
Types de données Python
Opérateurs Python
Boucles Python et déclarations de jugement
exercices Python
Devoirs Python
num1 = 123 # 变量名 = 数字 num2 = 456 num3 = int(123 (num2) 6 print(num3)
def bit_length(self): # real signature unknown; restored from __doc__
#--------------这个功能主要是计算出int类型对应的二进制位的位数---------------------------------------
"""
int.bit_length() -> int
Number of bits necessary to represent self in binary.
>>> bin(37)
'0b100101'
>>> (37).bit_length()
6
"""
return 0Exemple :
num = 128 # 128的二进制10000000,它占了一个字节,八位print(num.bit_length()) 显示:8
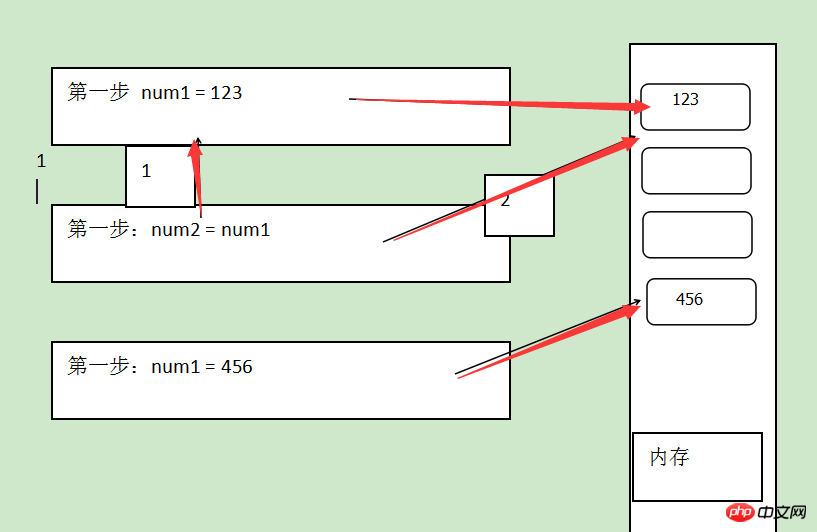
Chaque affectation à la classe int nécessite un nouvel espace d'adressage pour le stockage sans modifier la valeur de l'espace d'adressage d'origine.
num1 = 123num2 = num1 num1 = 456print(num1)print(num2) 显示:456 123
Principe :
La première étape de l'affectation : ouvrez un espace pour stocker 123, et la variable est num1.
La deuxième étape de l'affectation : pointe d'abord vers num1, puis pointe vers 123 via l'adresse.
La troisième partie de la mission : rouvrez un espace d'adressage pour stocker 456, et le pointage de num2 reste inchangé.
str = 'hello huwentao.'print(str[1]) # 因为下标是从零开始的,因此答案是e显示: e
# str[1:-1:2] 第一个数代表起始位置,第二个数代表结束位置(-1代表最后),第三个数代表步长(每隔2个字符选择一个)str = 'hellohuwentao.'print(str[1])print(str[1:])print(str[1:-1:2]) 显示结果: e ellohuwentao. elhwna
#长度用的是len这个函数,这个长度可能和c有点不太一样,是不带换行符的。所一结果就是14str = 'hellohuwentao.'print(len(str)) 显示:14
<5>. Fonctions supplémentaires
# print里面的end指的是每输出一行,在最后一个字符后面加上引号内的内容,此处为空格,默认为换行符str = 'hellohuwentao.'for i in str:print(i, end=' ') 显示: h e l l o h u w e n t a o .
