

Présentation du framework Scrapy Crawler
Méthode d'installation pip install scrapy peut être installé. J'utilise la commande anaconda pour conda installer scrapy.

1 Engine reçoit la demande d'exploration (Request) de Spider<br>2Engine va Le la demande d'exploration est transmise au planificateur pour la planification
3 Le moteur obtient la prochaine demande d'exploration du planificateur<br>4 Le moteur envoie la demande d'exploration au téléchargeur via le middleware<br>5 Crawl après la page Web , le téléchargeur forme une réponse et l'envoie au moteur via le middleware<br>6. Le moteur envoie la réponse reçue au Spider via le middleware pour traitement. Le moteur transmet la demande d'exploration au planificateur pour la planification
<.> 7 Une fois que Spider a traité la réponse, il génère un élément récupéréet de nouvelles requêtes d'exploration (requêtes) au moteur <br> 8 Le moteur envoie l'élément récupéré au pipeline d'articles (sortie du framework) <br> 9 Le moteur La demande d'exploration est envoyé au planificateur<br>
Le moteur contrôle le flux de données de chaque module et obtient en continu les requêtes d'exploration du planificateurjusqu'à ce que la requête soit vide<br>Entrée de cadre : demande d'exploration initiale de Spider<br>Exportation de cadre : Pipeline d'articles<br>
Moteur Non modification de l'utilisateur requise<br>Téléchargeur<br><br>Télécharger des pages Web en fonction des demandes
Aucune modification de l'utilisateur requisePlanificateur<br><br>Planification et gestion de toutes les demandes d'exploration
Aucune modification utilisateur requiseMiddleware de téléchargement<br><br>Objectif : Implémenter un contrôle configurable par l'utilisateur entre le moteur, le planificateur et le téléchargeur
Fonction : Modifier, supprimer, ajouter des demandes ou des réponsesLes utilisateurs peuvent écrire le code de configuration <br><br>Spider<br><br>(1) Analyser la réponse renvoyée par le téléchargeur
(2) Générer un élément récupéré(3) Générer des requêtes d'exploration supplémentaires (Demande) obliger les utilisateurs à écrire du code de configuration <br><br>Pipelines d'articles<br><br>(1) Traiter les éléments analysés générés par Spider dans de manière pipeline
( 2) Il se compose d'un ensemble de séquences d'opérations, similaires à un pipeline. Chaque opérationest un type de pipeline d'éléments (3) Les opérations possibles incluent : le nettoyage, la vérification et la vérification de la duplication de. les données HTML de dans les éléments analysés, le stockage des données dans la base de données <br> nécessite que l'utilisateur écrive le code de configuration <br> <br> Après avoir compris les concepts de base, commençons à écrire le premier robot Scrapy. <br><br>Tout d'abord, créez un nouveau projet de robot scrapy startproject xxx (nom du projet) <br>
Ce robot explorera simplement le titre et l'auteur d'un nouveau site Web.
Nous avons maintenant créé le livre de projet du robot et modifions maintenant sa configuration 
Avant de modifier ceux-ci
nous créons maintenant un démarrage. py dans le répertoire book de premier niveau pour utiliser le robot d'exploration Scrapy dans l'opération Surface de l'EDI 
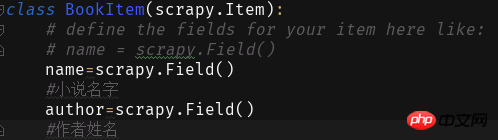
Ensuite, nous remplissons les champs dans les éléments :
Créons ensuite le livre du programme principal du robot dans Spider py.
Le site Web que nous souhaitons explorer est
En cliquant sur les différents types de romans sur le site Web, vous constaterez que l'adresse du site Web est +roman type pinyin.html
Grâce à cela, nous écrivons et lisons le contenu de la page Web
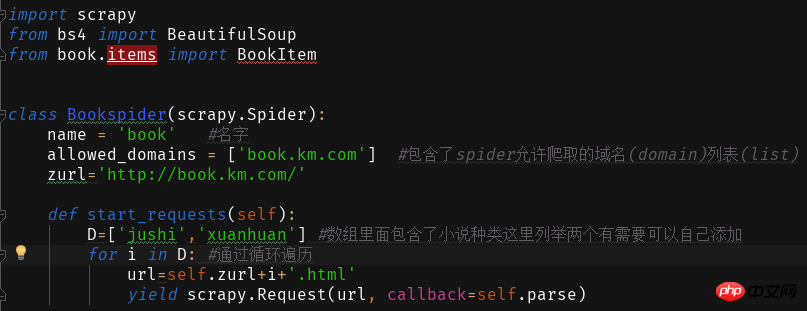
Obtenir ceci Nous utilisons ensuite la fonction d'analyse pour analyser la page Web obtenue et extraire les informations requises.
