

Python série 4
Table des matières
Analyse d'algorithme récursif
Analyse du tri des bulles de risque
Analyse du décorateur
1 .Récursion
1. La définition de la récursion
La récursivité, également connue sous le nom de récursivité, en mathématiques et en informatique, fait référence à la méthode d'utilisation de la fonction elle-même dans la définition d'une fonction. Le terme récursivité est également utilisé de manière plus longue pour décrire le processus de répétition de choses de manière auto-similaire.
F0 = 0F1 = 1
2. Le principe de récursion
(1) Exemple :
defth == 5= a1 += defth + 1== recursion(1, 0, 1(ret)
L'image suivante montre le processus d'exécution de la fonction entière. Les rouges représentent l'imbrication couche par couche à l'intérieur, et les vertes représentent la valeur de retour de la fonction renvoyée couche par couche. En fait, la récursivité est ce principe.Après être entré à nouveau dans cette fonction via le flux d'exécution d'une fonction, après avoir renvoyé une valeur via une condition, elle revient couche par couche selon le flux d'exécution à l'instant, et obtient finalement la valeur de retour, mais lors de la récursion Deux points sont à noter : 1. Son état doit être tel que sa récursivité puisse renvoyer une valeur dans une certaine condition, sinon il continuera à récursif jusqu'à épuisement des ressources informatiques (Python a une récursion par défaut Nombre de fois limite) 2. Valeur de retour, la fonction récursive à l'intérieur doit généralement lui donner une certaine valeur de retour, sinon vous n'obtiendrez pas la valeur souhaitée lorsque la dernière récursion sera renvoyée.

冒泡排序算法的运作如下: 1. 比较相邻的元素。如果第一个比第二个大,就交换他们两个。 2. 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。 3. 针对所有的元素重复以上的步骤,除了最后一个。 4. 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较
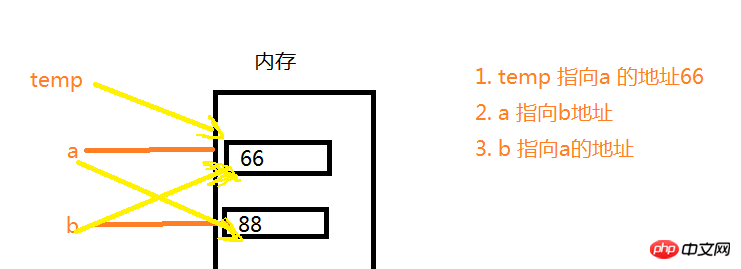
a = 66b = 88temp = a a = b b = temp
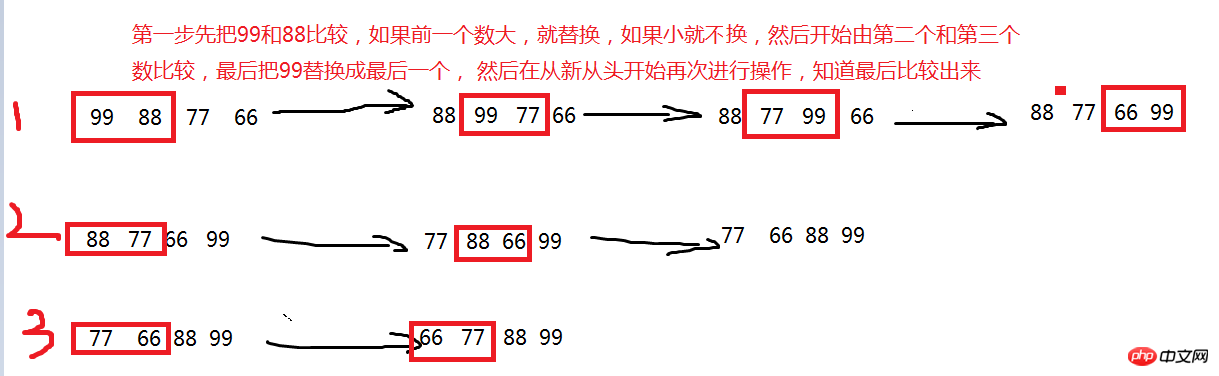
1 # -*- coding:utf-8 -*- 2 # zhou 3 # 2017/6/17 4 list = [0, 88, 99, 33, 22, 11, 1] 5 for j in range(1, len(list)): 6 for i in range(len(list) - j): 7 # 如果第一个数据大, 则交换数据, 否则, 不做改变 8 if list[i] > list[i + 1]: 9 temp = list[i]10 list[i] = list[i + 1]11 list[i + 1] = temp12 print(list)