 Voir le code
Voir le code
def capitalize(self): # real signature unknown; restored from __doc__
#------------------首字母大写------------------------------=-------------------------------------"""S.capitalize() -> str
Return a capitalized version of S, i.e. make the first character
have upper case and the rest lower case."""return ""def center(self, width, fillchar=None): # real signature unknown; restored from __doc__#-----------------居中,width代表的是宽度,fillchar是代表填充的字符''.center(50,'*')--------------------"""S.center(width[, fillchar]) -> str
Return S centered in a string of length width. Padding is
done using the specified fill character (default is a space)"""return ""def count(self, sub, start=None, end=None): # real signature unknown; restored from __doc__#-----------------和列表的count一样,计算出和sub一样的字符的个数,start,end带表起始和结束的位置--------------"""S.count(sub[, start[, end]]) -> int
Return the number of non-overlapping occurrences of substring sub in
string S[start:end]. Optional arguments start and end are
interpreted as in slice notation."""return 0def encode(self, encoding='utf-8', errors='strict'): # real signature unknown; restored from __doc__#---------------代表指定的编码,默认为‘utf-8’,如果错了会强制指出错误-------------------------------------"""S.encode(encoding='utf-8', errors='strict') -> bytes
Encode S using the codec registered for encoding. Default encoding
is 'utf-8'. errors may be given to set a different error
handling scheme. Default is 'strict' meaning that encoding errors raise
a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
'xmlcharrefreplace' as well as any other name registered with
codecs.register_error that can handle UnicodeEncodeErrors."""return b""def endswith(self, suffix, start=None, end=None): # real signature unknown; restored from __doc__#------------------判断endswith是不是以suffix这个参数结尾--------------------------------------------"""S.endswith(suffix[, start[, end]]) -> bool
Return True if S ends with the specified suffix, False otherwise.
With optional start, test S beginning at that position.
With optional end, stop comparing S at that position.
suffix can also be a tuple of strings to try."""return Falsedef expandtabs(self, tabsize=8): # real signature unknown; restored from __doc__#-----------可以理解为扩展tab键,后面的tabsize=8代表默认把tab键改成8个空格,可以修改值-----------------------"""S.expandtabs(tabsize=8) -> str
Return a copy of S where all tab characters are expanded using spaces.
If tabsize is not given, a tab size of 8 characters is assumed."""return ""def find(self, sub, start=None, end=None): # real signature unknown; restored from __doc__#------------从左往右查找和sub相同的字符,并把所在的位置返回,如果没有查到返回-1------------------------------"""S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure."""return 0def format(self, *args, **kwargs): # known special case of str.format#-----------------指的是格式,也就是在字符中有{}的,都会一一替换str = 'huwegwne g{name},{age}'print(str.format(name = '111',age = '22'))
结果:huwegwne g111, 22
------------------------------------------"""S.format(*args, **kwargs) -> str
Return a formatted version of S, using substitutions from args and kwargs.
The substitutions are identified by braces ('{' and '}')."""passdef index(self, sub, start=None, end=None): # real signature unknown; restored from __doc__#-------------和find一样,只是如果没有查找到会报错-----------------------------------------------------"""S.index(sub[, start[, end]]) -> int
Like S.find() but raise ValueError when the substring is not found."""return 0 return Falsedef join(self, iterable): # real signature unknown; restored from __doc__#------------------通过字符来连接一个可迭代类型的数据li = ['alec','arix','Alex','Tony','rain']print('*'.join(li))
结果:alec*arix*Alex*Tony*rain---------------------------------"""S.join(iterable) -> str
Return a string which is the concatenation of the strings in the
iterable. The separator between elements is S."""return ""def ljust(self, width, fillchar=None): # real signature unknown; restored from __doc__#----------------和center类型,只不过它是向左对齐,而不是居中--------------------------------------------"""S.ljust(width[, fillchar]) -> str
Return S left-justified in a Unicode string of length width. Padding is
done using the specified fill character (default is a space)."""return ""def lower(self): # real signature unknown; restored from __doc__#--------------------全部转换成小写----------------------------------------------------------------"""S.lower() -> str
Return a copy of the string S converted to lowercase."""return ""def lstrip(self, chars=None): # real signature unknown; restored from __doc__#-------------------和strip类似,用来删除指定的首尾字符,默认为空格--------------------------------------
"""S.lstrip([chars]) -> str
Return a copy of the string S with leading whitespace removed.