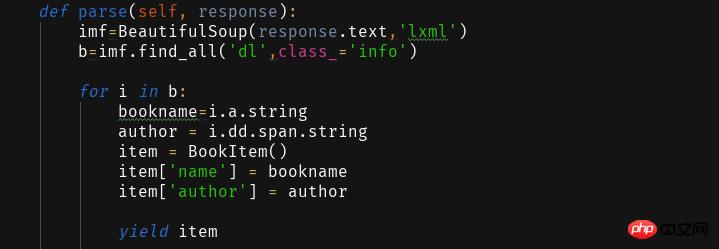
L'analyse de pages Web extrait les données via la bibliothèque BeautifulSoup, qui est omise ici. Analysez 2333 par vous-même~
Après avoir écrit le programme, nous devons modifier Pipelines.py pour stocker les informations analysées
Il existe deux méthodes d'enregistrement fournies ici
1 Enregistrer sous txt Texte
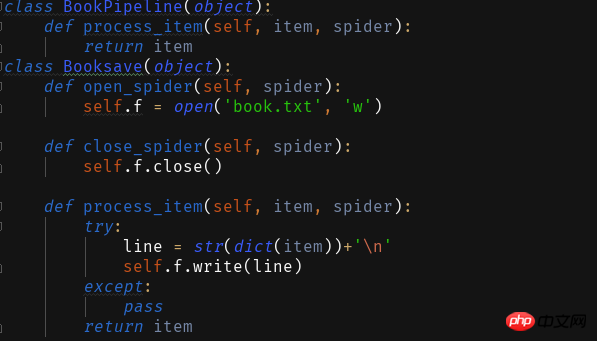
2 Enregistrer dans la base de données
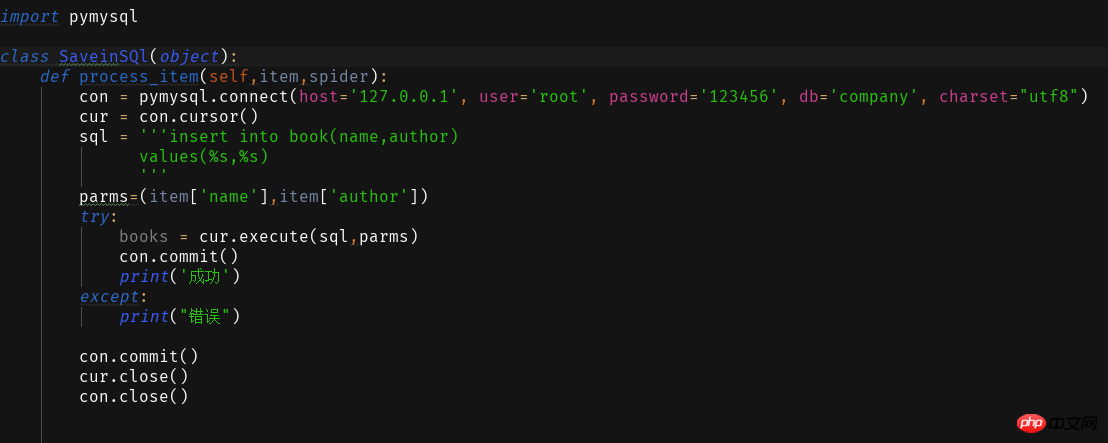
Pour que cela fonctionne avec succès, nous devons également le configurer dans les paramètres. py
<span style="color: #000000">ITEM_PIPELINES = { 'book.pipelines.xxx': 300,}<br>xxx为存储方法的类名,想用什么方法存储就改成那个名字就好运行结果没什么看头就略了<br>第一个爬虫框架就这样啦期末忙没时间继续完善这个爬虫之后有时间将这个爬虫完善成把小说内容等一起爬下来的程序再来分享一波。<br>附一个book的完整代码:<br></span>import scrapyfrom bs4 import BeautifulSoupfrom book.items import BookItemclass Bookspider(scrapy.Spider):
name = 'book' #名字
allowed_domains = ['book.km.com'] #包含了spider允许爬取的域名(domain)列表(list)
zurl=''def start_requests(self):
D=['jushi','xuanhuan'] #数组里面包含了小说种类这里列举两个有需要可以自己添加for i in D: #通过循环遍历
url=self.zurl+i+'.html'yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
imf=BeautifulSoup(response.text,'lxml')
b=imf.find_all('dl',class_='info')for i in b:
bookname=i.a.stringauthor = i.dd.span.stringitem = BookItem()
item['name'] = bookname
item['author'] = authoryield item<br>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



