
 base de données
tutoriel mysql
Exemple de didacticiel sur le niveau d'isolement des transactions MySQL
base de données
tutoriel mysql
Exemple de didacticiel sur le niveau d'isolement des transactions MySQL
Exemple de didacticiel sur le niveau d'isolement des transactions MySQL

L'environnement de test pour l'expérience de cet article : Windows 10+cmd+MySQL5.6.36+InnoDB
1. Éléments de base des transactions (ACID)
1. commence, toutes les opérations sont terminées ou non, et il est impossible de stagner au milieu. Si une erreur se produit lors de l'exécution de la transaction, elle sera restaurée à l'état avant le début de la transaction et toutes les opérations se dérouleront comme si elles ne s'étaient pas produites. C’est-à-dire que les choses forment un tout indivisible, tout comme les atomes appris en chimie, qui sont les unités de base de la matière.
2. Cohérence : avant et après le début et la fin de la transaction, les contraintes d'intégrité de la base de données ne sont pas violées. Par exemple, si A transfère de l’argent à B, il est impossible pour A de déduire l’argent mais B de ne pas le recevoir.
4. Durabilité : Une fois la transaction terminée, toutes les mises à jour de la base de données par la transaction seront Enregistré dans la base de données et ne peut pas être restauré.
Résumé : L'atomicité est la base de l'isolement des transactions, l'isolement et la durabilité sont les moyens et l'ultime objectif Il s’agit de maintenir la cohérence des données.
2. Problèmes de concurrence des transactions
1. Lecture sale : la transaction A lit les données mises à jour par la transaction B, puis B annule l'opération, puis les données lues par A sont des données sales