def test1():print('日本人.')print(id(test1))def test1():print('中国人.')print(id(test1))
test1()
执行结果:890673481656
890673481792中国人. <1>. 装饰器也是一个函数 <2>. 使用装饰器的格式: 在一个函数前面加上:@装饰器的名字 <1>. 把test1函数当做一个变量传入outer中 func = test1 <2>. 把装饰器嵌套的一个函数inner赋值给test1 test1 = inner <3>. 当执行test1函数的时候,就等于执行了inner函数,因此在最后的那个test1()命令其实执行的就是inner,因此先输出(你是哪国人) <4>. 按照执行流执行到func函数的时候,其实执行的就是原来的test1函数,因此接着输出(我是中国人),并把它的返回值返回给了ret <5>. 当原来的test1函数执行完了之后,继续执行inner里面的命令,因此输出了(Oh,hh, I love China.) 由上面的执行流可以看出来,其实装饰器把之前的函数当做参数传递进去,然后创建了另一个函数用来在原来的函数之前或者之后加上所需要的功能。 为了装饰器的高可用,一般都会采用下面的方式,也就是无论所用的函数是多少个参数,这个装饰器都可以使用 Python内部会自动的分配他的参数。 2. 装饰器原理
(1). 装饰器的写法和使用
(2). 装饰器的原理
(3). 装饰器的总结
(=((
3. 带参数的装饰器
# -*- coding:utf-8 -*-# zhou# 2017/6/17def outer(func):def inner(a, *args, **kwargs):print('你是哪国人?')
ret = func(a, *args, **kwargs)print('Oh, hh, I love China.')return inner
@outerdef test1(a, *args, **kwargs):print('我是中国人.')
test1(1) 3. 装饰器的嵌套
<1>. 第一层装饰器的简化(outer装饰器)
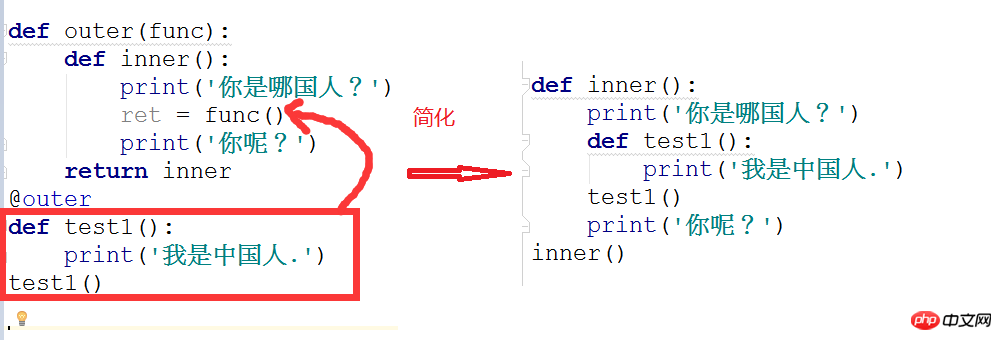
<2>. 第二层装饰器简化(outer0装饰器)

<3>. 装饰器嵌套攻击额,我们可以发现一层装饰器其实就是把原函数嵌套进另一个函数中间,因此我们只需要一层一层的剥开嵌套就可以了。
# -*- coding:utf-8 -*-# zhou# 2017/6/17def outer0(func):def inner():print('Hello, Kitty.')
ret = func()print('我是日本人.')return innerdef outer(func):def inner():print('你是哪国人?')
ret = func()print('你呢?')return inner
@outer0
@outerdef test1():print('我是中国人.')
test1()
结果Hello, Kitty.
你是哪国人?
我是中国人.
你呢?
我是日本人.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
En ce qui concerne le problème de la suppression de l'interpréteur Python qui est livré avec des systèmes Linux, de nombreuses distributions Linux préinstalleront l'interpréteur Python lors de l'installation, et il n'utilise pas le gestionnaire de packages ...
 Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?
Apr 02, 2025 am 07:12 AM
Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?
Apr 02, 2025 am 07:12 AM
Chargement des fichiers de cornichons dans Python 3.6 Rapport de l'environnement Erreur: modulenotFoundError: NomoduLenamed ...
