
Récemment, en train d'apprendre python, j'étais un peu dérouté par les différents encodages, j'ai donc lu les documents laissés par mon prédécesseurs, ajoutez votre propre compréhension, préparez-vous à l'écrire et partagez-la avec vous qui avez des difficultés avec le codage.
L'encodage consiste à convertir les informations d'un format à un autre format ne comprenant que le binaire, une compréhension simple, en convertissant le. le texte que nos yeux voient dans un format binaire que l'ordinateur peut reconnaître est considéré comme un codage, et le processus de conversion du binaire en texte que nous pouvons voir dans un certain format de codage peut être considéré comme un décodage. Puisque les ordinateurs ne peuvent reconnaître que les nombres binaires 0 et 1, comment les lettres, les chiffres et les mots que nous utilisons leur correspondent-ils ? Alors continuez à lire !
La spécification d'encodage par défaut affichée en python est :
import sysprint(sys.getdefaultencoding())#运行结果:utf-8
Nous savons tous que l'ordinateur a été inventé aux États-Unis. Au début, il n'était utilisé que par ces pays des États-Unis, et leur langage ne comprenait que 26 lettres, plus quelques symboles, donc au début. en commençant, en utilisant La règle de codage est le code ASCⅡ. ASCⅡ, le nom chinois est American Standard Code for Information Interchange, car il s'appelle American Standard Code for Information Interchange. Jetons un coup d'œil au tableau ASCⅡ :

Le code ASCⅡ utilise un octet, qui est un groupe binaire de 8 bits, pour identifier un caractère. Par exemple, 00100001 représente le caractère ! , la première version d'ASCII n'utilisait pas le bit le plus élevé, la plage de valeurs est donc comprise entre 0 et 127, ce qui ne peut représenter que 128 caractères. Afin de répondre aux exigences en matière de caractères de l'Europe occidentale et d'autres pays, le bit le plus élevé a été utilisé et le nombre de caractères pouvant être représentés a été augmenté de 128 à 256.

>>> ord("a") #将字符转换为数值97>>> ord("A")65>>> chr(65)'A'>>> chr(97) #将数值转换为字符'a'>>>
当计算机漂洋过海来到了中国,ASCⅡ已经不能满足我大天朝的需求了,常用的汉字大致都有2k-3k。所以中国国家标准总局在1980发布了《信息交换用汉字编码字符集》,也就是GB2313标准。GB2312一共收录了7445个字符(6763个汉字和682个其他符号),包括拉丁字母、希腊字母和日文平假名等,基本上满足了国人的需求。
在GB2312中每个汉字使用两个字节来表示,分为高字节和低字节,汉字区高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768,其中有5个空位是D7FA-D7FE,规定第一个字节大于127的就代表这是一个汉字的开始(这一个字节和下一个字节就代表一个汉字),每个字节的最高位都位1。
但是对于人名、古汉语等方面出现的罕用字,GB2312不能处理,后来就出现了GBK。GBK向下兼容GB2312,其编码范围从8140到FEFE(不包括xx7F),共23940个码位,共收录了21003个汉字,这还是很厉害的了。现在我们使用的计算机默认的就是GBK编码。

我们国家搞出了GBK,其他的国家也搞出了各种各样的编码,比如小日本的SJIJ,宝岛台湾的BIG5,国际组织一看,这不行啊,每个地方都各自搞各自的,那么在不同的国家之间就会出现不兼容,我用GBK编码格式写的软件,弄到你编码格式为SJIJ的计算机就不能执行了。所以就出现了Unicode,也称万国码。unicode是用2个字节来表示一个字符的,65536类个字符,这足以覆盖世界上所有的文字。
这样虽好,但是美国人民就不开心了,我一个字母,比如'a'就需要占用一个字节,现在需要占用两个字节,这样就大大的浪费了内存和硬盘的空间,所有后来就出现了UTF-32,UTF-16和UTF-8,前两个这里就不在敖述了,现在并不常用,我们这看看这个UTF-8,UTF-8是一种可变长的编码格式,存储英文字母只需要一个字节,存储汉字需要3个字节,但超大字符集中的更大多数汉字要占4个字节。我们在内存里面的数据是unicode,在传输数据和保存数据的时候使用UTF-8已节省空间和带宽。
在python2中默认的编码是ASCII,python2的字符串类型有两种:str和Unicode,这两个只是字符串类型的名字,我们主要看它们在内存里面的内存地址:
= = u repr(name2) #输出结果
'\xe5\xbd\xac\xe5\xbd\xac' #字节数据
u'\u5f6c\u5f6c' #Unicode数据