2. Lecture non répétable : la transaction A lit les mêmes données plusieurs fois et la transaction B lit les mêmes données plusieurs fois dans la transaction A. . Les données ont été mises à jour et soumises, ce qui a entraîné des résultats incohérents lorsque la transaction A a lu les mêmes données plusieurs fois.
3. Lecture fantôme : l'administrateur système A modifie les scores de tous les élèves de la base de données à partir de scores spécifiques C'est le niveau ABCDE, mais l'administrateur système B a inséré un enregistrement avec un score spécifique à ce moment-là. Lorsque l'administrateur système A a terminé la modification, il a constaté qu'il y avait encore un enregistrement qui n'avait pas été modifié. appelée lecture fantôme.
Résumé : La lecture non répétable et la lecture fantôme sont faciles à confondre, la lecture non répétable se concentre sur
Modifier , la lecture fantôme se concentre sur l'ajout ou la suppression de . Pour résoudre le problème de lecture non répétable, il vous suffit de verrouiller les lignes qui remplissent les conditions, et pour résoudre le problème de lecture fantôme, il vous suffit de verrouiller la table 3. Niveau d'isolement des transactions MySQL
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
Le niveau d'isolement des transactions par défaut de MySQL est en lecture répétable
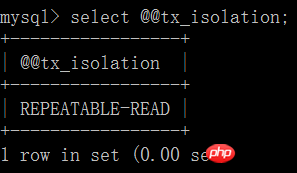
4. Utiliser des exemples pour illustrer chaque niveau d'isolement
1. Lire non engagé :
(1) Ouvrez un client A et définissez le mode de transaction actuel sur lecture non validée (lecture non validée), interrogez la valeur initiale du compte de table :
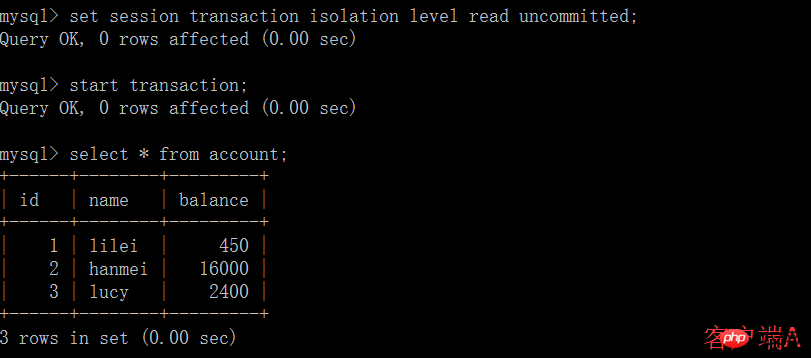
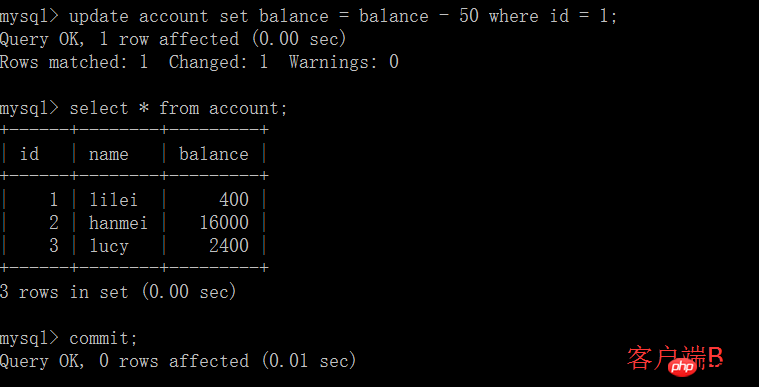
(2) Avant que la transaction du client A ne soit validée, ouvrez un autre client B et mettez à jour le compte de table :
(3) À ce stade, bien que la transaction du client B n'ait pas encore été soumise, le client A peut interroger les données mises à jour de B :