 Debian Strings est-il compatible avec plusieurs navigateurs
Apr 02, 2025 am 08:30 AM
Debian Strings est-il compatible avec plusieurs navigateurs
Apr 02, 2025 am 08:30 AM
"Debianstrings" n'est pas un terme standard, et sa signification spécifique n'est pas encore claire. Cet article ne peut pas commenter directement la compatibilité de son navigateur. Cependant, si "DebianStrings" fait référence à une application Web exécutée sur un système Debian, sa compatibilité du navigateur dépend de l'architecture technique de l'application elle-même. La plupart des applications Web modernes se sont engagées à compatibilité entre les navigateurs. Cela repose sur les normes Web suivantes et l'utilisation de technologies frontales bien compatibles (telles que HTML, CSS, JavaScript) et les technologies back-end (telles que PHP, Python, Node.js, etc.). Pour s'assurer que l'application est compatible avec plusieurs navigateurs, les développeurs doivent souvent effectuer des tests croisés et utiliser la réactivité
 La modification XML nécessite-t-elle une programmation?
Apr 02, 2025 pm 06:51 PM
La modification XML nécessite-t-elle une programmation?
Apr 02, 2025 pm 06:51 PM
La modification du contenu XML nécessite une programmation, car elle nécessite une recherche précise des nœuds cibles pour ajouter, supprimer, modifier et vérifier. Le langage de programmation dispose de bibliothèques correspondantes pour traiter XML et fournit des API pour effectuer des opérations sûres, efficaces et contrôlables comme les bases de données de fonctionnement.
 La vitesse de conversion est-elle rapide lors de la conversion du XML en PDF sur le téléphone mobile?
Apr 02, 2025 pm 10:09 PM
La vitesse de conversion est-elle rapide lors de la conversion du XML en PDF sur le téléphone mobile?
Apr 02, 2025 pm 10:09 PM
La vitesse du XML mobile à PDF dépend des facteurs suivants: la complexité de la structure XML. Méthode de conversion de configuration du matériel mobile (bibliothèque, algorithme) Méthodes d'optimisation de la qualité du code (sélectionnez des bibliothèques efficaces, optimiser les algorithmes, les données de cache et utiliser le multi-threading). Dans l'ensemble, il n'y a pas de réponse absolue et elle doit être optimisée en fonction de la situation spécifique.
 Comment modifier le contenu des commentaires dans XML
Apr 02, 2025 pm 06:15 PM
Comment modifier le contenu des commentaires dans XML
Apr 02, 2025 pm 06:15 PM
Pour les petits fichiers XML, vous pouvez remplacer directement le contenu d'annotation par un éditeur de texte; Pour les fichiers volumineux, il est recommandé d'utiliser l'analyseur XML pour le modifier pour garantir l'efficacité et la précision. Soyez prudent lors de la suppression des commentaires XML, le maintien des commentaires aide généralement à coder la compréhension et la maintenance. Les conseils avancés fournissent un exemple de code Python pour modifier les commentaires à l'aide de l'analyseur XML, mais l'implémentation spécifique doit être ajustée en fonction de la bibliothèque XML utilisée. Faites attention aux problèmes d'encodage lors de la modification des fichiers XML. Il est recommandé d'utiliser le codage UTF-8 et de spécifier le format de codage.
 Y a-t-il une application mobile qui peut convertir XML en PDF?
Apr 02, 2025 pm 08:54 PM
Y a-t-il une application mobile qui peut convertir XML en PDF?
Apr 02, 2025 pm 08:54 PM
Une application qui convertit le XML directement en PDF ne peut être trouvée car ce sont deux formats fondamentalement différents. XML est utilisé pour stocker des données, tandis que PDF est utilisé pour afficher des documents. Pour terminer la transformation, vous pouvez utiliser des langages de programmation et des bibliothèques telles que Python et ReportLab pour analyser les données XML et générer des documents PDF.
 Comment définir un type d'énumération à Protobuf et associer des constantes de chaîne?
Apr 02, 2025 pm 03:36 PM
Comment définir un type d'énumération à Protobuf et associer des constantes de chaîne?
Apr 02, 2025 pm 03:36 PM
Problèmes de définition de l'énumération constante de la chaîne à Protobuf Lorsque vous utilisez Protobuf, vous rencontrez souvent des situations où vous devez associer le type d'énumération aux constantes de chaîne ...
