

Comment faire un bon robot d'exploration Web ?

L'essence des robots d'exploration Web est en fait de « voler » des données sur Internet. Grâce aux robots d'exploration Web, nous pouvons collecter les ressources dont nous avons besoin, mais de la même manière, une utilisation inappropriée peut également causer de graves problèmes.
Par conséquent, lorsque nous utilisons des robots d'exploration Web, nous devons être capables de "voler de la bonne manière".
Les robots d'exploration Web sont principalement divisés dans les trois catégories suivantes :
1. Petite échelle, petite quantité de données et vitesse d'exploration insensible ; pour cela, nous pouvons utiliser la bibliothèque Requests pour implémenter des robots d'exploration Web, qui sont principalement utilisés pour explorer des pages Web
2. À échelle moyenne, avec une grande échelle de données et une vitesse d'exploration sensible pour ce type de robot d'exploration Web ; peut utiliser la bibliothèque Scrapy. Implémentation, principalement utilisée pour explorer des sites Web ou des séries de sites Web ;
3. Moteur de recherche à grande échelle, la vitesse d'exploration est essentielle à l'heure actuelle, un développement personnalisé est requis, principalement utilisé pour explorer ; l'ensemble du réseau, généralement pour construire l'ensemble du réseau Moteurs de recherche, tels que Baidu, recherche Google, etc.
Parmi ces trois types, le premier est le plus courant, et la plupart d'entre eux sont des robots d'exploration à petite échelle qui explorent les pages Web.
Il existe également de nombreuses objections aux robots d'exploration Web. Parce que les robots d'exploration enverront constamment des requêtes au serveur, ce qui affectera les performances du serveur, provoquera du harcèlement sur le serveur et augmentera la charge de travail des responsables de la maintenance du site Web.
En plus du harcèlement des serveurs, les robots d'exploration du Web peuvent également entraîner des risques juridiques. Étant donné que les données sur le serveur ont des droits de propriété, si les données sont utilisées à des fins lucratives, cela entraînera des risques juridiques.
En outre, les robots d'exploration Web peuvent également provoquer des fuites de confidentialité des utilisateurs.
En bref, le risque des robots d'exploration du web vient principalement des trois points suivants :
Performance du serveur Harcèlement
Risques juridiques au niveau du contenu
Fuite de la vie privée
Par conséquent, le Web crawlers L'utilisation nécessite certaines règles.
Dans des situations réelles, certains sites Web plus importants ont imposé des restrictions pertinentes aux robots d'exploration Web, et les robots d'exploration Web sont également considérés comme une fonction standardisable sur l'ensemble d'Internet.
Pour les serveurs généraux, nous pouvons limiter les robots d'exploration de 2 manières :
1 Si le propriétaire du site Web dispose de certaines capacités techniques pour le faire. limiter les robots d'exploration Web grâce à l'examen des sources.
L'examen des sources est généralement limité en jugeant l'agent utilisateur. Cet article se concentre sur le deuxième type.
2. Utilisez le protocole Robots pour indiquer aux robots d'exploration les règles qu'ils doivent respecter, celles qui peuvent être explorées et celles qui ne sont pas autorisées, et exigez que tous les robots d'exploration se conforment à ce protocole.
La deuxième méthode consiste à informer sous la forme d'une annonce que l'accord sur les robots est recommandé mais que les robots d'exploration Web peuvent ne pas s'y conformer, mais qu'il peut y avoir des risques juridiques. Grâce à ces deux méthodes, des restrictions morales et techniques efficaces sont créées sur les robots d'exploration Web sur Internet.
Ensuite, lorsque nous écrivons un robot d'exploration Web, nous devons respecter la gestion des ressources du site Web par les responsables du site Web.
Sur Internet, certains sites Web n'ont pas le protocole Robots et toutes les données peuvent être explorées ; cependant, la grande majorité des sites Web grand public prennent en charge le protocole Robots et ont des restrictions pertinentes. introduction à la syntaxe de base du protocole Robots.