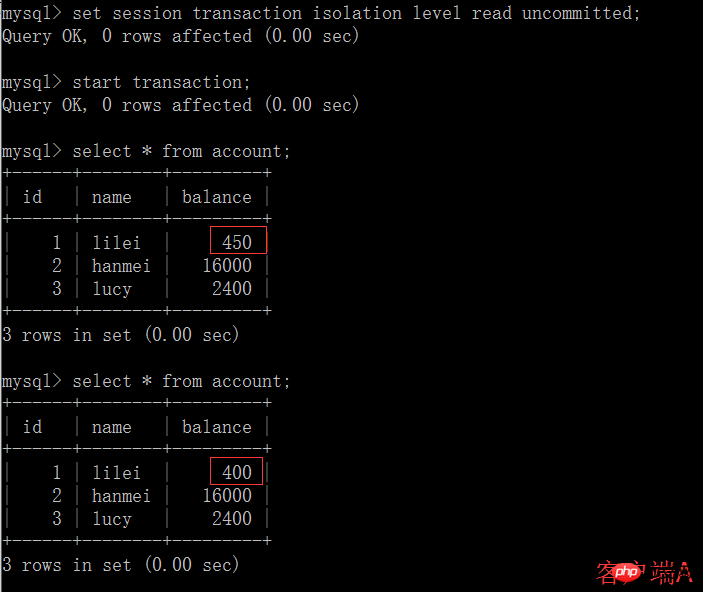
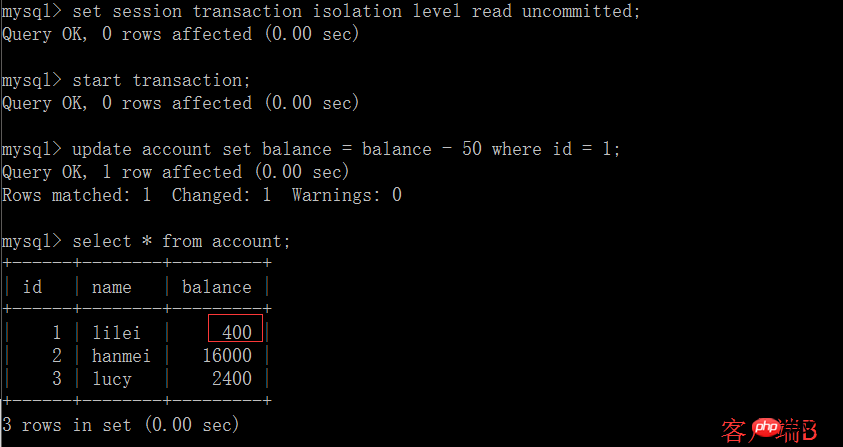
(4) Une fois la transaction du client B annulée pour une raison quelconque, toutes les opérations seront annulées et les données interrogées par le client A sont en fait des données sales :
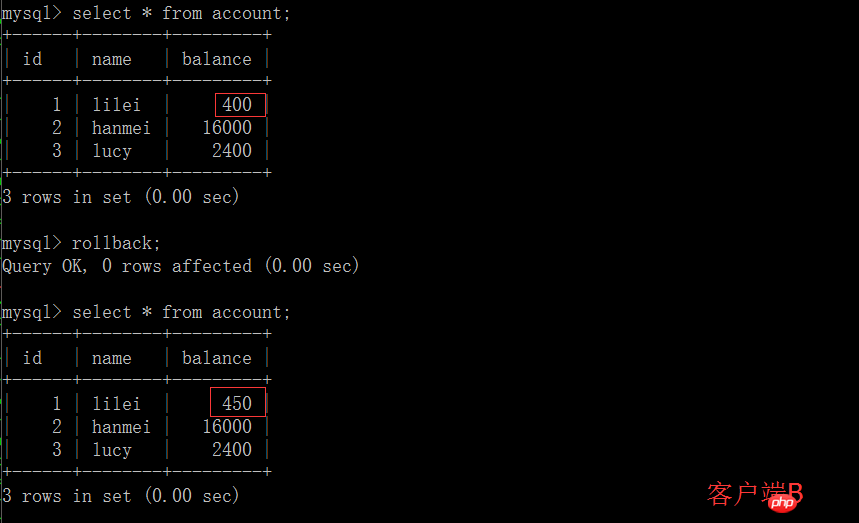
(5) Exécuter l'instruction de mise à jour update account set balance = balance - 50 où id =1 sur le solde du client A. lilei n'est pas devenu 350, mais en réalité 400. N'est-ce pas étrange ? La cohérence des données n'a pas été demandée,Si vous le pensez, vous êtes trop naïf. Dans l'application, nous utiliserons 400-50=350, et nous ne savons pas que d'autres sessions sont annulées. Pour résoudre ce problème, vous pouvez utiliser le niveau d'isolement de lecture validée
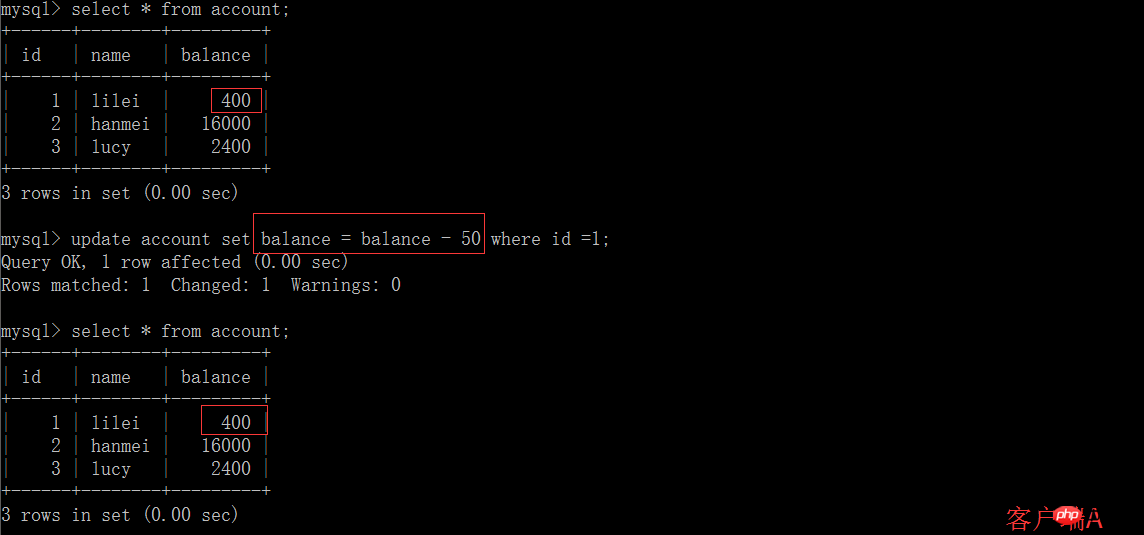
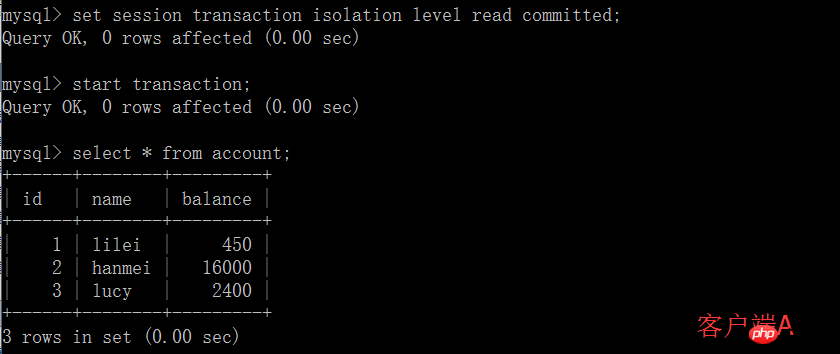
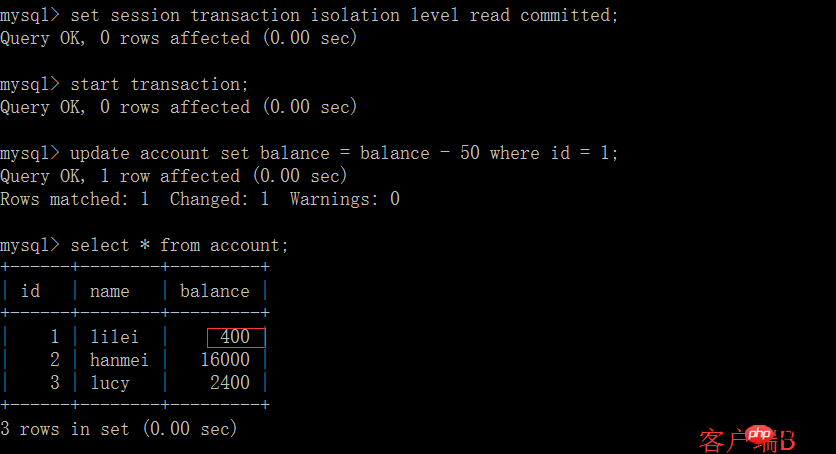
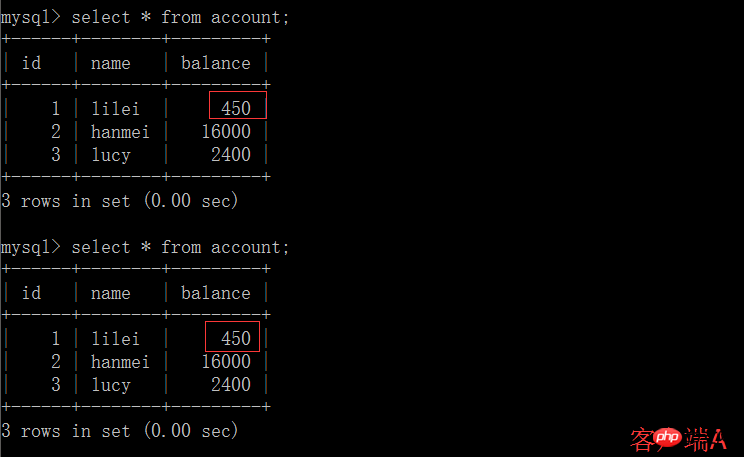
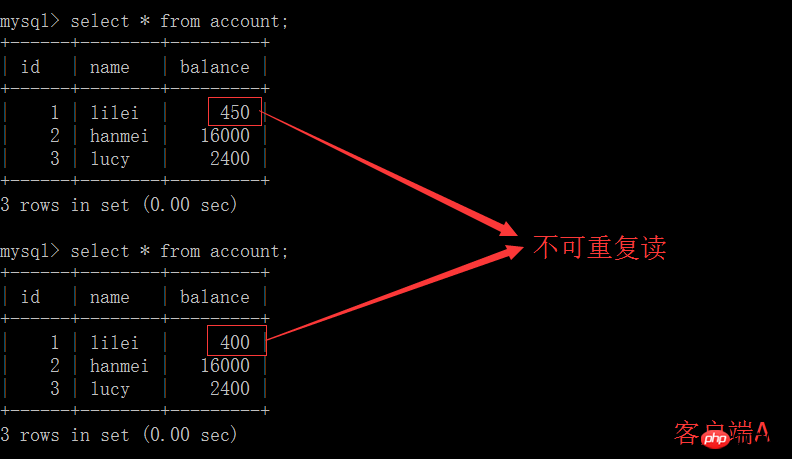
Dans l'application, en supposant que nous sommes dans la session du client A, la requête constate que le solde de lilei est de 450, mais d'autres transactions modifieront le solde de lilei. Je ne sais pas que si nous utilisons la valeur 450 pour effectuer d'autres opérations, il y aura un problème, mais la probabilité est vraiment faible. Pour éviter ce problème, vous pouvez utiliser le niveau d'isolement de lecture répétable
3. Lecture répétable
(1) Ouvrez un client A et définissez le mode de transaction actuel sur lecture répétable, interrogez la valeur initiale du compte de table :
 (2) Avant que la transaction du client A ne soit soumise, ouvrez un autre client B, mettez à jour le compte de table et soumettez,