在python2中,str类型字符串类型在内存中存储的是bytes数据,Unicode类型字符串在内存中存储的是unicode数据。那两种数据之间是什么关系了?这里就涉及到了解码(encode)和编码(decode)了。
= name2 = u = name.decode(= name2.encode(<type ><type >
由上运行结果可知,unicode转换为bytes数据的过程是编码。从bytes数据转换为unicode数据的过程是解码。我们再来看一下:
#coding=utf8name = '彬彬'name3 = name.decode('big5')print name3#运行结果敶砍蓮我们可以看到得到一堆乱文,name存在内存里的时候是以UTF编码成的bytes数据,而我们这里decode('big5')使用big5来解码,虽然成功了,但是输出结果却不是我们想要的结果。
当我们把第一行coding改为big5的时候就不会出现乱文了,
#coding=big5name = '彬彬'name3 = name.decode('big5')print name3#运行结果彬彬所以我们用什么规则编码的就要用什么区解码!

注意:我们在终端显示出来的明文,就是你用户所看到的,其实都是已经转换成unicode到内存里面,而bytes数据一般都是计算机识别的。
在Python3中也定义了2种类型的字符串类型,str和bytes,str类型存储unicode数据,bytes类型存储bytes数据。
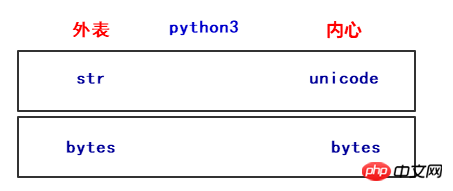
name = "彬彬"name2 = b"hello"print(type(name))print(type(name.encode('utf8')))print(type(name.encode('gbk')))print(type(name2))print(type(name2.decode('utf8')))#运行结果<class 'str'>
<class 'bytes'>
<class 'bytes'>
<class 'bytes'>
<class 'str'>如上运行结果,bytes转换为unicode为解码,uicode转为bytes数据类型为编码。

由上图所示,在不同的编码之间转换的时候,我们都要经过unicode这个中转站,没办法,虽然unicode老大哥强大呢,当我们想把utf-8编码的数据转换为gbk的,我们就需要把utf-8的数据先解码成unicode,再由unicode编码成gbk。
在py2和py3中有个重要的区分就是,py2会自动把bytes数据解码成unicode,而py3就不会自动把bytes解码成unicode了。所以说py3更清晰的区分了bytes数据和unicode。
#py2中print(u"liu" + "bin")#运行结果liubin
( + b, line 2, <module>( + bbytes
print("liu" + (b"bin").decode('utf8'))
#运行结果liubin
那我们创建.py文件,到执行.py文件,这里面的编码和解码是怎么来的呢?
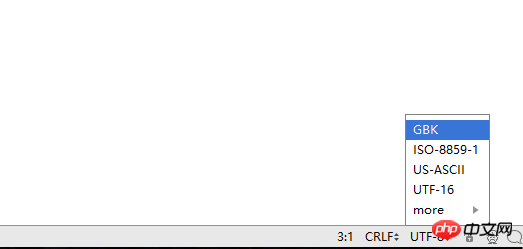
1.当我们创建一个.py文件的时候,会有一个默认的编码格式(这里以pycharm为例),在右下角,默认是UTF-8,当然你也可以选择其他的编码:
2.当我们在.py文件里面写入代码的时候,会以unicode的编码格式保存在内存中;
print("你好,世界!")
3.当我们保存的时候,会将Unicode数据编码成utf-8格式的数据,然后保存在硬盘里面;
4.当我们执行文件的时候,pycharm会调用python的解释器来读取文件,在py2中,默认会以ASCII将代码解码成unicode数据,但是ASCII码并不认识中文,所以就会出现报错。
File "E:/py/�ַ�����.py", line 2SyntaxError: Non-ASCII character '\xe4' in file E:/py/�ַ�����.py on line 2, but no encoding declared; see for details
所以,在py2中,我们需要加上:
#coding=utf8print("你好,世界!")#运行结果你好,世界!但是在py3中就不存在这个问题了,只要编码的时候适用的是UTF-8,python3默认的编码规范就是UTF-8,它会用UTF-8来将UTF-8的bytes数据解码成unicode,然后在计算机终端显示!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