Protocole Robots (Robots Exclusion Standard, norme d'exclusion des robots d'exploration Web) :
Fonction : Le site Web indique aux robots d'exploration Web quelles pages peuvent être explorées et lequel non.
Formulaire : fichier robots.txt dans le répertoire racine du site.
Syntaxe de base du protocole Robots : * représente tout, / représente le répertoire racine.
Par exemple, le protocole Robots de PMCAFF :
User-agent : *
Interdire : /article/edit
Interdire : /discuss/write
Interdire : /discuss/edit
à la ligne 1 Utilisateur -agent :* signifie que tous les robots d'exploration Web doivent respecter les protocoles suivants :
Interdire : /article/edit à la ligne 2 signifie que tous les robots d'exploration Web ne sont pas autorisés à accéder aux articles sous article/modifier le contenu, le il en va de même pour les autres.
Si vous observez le protocole Robots de JD.com, vous pouvez voir qu'il existe un agent utilisateur : EtaoSpider, Disallow : /, où EtaoSpider est un robot malveillant et n'est autorisé à explorer aucune ressource de JD.com.
User-agent : *
Interdire : /?*
Interdire : /pop /*.html
Interdire : /pinpai/*.html?*
Agent utilisateur : EtaoSpider
Interdire : /
Agent utilisateur : HuihuiSpider
Interdire : /
Agent utilisateur : GwdangSpider
Interdire : /
Agent utilisateur : WochachaSpider
Interdire : /
Avec le protocole Robots, vous pouvez réguler le contenu du site Web et indiquer à tous les robots d'exploration Web lesquels peuvent être explorés et lesquels ne sont pas autorisés.
Il est important de noter que le protocole Robots existe dans le répertoire racine. Différents répertoires racine peuvent avoir des protocoles Robots différents , vous devez donc faire plus attention lors de l'exploration.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



![Le module d'extension WLAN s'est arrêté [correctif]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) Le module d'extension WLAN s'est arrêté [correctif]
Feb 19, 2024 pm 02:18 PM
Le module d'extension WLAN s'est arrêté [correctif]
Feb 19, 2024 pm 02:18 PM
S'il y a un problème avec le module d'extension WLAN sur votre ordinateur Windows, cela peut entraîner une déconnexion d'Internet. Cette situation est souvent frustrante, mais heureusement, cet article propose quelques suggestions simples qui peuvent vous aider à résoudre ce problème et à rétablir le bon fonctionnement de votre connexion sans fil. Réparer le module d'extensibilité WLAN s'est arrêté Si le module d'extensibilité WLAN a cessé de fonctionner sur votre ordinateur Windows, suivez ces suggestions pour le réparer : Exécutez l'utilitaire de résolution des problèmes réseau et Internet pour désactiver et réactiver les connexions réseau sans fil Redémarrez le service de configuration automatique WLAN Modifier les options d'alimentation Modifier Paramètres d'alimentation avancés Réinstaller le pilote de la carte réseau Exécuter certaines commandes réseau Examinons-le maintenant en détail
 Comment résoudre l'erreur du serveur DNS Win11
Jan 10, 2024 pm 09:02 PM
Comment résoudre l'erreur du serveur DNS Win11
Jan 10, 2024 pm 09:02 PM
Nous devons utiliser le DNS correct lors de la connexion à Internet pour accéder à Internet. De la même manière, si nous utilisons des paramètres DNS incorrects, cela entraînera une erreur du serveur DNS. À ce stade, nous pouvons essayer de résoudre le problème en sélectionnant d'obtenir automatiquement le DNS dans les paramètres réseau. solutions. Comment résoudre l'erreur du serveur DNS du réseau Win11. Méthode 1 : Réinitialiser le DNS 1. Tout d'abord, cliquez sur Démarrer dans la barre des tâches pour entrer, recherchez et cliquez sur le bouton icône « Paramètres ». 2. Cliquez ensuite sur la commande d'option "Réseau et Internet" dans la colonne de gauche. 3. Recherchez ensuite l'option « Ethernet » sur la droite et cliquez pour entrer. 4. Après cela, cliquez sur "Modifier" dans l'attribution du serveur DNS et définissez enfin DNS sur "Automatique (D
 Corrigez les téléchargements « Échec de l'erreur réseau » sur Chrome, Google Drive et Photos !