(2) Avant que la transaction du client A ne soit soumise, ouvrez un autre client B, mettez à jour le compte de table et soumettez,
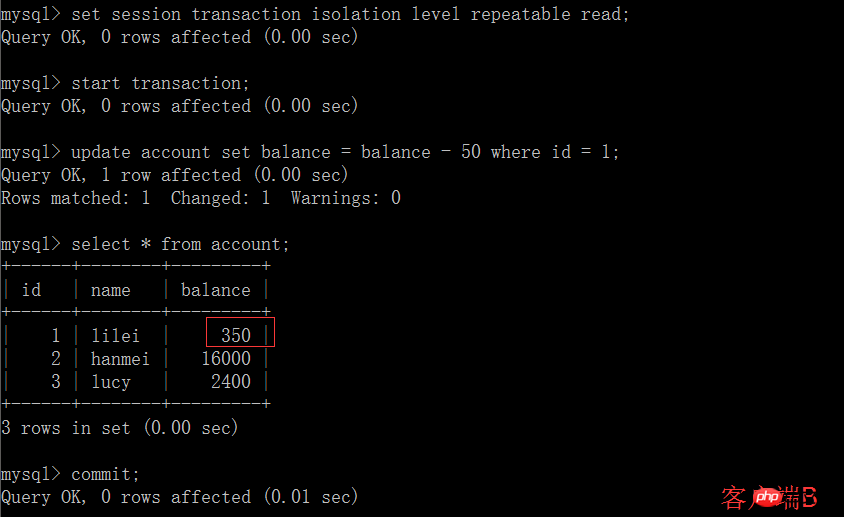 (3 ) Exécutez la requête de l'étape (1) sur le client A :
(3 ) Exécutez la requête de l'étape (1) sur le client A :
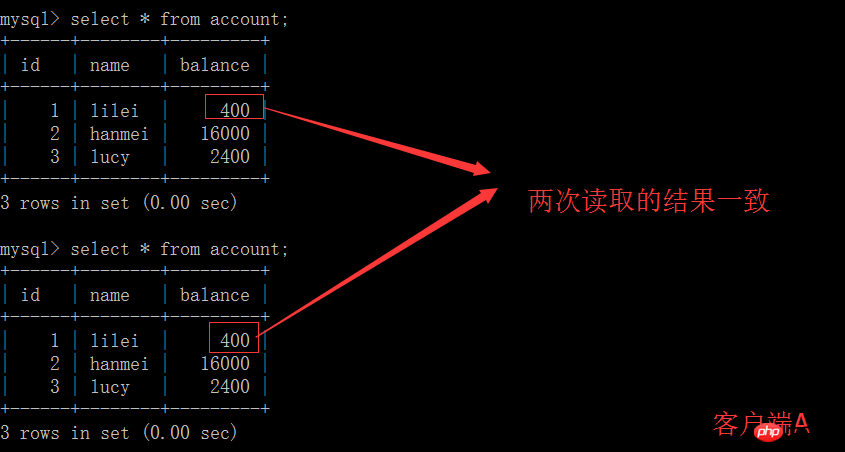
(4) Exécutez l'étape (1), le solde de lilei est toujours de 400, ce qui est cohérent avec le résultat de la requête de l'étape (1), et il n'y a pas de problème de lecture non reproductible ; Ensuite, exécutez update balance = balance - 50 où id = 1, le solde ne devient pas 400-50 = 350, la valeur du solde de lilei est calculée en utilisant 350 à l'étape (2), elle est donc 300, et la cohérence des données n'est pas détruit. , c'est un peu magique, c'est peut-être une fonctionnalité de mysql
mysql> select * from account;+------+--------+---------+| id | name | balance |+------+--------+---------+| 1 | lilei | 400 || 2 | hanmei | 16000 || 3 | lucy | 2400 |+------+--------+---------+3 rows in set (0.00 sec) mysql> update account set balance = balance - 50 where id = 1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from account;+------+--------+---------+| id | name | balance |+------+--------+---------+| 1 | lilei | 300 || 2 | hanmei | 16000 || 3 | lucy | 2400 |+------+--------+---------+3 rows in set (0.00 sec)
(5) Démarrer une transaction sur le client A et interroger la valeur initiale. du compte de table
mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from account;+------+--------+---------+| id | name | balance |+------+--------+---------+| 1 | lilei | 300 || 2 | hanmei | 16000 || 3 | lucy | 2400 |+------+--------+---------+3 rows in set (0.00 sec)
(6) Ouvrez la transaction sur le client B, ajoutez une nouvelle donnée, dans laquelle la valeur du champ de solde est 600, et soumettez
mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into account values(4,'lily',600); Query OK, 1 row affected (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.01 sec)
7) Calculez la somme du solde du client A, et la valeur est 300+16000+2400=18700. La valeur du client B n'est pas incluse. Une fois que le client A a soumis, la somme. du solde est calculé, et il s'avère être 19300. En effet, les 600 du client B sont inclus
, du point de vue du client, le client ne peut pas voir le client B, et il aura l'impression que le monde a a perdu son gâteau, avec 600 yuans supplémentaires. Cette lecture Phantom, du point de vue du développeur, ne détruit pas la cohérence des données. Mais dans l'application, notre code peut soumettre 18700 à l'utilisateur. Si vous devez éviter cette situation de faible probabilité, vous devez alors adopter le niveau d'isolement des transactions "sérialisation" introduit ci-dessous
mysql> solde) du compte;
+-------------+
| somme(solde) |
+-- ------------ +
| 18700 |
+-------------+
1 ligne dans l'ensemble (0,00 sec)
mysql>
Requête OK, 0 ligne affectée (0,00 sec)
mysql> sélectionnez la somme (solde) du compte ;
+-------- ------+
| solde) |
+-------------+
| 19300 |
+----- ----------+
1 ligne dans l'ensemble (0,00 sec)
4. Sérialisation
(1) Ouvrez un client A et définissez le mode de transaction actuel sur sérialisable, et interroger la valeur initiale du compte de table :
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from account;+------+--------+---------+| id | name | balance |+------+--------+---------+| 1 | lilei | 10000 || 2 | hanmei | 10000 || 3 | lucy | 10000 || 4 | lily | 10000 |+------+--------+---------+4 rows in set (0.00 sec)