If chars is given and not None, remove characters in chars instead."""return ""def partition(self, sep): # real signature unknown; restored from __doc__#-----------------------------partition() 方法用来根据指定的分隔符将字符串进行分割。"""S.partition(sep) -> (head, sep, tail)
Search for the separator sep in S, and return the part before it,
the separator itself, and the part after it. If the separator is not
found, return S and two empty strings."""passdef replace(self, old, new, count=None): # real signature unknown; restored from __doc__#-------------------替换,用新的字符串去替换旧的字符串-------------------------------------------------"""S.replace(old, new[, count]) -> str
Return a copy of S with all occurrences of substring
old replaced by new. If the optional argument count is
given, only the first count occurrences are replaced."""return ""def rfind(self, sub, start=None, end=None): # real signature unknown; restored from __doc__#-----------和find类似,只不过是从右向左查找----------------------------------------------------------"""S.rfind(sub[, start[, end]]) -> int
Return the highest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure."""return 0def rindex(self, sub, start=None, end=None): # real signature unknown; restored from __doc__#-----------和index类似,只不过是从右向左查找----------------------------------------------------------"""S.rindex(sub[, start[, end]]) -> int
Like S.rfind() but raise ValueError when the substring is not found."""return 0def rjust(self, width, fillchar=None): # real signature unknown; restored from __doc__#----------------和center类型,只不过它是向右对齐,而不是居中--------------------------------------------
"""S.rjust(width[, fillchar]) -> str
Return S right-justified in a string of length width. Padding is
done using the specified fill character (default is a space)."""return ""def rpartition(self, sep): # real signature unknown; restored from __doc__"""S.rpartition(sep) -> (head, sep, tail)
Search for the separator sep in S, starting at the end of S, and return
the part before it, the separator itself, and the part after it. If the
separator is not found, return two empty strings and S."""passdef rsplit(self, sep=None, maxsplit=-1): # real signature unknown; restored from __doc__#----------------------------和split相似,只不过是从右向左分离---------------------------------------
"""S.rsplit(sep=None, maxsplit=-1) -> list of strings
Return a list of the words in S, using sep as the
delimiter string, starting at the end of the string and
working to the front. If maxsplit is given, at most maxsplit
splits are done. If sep is not specified, any whitespace string
is a separator."""return []def rstrip(self, chars=None): # real signature unknown; restored from __doc__#--------------方法用于移除字符串尾部指定的字符(默认为空格)。---------------------------------------------"""S.rstrip([chars]) -> str
Return a copy of the string S with trailing whitespace removed.
If chars is given and not None, remove characters in chars instead."""return ""def split(self, sep=None, maxsplit=-1): # real signature unknown; restored from __doc__#--------------------------------方法用于把一个字符串分割成字符串数组默认是以空格隔离----------------------"""S.split(sep=None, maxsplit=-1) -> list of strings
Return a list of the words in S, using sep as the
delimiter string. If maxsplit is given, at most maxsplit
splits are done. If sep is not specified or is None, any
whitespace string is a separator and empty strings are
removed from the result."""return []def splitlines(self, keepends=None): # real signature unknown; restored from __doc__"""S.splitlines([keepends]) -> list of strings
Return a list of the lines in S, breaking at line boundaries.
Line breaks are not included in the resulting list unless keepends
is given and true."""return []def startswith(self, prefix, start=None, end=None): # real signature unknown; restored from __doc__#---------------------------判断是不是以prefix字符开头----------------------------------------------"""S.startswith(prefix[, start[, end]]) -> bool
Return True if S starts with the specified prefix, False otherwise.
With optional start, test S beginning at that position.
With optional end, stop comparing S at that position.
prefix can also be a tuple of strings to try."""return Falsedef strip(self, chars=None): # real signature unknown; restored from __doc__#-----------用于移除字符串头尾指定的字符(默认为空格)。------------------------------------------"""S.strip([chars]) -> str
Return a copy of the string S with leading and trailing
whitespace removed.
If chars is given and not None, remove characters in chars instead."""return ""def swapcase(self): # real signature unknown; restored from __doc__#-------------------------------------- 方法用于对字符串的大小写字母进行转换。-------------------------
"""S.swapcase() -> str
Return a copy of S with uppercase characters converted to lowercase
and vice versa."""return ""def title(self): # real signature unknown; restored from __doc__#-----------------------------把每一个单词的首字母都变成大写------------------------------------------"""S.title() -> str
Return a titlecased version of S, i.e. words start with title case
characters, all remaining cased characters have lower case."""return ""def translate(self, table): # real signature unknown; restored from __doc__"""S.translate(table) -> str
Return a copy of the string S in which each character has been mapped
through the given translation table. The table must implement
lookup/indexing via __getitem__, for instance a dictionary or list,
mapping Unicode ordinals to Unicode ordinals, strings, or None. If
this operation raises LookupError, the character is left untouched.
