

parcours d'apprentissage de Python
Dans ce chapitre, l'auteur présente brièvement le modèle de données Python, principalement certaines méthodes spéciales de Python. Par exemple, __len__, __getitem__. Et utilisez un programme de cartes à jouer pour expliquer ces méthodes
Tout d'abord, introduisons la différence entre Tuple et nametuple :
Nametuple est similaire à un type de données tuple. En plus de pouvoir accéder aux données à l'aide d'index, il prend également en charge l'accès aux données à l'aide de noms de propriétés pratiques.
L'accès traditionnel aux tuples est le suivant. L'accès à chaque élément doit être trouvé via index. Cette méthode de recherche est très peu intuitive
tup1=(,,) tup1[1]
Utilisez nametuple pour construire :
tup2=namedtuple(,[,,]) t1=tup2(,,) t1 t1.age t1.height t1.name
得到结果如下,namedtupel中tuple2是类型名,name,age,height是属性名字
从上面的访问可以看到,直接用t1.age的方法访问更加直观。当然也可以用索引比如t1[0]的方法来访问

namedtupe1 prend également en charge l'accès itératif :
t t1: t
和元组一样,namedtupel中的元素也是不可变更的。如果执行t1.age+=1。将会提示无法设置元素
Traceback (dernier appel le plus récent) :
Fichier "E:/py_prj/fluent_py.py", ligne 17, dans < ;module>
t1.age+=1
AttributeError : impossible de définir l'attribut
Jetons un coup d'œil à l'exemple de carte à jouer dans le book, le code Comme suit :
collections namedtuple Card=namedtuple(,[,]) FrenchDeck: ranks=[str(n) n range(2,11)] + list() suits=.split() __init__(self): self._cards=[Card(rank,suit) suit self.suits
rank self.ranks] __len__(self): len(self._cards) __getitem__(self, position): self._cards[position] __name__==: deck=FrenchDeck() len(deck) deck[1]
Définit d'abord le tuple de la carte Card, le rang représente le numéro de la carte et la couleur représente la couleur de la carte. Ensuite, FrenchDeck définit d’abord la signification spécifique des rangs et des couleurs. Initialisez self._cards dans __init__.
__len__ renvoie la longueur des self._cards. __getitem__ renvoie la valeur spécifique de la carte.
Le résultat est le suivant, la longueur de la carte est de 52, où le deck[1] est Card(rank='3',suit='spades')

Vous pouvez voir que len(deck) appelle en fait la méthode __len__. deck[1] appelle __getitem__
Grâce à la méthode __getitem__, un accès itératif peut également être effectué, comme suit :
d deck: d
Puisqu'il est itérable, alors nous peut simuler le mécanisme de distribution aléatoire de cartes.
from random import choice
print choice(deck)
Obtenez le résultat :
Card(rank='9', suit='hearts')
Regarder ensuite Un autre exemple, concernant les opérations vectorielles. Par exemple, il existe le vecteur 1, vecteur1(1,2) et le vecteur 2, vecteur2(3,4). Alors le résultat de vecteur1+vecteur2 devrait être (4,6). Vector1 et vector2 sont tous deux des vecteurs, comment mettre en œuvre l'opération ? La méthode est __add__, __mul__
Le code est le suivant :
vector: __init__(self,x=0,y=0): self.x=x self.y=y __repr__(self): % (self.x,self.y) __abs__(self): hypot(self.x,self.y) __bool__(self): bool(abs(self)) __add__(self,other): x=self.x+other.x y=self.y+other.y vector(x,y) __mul__(self, scalar): vector(self.x*scalar,self.y*scalar)
__name__==: v1=vector(1,2) v2=vector(2,3) v1+v2 abs(v1) v1*3
Le résultat de l'opération est le suivant :
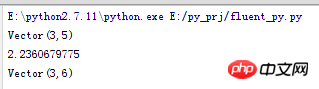
Ici, __add__ ,__mul__,__abs__ implémentent respectivement les opérations d'addition, de multiplication et de modulo vectorielles.
Il convient de mentionner la méthode __repr__. Cette méthode est appelée lorsque l'objet doit être imprimé. Par exemple, lors de l'impression de vector(1,2), vous obtenez vector(1,2). Sinon, c'est une chaîne représentant l'objet :
<br>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut se connecter à MARIADB, à condition que la configuration soit correcte. Sélectionnez d'abord "MariADB" comme type de connecteur. Dans la configuration de la connexion, définissez correctement l'hôte, le port, l'utilisateur, le mot de passe et la base de données. Lorsque vous testez la connexion, vérifiez que le service MARIADB est démarré, si le nom d'utilisateur et le mot de passe sont corrects, si le numéro de port est correct, si le pare-feu autorise les connexions et si la base de données existe. Dans une utilisation avancée, utilisez la technologie de mise en commun des connexions pour optimiser les performances. Les erreurs courantes incluent des autorisations insuffisantes, des problèmes de connexion réseau, etc. Lors des erreurs de débogage, analysez soigneusement les informations d'erreur et utilisez des outils de débogage. L'optimisation de la configuration du réseau peut améliorer les performances
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Comment résoudre MySQL ne peut pas se connecter à l'hôte local
Apr 08, 2025 pm 02:24 PM
Comment résoudre MySQL ne peut pas se connecter à l'hôte local
Apr 08, 2025 pm 02:24 PM
La connexion MySQL peut être due aux raisons suivantes: le service MySQL n'est pas démarré, le pare-feu intercepte la connexion, le numéro de port est incorrect, le nom d'utilisateur ou le mot de passe est incorrect, l'adresse d'écoute dans my.cnf est mal configurée, etc. 2. Ajustez les paramètres du pare-feu pour permettre à MySQL d'écouter le port 3306; 3. Confirmez que le numéro de port est cohérent avec le numéro de port réel; 4. Vérifiez si le nom d'utilisateur et le mot de passe sont corrects; 5. Assurez-vous que les paramètres d'adresse de liaison dans My.cnf sont corrects.
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
En tant que professionnel des données, vous devez traiter de grandes quantités de données provenant de diverses sources. Cela peut poser des défis à la gestion et à l'analyse des données. Heureusement, deux services AWS peuvent aider: AWS Glue et Amazon Athena.