(2) Ouvrez un client B et définissez le mode de transaction actuel. Il est sérialisable et une erreur est signalée lors de l'insertion d'un record. La table est verrouillée et l'insertion échoue. Lorsque le niveau d'isolement des transactions dans MySQL est sérialisable, la table sera verrouillée, donc les lectures fantômes ne se produiront pas. Ce niveau d'isolement a une concurrence extrêmement faible, et souvent une seule transaction. occupe une table, et des milliers d'autres transactions ne peuvent rester inactives que jusqu'à ce qu'elles soient terminées et soumises avant de pouvoir être utilisées. Ceci est rarement utilisé dans le développement.
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into account values(5,'tom',0); ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
1. La mise en œuvre spécifique des normes stipulées dans la spécification SQL peut être quelque peu différente selon les bases de données
2 . Le niveau d'isolement des transactions par défaut dans MySQL est une lecture répétable et les lignes lues ne seront pas verrouillées
3. Isolation des transactions Lorsque le niveau est sérialisation, la lecture des données verrouillera la table entière
4. Lors de la lecture de cet article , si vous êtes du point de vue d'un développeur, il peut n'y avoir aucun problème logique avec les lectures non répétables et les lectures fantômes, et les données finales sont toujours cohérentes. Cependant, du point de vue de l'utilisateur, ils ne peuvent généralement voir qu'une seule transaction (une seule). la transaction peut être vue). Le client A ne connaît pas l'existence du client infiltré B) et ne considère pas le phénomène d'exécution simultanée de transactions une fois que les mêmes données sont lues plusieurs fois avec des résultats différents, ou que de nouveaux enregistrements apparaissent de manière inattendue. air, ils peuvent avoir des doutes. Il s’agit de problèmes d’expérience utilisateur.