Characters mapped to None are deleted."""return ""def upper(self): # real signature unknown; restored from __doc__#-------------------------------把全部的字母变成大写------------------------------------------------"""S.upper() -> str
Return a copy of S converted to uppercase."""return ""# 和字符串一样,列表下标默认也是从0开始list = ['huwentao','xiaozhou','tengjiang','mayan']print(list[1]) 显示 xiaozhou
# 和字符换也是一样的,也是起始位置,结束位置,和步长list = ['huwentao','xiaozhou','tengjiang','mayan']print(list[2])print(list[1:3:1]) 显示: tengjiang ['xiaozhou', 'tengjiang']
# 和字符串一样,长度代表着元祖里面元素的个数list = ['huwentao','xiaozhou','tengjiang','mayan']print(len(list)) 显示;4
# 和字符串相同,此处就不在进行说明list = ['huwentao','xiaozhou','tengjiang','mayan']for i in list:print(i,end=' ') 显示: huwentao xiaozhou tengjiang mayan


# 里面的参数self是代表自身,如果只有self,在调用的时候不用传递参数,如果是等于,就代表有默认的传递值,可不用传递参数def append(self, p_object): # real signature unknown; restored from __doc__#--------------在列表后面添加数据--------------------------------------""" L.append(object) -> None -- append object to end """passdef clear(self): # real signature unknown; restored from __doc__#--------------清空列表---------------------------------------------- """ L.clear() -> None -- remove all items from L """passdef copy(self): # real signature unknown; restored from __doc__#--------------------复制列表并赋值给a = li.copy()----------------------""" L.copy() -> list -- a shallow copy of L """return []def count(self, value): # real signature unknown; restored from __doc__# ---------------计算列表中和value相同的字符串的个数---------------------""" L.count(value) -> integer -- return number of occurrences of value """return 0def extend(self, iterable): # real signature unknown; restored from __doc__# -----------------把一个可迭代类型的数据整天添加到列表中-----------------""" L.extend(iterable) -> None -- extend list by appending elements from the iterable """passdef index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__#------------------找到和value相同的数据所在列表中的位置,后面的两个参数代表开始位置和结束位置--------"""L.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present."""return 0def insert(self, index, p_object): # real signature unknown; restored from __doc__#--------------------在index这个位置插入p_object值---------------------------------""" L.insert(index, object) -- insert object before index """passdef pop(self, index=None): # real signature unknown; restored from __doc__# ------------------删除index这个位置的数据,返回给一个变量------------------------"""L.pop([index]) -> item -- remove and return item at index (default last).
Raises IndexError if list is empty or index is out of range."""passdef remove(self, value): # real signature unknown; restored from __doc__#--------------------删除value的数据,不会返回给某个变量---------------------------"""L.remove(value) -> None -- remove first occurrence of value.
Raises ValueError if the value is not present."""passdef reverse(self): # real signature unknown; restored from __doc__#-------------------------翻转,就是把最后一个元素放在第一个,依次类推--------------""" L.reverse() -- reverse *IN PLACE* """passdef sort(self, key=None, reverse=False): # real signature unknown; restored from __doc__#-------------------------排序--------------------------------------------------""" L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE* """pass<2>. Tranches
tuple = ('huwentao','xiaozhou','tengjiang','mayan')for i in tuple:print(i, end=' ') 显示: huwentao xiaozhou tengjiang mayan
# 字典的索引和其他的不太一样,他的主要是通过键值对进行索引的,里面的不是下标,而是他的键dic = {'k1':'alex','k2':'aric','k3':'Alex','k4':'Tony'}print(dic['k1'])
print(len(dic))可以输出字典的长度,代表的是字典的键值对长度。
# 字典的循环也比较有意思,他循环输出的不是键值对,而是字典的键dic = {'k1':'alex','k2':'aric','k3':'Alex','k4':'Tony'}for i in dic:print(i)# 逻辑运算值有: and or not # and 代表 与# or 代表或# not 代表非a = 8b = 16c = 5print('c<a<b', c<a<b)print('a > c and a > b', a > c and a > b)print('a > c and a < b', a > c or a < b)print('not a>c ', not a>c) 显示: c<a<b True a > c and a > b False a > c and a < b Tr
循环和判断语句最重要的是要学习他的结构,结构记住了就是往里面套条件就是了,下面先说一下Python的特点
缩进 在很多语言里面,每一个结构都是有头有尾的,不是小括号就是大括号,因此,很多语言通过其自身的结构就会知道程序到哪里结束,从哪里开始,但是Python不一样,Python本身并没有一个表示结束的标志(有人会觉得这样会使程序简单,但是有人会觉得这样会使程序变得麻烦),不管怎样,那Python是通过什么来标志一个程序的结束的呢?那就是缩进,因此缩进对于Python来讲还是蛮重要的。尤其对这些判断循环语句。
结构: while condition: statement statemnet if........... 这个while循环只会执行statement,因为后面的if和statement的缩进不一样,因此当跳出while循环的时候才会执行后面的if语句
事例:执行了三次beautiful,执行了一次ugly
num = 3
while num < 6:print('you are beautiful.', num)
num += 1
print('you are ugly.')