Oct 27, 2023 pm 11:13 PM
Corrigez les téléchargements « Échec de l'erreur réseau » sur Chrome, Google Drive et Photos !
Oct 27, 2023 pm 11:13 PM
Qu'est-ce que le problème « Échec du téléchargement de l'erreur réseau » ? Avant d’aborder les solutions, comprenons d’abord ce que signifie le problème « Échec du téléchargement de l’erreur réseau ». Cette erreur se produit généralement lorsque la connexion réseau est interrompue pendant le téléchargement. Cela peut se produire pour diverses raisons telles qu'une faible connexion Internet, une congestion du réseau ou des problèmes de serveur. Lorsque cette erreur se produit, le téléchargement s'arrêtera et un message d'erreur s'affichera. Comment réparer l’échec du téléchargement avec une erreur réseau ? Faire face à « Échec du téléchargement d'une erreur réseau » peut devenir un obstacle lors de l'accès ou du téléchargement des fichiers nécessaires. Que vous utilisiez des navigateurs comme Chrome ou des plateformes comme Google Drive et Google Photos, cette erreur apparaîtra, provoquant des désagréments. Vous trouverez ci-dessous des points pour vous aider à naviguer et à résoudre ce problème.
 Correctif : WD My Cloud n'apparaît pas sur le réseau sous Windows 11
Oct 02, 2023 pm 11:21 PM
Correctif : WD My Cloud n'apparaît pas sur le réseau sous Windows 11
Oct 02, 2023 pm 11:21 PM
Si WDMyCloud n'apparaît pas sur le réseau sous Windows 11, cela peut être un gros problème, surtout si vous y stockez des sauvegardes ou d'autres fichiers importants. Cela peut constituer un gros problème pour les utilisateurs qui ont fréquemment besoin d'accéder au stockage réseau. Dans le guide d'aujourd'hui, nous allons donc vous montrer comment résoudre ce problème de manière permanente. Pourquoi WDMyCloud n'apparaît-il pas sur le réseau Windows 11 ? Votre appareil MyCloud, votre adaptateur réseau ou votre connexion Internet n'est pas configuré correctement. La fonction SMB n'est pas installée sur l'ordinateur. Un problème temporaire dans Winsock peut parfois être à l'origine de ce problème. Que dois-je faire si mon cloud n'apparaît pas sur le réseau ? Avant de commencer à résoudre le problème, vous pouvez effectuer quelques vérifications préliminaires :
 Que dois-je faire si la Terre s'affiche dans le coin inférieur droit de Windows 10 alors que je ne peux pas accéder à Internet Diverses solutions au problème selon lequel la Terre ne peut pas accéder à Internet dans Win10 ?
Feb 29, 2024 am 09:52 AM
Que dois-je faire si la Terre s'affiche dans le coin inférieur droit de Windows 10 alors que je ne peux pas accéder à Internet Diverses solutions au problème selon lequel la Terre ne peut pas accéder à Internet dans Win10 ?
Feb 29, 2024 am 09:52 AM
Cet article présentera la solution au problème selon lequel le symbole du globe s'affiche sur le réseau du système Win10 mais ne peut pas accéder à Internet. L'article fournira des étapes détaillées pour aider les lecteurs à résoudre le problème du réseau Win10 montrant que la Terre ne peut pas accéder à Internet. Méthode 1 : Redémarrez directement. Vérifiez d'abord si le câble réseau n'est pas correctement branché et si le haut débit est en retard. Dans ce cas, vous devez redémarrer le routeur ou le modem optique. Si aucune action importante n'est effectuée sur l'ordinateur, vous pouvez redémarrer l'ordinateur directement. La plupart des problèmes mineurs peuvent être rapidement résolus en redémarrant l'ordinateur. S’il est déterminé que le haut débit n’est pas en retard et que le réseau est normal, c’est une autre affaire. Méthode 2 : 1. Appuyez sur la touche [Win] ou cliquez sur [Menu Démarrer] dans le coin inférieur gauche. Dans l'élément de menu qui s'ouvre, cliquez sur l'icône d'engrenage au-dessus du bouton d'alimentation. Il s'agit de [Paramètres].