5. Lorsqu'une transaction est exécutée dans MySQL, le résultat final n'aura pas de problèmes de cohérence des données, car dans une transaction dans MySQL , effectuer une opération n'utilisera pas nécessairement les résultats intermédiaires de l'opération précédente. Elle sera traitée en fonction de la situation réelle des autres transactions concurrentes, mais cela garantit la cohérence des données mais la transaction est exécutée dans le application , le résultat d'une opération est utilisé par l'opération suivante et d'autres calculs sont effectués. C'est pourquoi nous devons être prudents. Nous devons verrouiller les lignes lors de la lecture répétable et verrouiller les tables lors de la sérialisation, sinon la cohérence des données sera détruite.
6. Lorsque les transactions sont exécutées dans MySQL, MySQL les traitera de manière exhaustive en fonction de la situation réelle de chaque transaction, ce qui n'entraînera aucun cohérence des données. Détruit, mais l'application joue aux cartes selon des routines logiques, ce qui n'est pas aussi intelligent que MySQL, et des problèmes de cohérence des données surviendront inévitablement.
7
Plus le niveau d'isolement est élevé, plus les données peuvent être complètes et cohérentes, mais cela affectera. les performances de concurrence sont grandes. Plus l’impact est grand, plus vous ne pouvez pas avoir le beurre et l’argent du beurre. Pour la plupart des applications, vous pouvez donner la priorité à la définition du niveau d'isolement du système de base de données sur Lecture validée, ce qui peut éviter les lectures incorrectes et offrir de meilleures performances de concurrence. Bien que cela entraîne des problèmes de concurrence tels que des lectures non répétables et des lectures fantômes, dans des situations individuelles où de tels problèmes peuvent survenir, l'application peut utiliser des verrous pessimistes ou optimistes pour les contrôler.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
Dans la base de données MySQL, la relation entre l'utilisateur et la base de données est définie par les autorisations et les tables. L'utilisateur a un nom d'utilisateur et un mot de passe pour accéder à la base de données. Les autorisations sont accordées par la commande Grant, tandis que le tableau est créé par la commande Create Table. Pour établir une relation entre un utilisateur et une base de données, vous devez créer une base de données, créer un utilisateur, puis accorder des autorisations.
 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Simplification de l'intégration des données: AmazonrDSMysQL et l'intégration Zero ETL de Redshift, l'intégration des données est au cœur d'une organisation basée sur les données. Les processus traditionnels ETL (extrait, converti, charge) sont complexes et prennent du temps, en particulier lors de l'intégration de bases de données (telles que AmazonrDSMysQL) avec des entrepôts de données (tels que Redshift). Cependant, AWS fournit des solutions d'intégration ETL Zero qui ont complètement changé cette situation, fournissant une solution simplifiée et à temps proche pour la migration des données de RDSMySQL à Redshift. Cet article plongera dans l'intégration RDSMYSQL ZERO ETL avec Redshift, expliquant comment il fonctionne et les avantages qu'il apporte aux ingénieurs de données et aux développeurs.
 Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Pour remplir le nom d'utilisateur et le mot de passe MySQL: 1. Déterminez le nom d'utilisateur et le mot de passe; 2. Connectez-vous à la base de données; 3. Utilisez le nom d'utilisateur et le mot de passe pour exécuter des requêtes et des commandes.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
1. Utilisez l'index correct pour accélérer la récupération des données en réduisant la quantité de données numérisées SELECT * FROMMLOYEESEESHWHERELAST_NAME = 'SMITH'; Si vous recherchez plusieurs fois une colonne d'une table, créez un index pour cette colonne. If you or your app needs data from multiple columns according to the criteria, create a composite index 2. Avoid select * only those required columns, if you select all unwanted columns, this will only consume more server memory and cause the server to slow down at high load or frequency times For example, your table contains columns such as created_at and updated_at and timestamps, and then avoid selecting * because they do not require inefficient query se
 Comment copier et coller Mysql
Apr 08, 2025 pm 07:18 PM
Comment copier et coller Mysql
Apr 08, 2025 pm 07:18 PM
Copier et coller dans MySQL incluent les étapes suivantes: Sélectionnez les données, copiez avec Ctrl C (Windows) ou CMD C (Mac); Cliquez avec le bouton droit à l'emplacement cible, sélectionnez Coller ou utilisez Ctrl V (Windows) ou CMD V (Mac); Les données copiées sont insérées dans l'emplacement cible ou remplacer les données existantes (selon que les données existent déjà à l'emplacement cible).
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