显示:
you are beautiful. 3you are beautiful. 4you are beautiful. 5you are ugly.结构:for var in condition:
statement
statementif ............
for后面的跟的是变量,in后面跟的是条件,当执行完for循环之后,才会执行后面的if语句
事例:显示了三次beautiful,一次ugly,因为他们的缩进不同 i = 1for i in range(3):print('you are beautiful.', i)print('you are ugly.') 显示: you are beautiful. 0 you are beautiful. 1you are beautiful. 2you are ugly.
结构:if condition:
statement
statementelse:
statement1
statement2
statement3...........
当满足条件,则执行statement,否则执行statement1和2,执行完了之后执行statement3
事例: a = 16b = 89if a > b:print('a>b')else:print('a<b')print('you are right.') 显示: a<b you are right.
1. 使用while循环输入1 2 3 4 5 6 8 9
num = 1
while num < 10:
if num == 7:
num += 1
continue
print(num, end = ' ')
num += 12. 求1-100内的所有奇数之和
# -*- coding:GBK -*-
# zhou
# 2017/6/13
num = 1
sum = 0
while num < 100:
if num % 2 == 1:
sum += num
num += 1
print('所有奇数之和为: ',sum)
3. 输出1-100内的所有奇数
# -*- coding:GBK -*-
# zhou
# 2017/6/13
num = 1
sum = 0
while num <= 100:
if num % 2 == 1:
print(num,end = ' ')
num += 14. 输出1-100内的所有偶数
# -*- coding:GBK -*-
# zhou
# 2017/6/13
num = 1
sum = 0
while num <= 100:
if num % 2 == 0:
sum += num
num += 1
print('所有偶数之和为: ',sum)5. 求1-2+3-4+5........99的所有数之和
# -*- coding:GBK -*-
# zhou
# 2017/6/13
num = 1
sum = 0
while num < 100:
if num % 2 == 1:
sum -= num
else:
sum += num
num += 1
print(sum)6. 用户登录程序(三次机会)
# -*- coding:GBK -*-
# zhou
# 2017/6/13
name = 'hu'
password = 'hu'
num = 1
while num <= 3:
user_name = input('Name: ')
user_password = input('Password: ')
if user_name == name and user_password == password:
print('you are ok. ')
break
num += 1
else:
print('you are only three chance, now quit.')1. 有如下值集合{11,22,33,44,55,66,77,88,99.......},将所有大于66的值保存至字典的第一个key中,将小于66 的值保存至第二个key的值中,即:{‘k1’:大于66的所有值,‘k2’:小于66的所有值}
# -*- coding:GBK -*-
# zhou
# 2017/6/13
dict = {'k1':[],'k2':[]}
list = [11,22,33,44,55,66,77,88,99,100]
for i in list:
if i <= 66:
dict['k1'].append(i)
else:
dict['k2'].append(i)
print(dict)
2. 查找列表中的元素,移动空格,并查找以a或者A开头 并且以c结尾的所有元素
li = ['alec','Aric','Alex','Tony','rain']
tu = ('alec','Aric','Alex','Tony','rain')
dic = {'k1':'alex', 'k2':'Aric', 'k3':'Alex', 'k4':'Tony'}
# -*- coding:GBK -*-
# zhou
# 2017/6/13
li = ['alec','arix','Alex','Tony','rain']
tu = ('alec','aric','Alex','Tony','rain')
dic = {'k1':'alex', 'k2':'aric', 'k3':'Alex', 'k4':'Tony'}
print('对于列表li:')
for i in li:
if i.endswith('c') and (i.startswith('a') or i.startswith('A')):
print(i)
print('对于元组tu:')
for i in tu:
if i.endswith('c') and (i.startswith('a') or i.startswith('A')) :
print(i)
print('对于字典dic:')
for i in dic:
if dic[i].endswith('c') and (dic[i].startswith('a') or dic[i].startswith('A')):
print(dic[i])
3. 输出商品列表,用户输入序号,显示用户选中的商品
商品 li = ['手机','电脑','鼠标垫', '游艇']
# -*- coding:GBK -*-
# zhou
# 2017/6/13
li = ['手机','电脑','鼠标垫', '游艇']
# 打印商品信息
print('shop'.center(50,'*'))
for shop in enumerate(li, 1):
print(shop)
print('end'.center(50,'*'))
# 进入循环输出信息
while True:
user = input('>>>[退出:q] ')
if user == 'q':
print('quit....')
