* x = os::malloc(sz, mtInternal); if (x == NULL) {
THROW_0(vmSymbols::java_lang_OutOfMemoryError());
} //Copy::fill_to_words((HeapWord*)x, sz / HeapWordSize);
return addr_to_java(x);
UNSAFE_ENDJVM通过malloc分配得到连续的缓冲区,这部分缓冲区可以直接作为缓冲区参数进行操作系统调用。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La pratique d'application de Python dans la protection du code source des logiciels
Jun 29, 2023 am 11:20 AM
La pratique d'application de Python dans la protection du code source des logiciels
Jun 29, 2023 am 11:20 AM
En tant que langage de programmation de haut niveau, le langage Python est facile à apprendre, à lire et à écrire et a été largement utilisé dans le domaine du développement de logiciels. Cependant, en raison de la nature open source de Python, le code source est facilement accessible aux autres, ce qui pose certains défis en matière de protection du code source des logiciels. Par conséquent, dans les applications pratiques, nous devons souvent adopter certaines méthodes pour protéger le code source Python et assurer sa sécurité. Dans le domaine de la protection du code source des logiciels, il existe une variété de pratiques d'application parmi lesquelles Python peut choisir. Voici quelques exemples courants
 Comment afficher le code source du code PHP dans le navigateur sans être interprété et exécuté ?
Mar 11, 2024 am 10:54 AM
Comment afficher le code source du code PHP dans le navigateur sans être interprété et exécuté ?
Mar 11, 2024 am 10:54 AM
Comment afficher le code source du code PHP dans le navigateur sans être interprété et exécuté ? PHP est un langage de script côté serveur couramment utilisé pour développer des pages Web dynamiques. Lorsqu'un fichier PHP est demandé sur le serveur, le serveur interprète et exécute le code PHP qu'il contient et envoie le contenu HTML final au navigateur pour affichage. Cependant, nous souhaitons parfois afficher le code source du fichier PHP directement dans le navigateur au lieu de l'exécuter. Cet article expliquera comment afficher le code source du code PHP dans le navigateur sans être interprété et exécuté. En PHP, vous pouvez utiliser
 Analyse approfondie : quel est le véritable niveau de performance du langage Go ?
Jan 30, 2024 am 10:02 AM
Analyse approfondie : quel est le véritable niveau de performance du langage Go ?
Jan 30, 2024 am 10:02 AM
Analyse approfondie : quelles sont les performances du langage Go ? Introduction : Dans le monde actuel du développement de logiciels, les performances sont un facteur crucial. Pour les développeurs, choisir un langage de programmation offrant d’excellentes performances peut améliorer l’efficacité et la qualité des applications logicielles. En tant que langage de programmation moderne, le langage Go est considéré par de nombreux développeurs comme un langage performant. Cet article approfondira les caractéristiques de performances du langage Go et l'analysera à travers des exemples de code spécifiques. 1. Capacités de concurrence : en tant que langage de programmation basé sur la concurrence, le langage Go possède d'excellentes capacités de concurrence.
 Site Web pour consulter le code source en ligne
Jan 10, 2024 pm 03:31 PM
Site Web pour consulter le code source en ligne
Jan 10, 2024 pm 03:31 PM
Vous pouvez utiliser les outils de développement du navigateur pour afficher le code source du site Web. Dans le navigateur Google Chrome : 1. Ouvrez le navigateur Chrome et visitez le site Web sur lequel vous souhaitez afficher le code source. 2. Cliquez avec le bouton droit n'importe où sur le Web ; page et sélectionnez « Inspecter » ou appuyez sur la touche de raccourci Ctrl + Maj + I pour ouvrir les outils de développement ; 3. Dans la barre de menu supérieure des outils de développement, sélectionnez l'onglet « Éléments » 4. Regardez simplement le code HTML et CSS ; du site Internet.
 Comment afficher le code source de Tomcat dans Idea
Jan 25, 2024 pm 02:01 PM
Comment afficher le code source de Tomcat dans Idea
Jan 25, 2024 pm 02:01 PM
Étapes pour afficher le code source de Tomcat dans IDEA : 1. Téléchargez le code source de Tomcat ; 2. Importez le code source de Tomcat dans IDEA ; 3. Visualisez le code source de Tomcat ; 4. Comprendre le principe de fonctionnement de Tomcat ; mise à jour ; 7. Utiliser des outils et des plug-ins ; 8. Participer à la communauté et contribuer. Introduction détaillée : 1. Téléchargez le code source de Tomcat Vous pouvez télécharger le package de code source depuis le site officiel d'Apache Tomcat. Généralement, ces packages de code source sont au format ZIP ou TAR, etc.
 Vue peut-elle afficher le code source ?
Jan 05, 2023 pm 03:17 PM
Vue peut-elle afficher le code source ?
Jan 05, 2023 pm 03:17 PM
Vue peut afficher le code source. La méthode de visualisation du code source dans Vue est la suivante : 1. Obtenez vue via "git clone https://github.com/vuejs/vue.git" 2. Installez les dépendances via "npm i" ; ; 3. Via " npm i -g rollup" pour installer le rollup ; 4. Modifiez le script de développement 5. Débogez le code source.
 Un guide complet pour apprendre et appliquer le code source du framework Golang
Jun 01, 2024 pm 10:31 PM
Un guide complet pour apprendre et appliquer le code source du framework Golang
Jun 01, 2024 pm 10:31 PM
En comprenant le code source du framework Golang, les développeurs peuvent maîtriser l'essence du langage et étendre les fonctions du framework. Tout d’abord, récupérez le code source et familiarisez-vous avec sa structure de répertoires. Deuxièmement, lisez le code, suivez le flux d'exécution et comprenez les dépendances. Des exemples pratiques montrent comment appliquer ces connaissances : créer un middleware personnalisé et étendre le système de routage. Les meilleures pratiques incluent l’apprentissage étape par étape, l’évitement du copier-coller inconsidéré, l’utilisation d’outils et la référence aux ressources en ligne.
 Erreur de code source PHP : résolution du problème d'erreur d'index
Mar 10, 2024 am 11:12 AM
Erreur de code source PHP : résolution du problème d'erreur d'index
Mar 10, 2024 am 11:12 AM
Erreur de code source PHP : pour résoudre le problème d'erreur d'index, des exemples de code spécifiques sont nécessaires. Avec le développement rapide d'Internet, les développeurs rencontrent souvent divers problèmes lors de l'écriture de sites Web et d'applications. Parmi eux, PHP est un langage de script côté serveur populaire, et ses erreurs de code source sont l'un des problèmes que les développeurs rencontrent souvent. Parfois, lorsque nous essayons d'ouvrir la page d'index d'un site Web, divers messages d'erreur apparaissent, tels que "InternalServerError", "Unde