 Vérifiez la connexion réseau : mdr impossible de se connecter au serveur
Feb 19, 2024 pm 12:10 PM
Vérifiez la connexion réseau : mdr impossible de se connecter au serveur
Feb 19, 2024 pm 12:10 PM
LOL ne peut pas se connecter au serveur, veuillez vérifier le réseau. Ces dernières années, les jeux en ligne sont devenus une activité de divertissement quotidienne pour de nombreuses personnes. Parmi eux, League of Legends (LOL) est un jeu multijoueur en ligne très populaire, attirant la participation et l'intérêt de centaines de millions de joueurs. Cependant, parfois, lorsque nous jouons à LOL, nous rencontrons le message d'erreur "Impossible de se connecter au serveur, veuillez vérifier le réseau", ce qui pose sans aucun doute quelques ennuis aux joueurs. Ensuite, nous discuterons des causes et des solutions de cette erreur. Tout d'abord, le problème selon lequel LOL ne peut pas se connecter au serveur peut être
 Que se passe-t-il lorsque le réseau ne parvient pas à se connecter au wifi ?
Apr 03, 2024 pm 12:11 PM
Que se passe-t-il lorsque le réseau ne parvient pas à se connecter au wifi ?
Apr 03, 2024 pm 12:11 PM
1. Vérifiez le mot de passe wifi : assurez-vous que le mot de passe wifi que vous avez saisi est correct et faites attention à la casse. 2. Confirmez si le wifi fonctionne correctement : Vérifiez si le routeur wifi fonctionne normalement. Vous pouvez connecter d'autres appareils au même routeur pour déterminer si le problème vient de l'appareil. 3. Redémarrez l'appareil et le routeur : Parfois, il y a un dysfonctionnement ou un problème de réseau avec l'appareil ou le routeur, et le redémarrage de l'appareil et du routeur peut résoudre le problème. 4. Vérifiez les paramètres de l'appareil : assurez-vous que la fonction sans fil de l'appareil est activée et que la fonction Wi-Fi n'est pas désactivée.
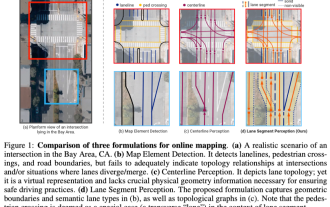 ICLR'24 nouvelles idées sans images ! LaneSegNet : apprentissage cartographique basé sur la connaissance de la segmentation des voies
Jan 19, 2024 am 11:12 AM
ICLR'24 nouvelles idées sans images ! LaneSegNet : apprentissage cartographique basé sur la connaissance de la segmentation des voies
Jan 19, 2024 am 11:12 AM
Écrit ci-dessus & La compréhension personnelle de l'auteur des cartes en tant qu'informations clés pour les applications en aval des systèmes de conduite autonome est généralement représentée par des voies ou des lignes centrales. Cependant, la littérature existante sur l’apprentissage cartographique se concentre principalement sur la détection des relations topologiques des voies basées sur la géométrie ou sur la détection des lignes médianes. Les deux méthodes ignorent la relation inhérente entre les lignes de voie et les lignes centrales, c'est-à-dire que les lignes de voie lient les lignes centrales. Bien que la simple prédiction de deux types de voies dans un modèle s'excluent mutuellement dans l'objectif d'apprentissage, cet article propose le segment de voie comme une nouvelle représentation qui combine de manière transparente les informations géométriques et topologiques, proposant ainsi LaneSegNet. Il s'agit du premier réseau cartographique de bout en bout qui génère des segments de voie pour obtenir une représentation complète de la structure routière. LaneSegNet a deux niveaux