break
else:
user = int(user)
if user > 0 and user <= len(li):
print(li[user - 1])
else:
print('invalid iniput.Please input again...')4. 购物车
要求用户输入自己的资产
显示商品的列表,让用户根据序号选择商品,加入购物车
购买,如果商品总额大于总资产,提示账户余额不足,否则,购买成功
附加:可充值,某商品移除购物车
# -*- coding:GBK -*-
# zhou
# 2017/6/13
name = 'hu'
password = 'hu'
num = 1
while num <= 3:
user_name = input('Name: ')
user_password = input('Password: ')
if user_name == name and user_password == password:
print('you are ok. ')
flag = True
break
num += 1
else:
print('you are only three chance, now quit.')
shop = {
'手机': 1000,
'电脑': 8000,
'笔记本': 50,
'自行车': 300,
}
shop_car = []
list = []
if flag:
salary = input('Salary: ')
if salary.isdigit():
salary = int(salary)
while True:
print('shop'.center(50, '*'))
for i in enumerate(shop, 1):
print(i)
list.append(i)
print('end'.center(50, '*'))
user_input_shop = input('input shop num:[quit: q]>>:')
if user_input_shop.isdigit():
user_input_shop = int(user_input_shop)
if user_input_shop > 0 and user_input_shop <= len(shop):
if salary >= shop[list[user_input_shop - 1][1]]:
print(list[user_input_shop - 1])
salary -= shop[list[user_input_shop - 1][1]]
shop_car.append(list[user_input_shop - 1][1])
else:
print('余额不足.')
else:
print('invalid input.Input again.')
elif user_input_shop == 'q':
print('您购买了一下商品:')
print(shop_car)
print('您的余额为:', salary)
break
else:
print('invalid input.Input again.')
else:
print('invalid.')
第二个简单版本
# -*- coding:GBK -*-
# zhou
# 2017/6/13
'''
1. 输入总资产
2. 显示商品
3. 输入你要购买的商品
4. 加入购物车
5. 结算
'''
i1 = input('请输入总资产:')
salary = int(i1)
car_good = []
goods = [
{'name':'电脑','price':1999},
{'name':'鼠标','price':10},
{'name':'游艇','price':20},
{'name':'手机','price':998}
]
for i in goods:
print(i['name'], i['price'])
while True:
i2 = input('请输入你想要的商品: ')
if i2.lower() == 'y':
break
else:
for i in goods:
if i2 == i['name']:
car_good.append(i)
print(i)
#结算
price = 0
print(car_good)
for i in car_good:
price += i['price']
if price > salary:
print('您买不起.....')
else:
print('您购买了一下商品:')
for i in car_good:
print(i['name'],i['price'])
print('您的余额为:', salary-price)
5. 三级联动
# -*- coding:GBK -*-
# zhou
# 2017/6/13
dict = {
'河南':{
'洛阳':'龙门',
'郑州':'高铁',
'驻马店':'美丽',
},
'江西':{
'南昌':'八一起义',
'婺源':'最美乡村',
'九江':'庐山'
}
}
sheng = []
shi = []
xian = []
for i in dict:
sheng.append(i)
print(sheng)
flag = True
while flag:
for i in enumerate(dict,1):
print(i)
sheng.append(i)
user_input = input('input your num: ')
if user_input.isdigit():
user_input = int(user_input)
if user_input > 0 and user_input <= len(dict):
for i in enumerate(dict[sheng[user_input - 1]], 1):
print(i)
shi.append(i)
user_input_2 = input('input your num: ')
if user_input_2.isdigit():
user_input_2 = int(user_input_2)
if user_input_2 > 0 and user_input_2 <= len(shi):
for i in dict[sheng[user_input - 1]][shi[user_input_2 - 1][1]]:
print(i, end = '')
print()
else:
print('invalid input')
else:
print('invalid input.')
else:
print('invalid input. Input again.')
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



