
 développement back-end
Tutoriel Python
Python apprend à capturer les actualités du parc de blogs
développement back-end
Tutoriel Python
Python apprend à capturer les actualités du parc de blogs
Python apprend à capturer les actualités du parc de blogs

前言
说到python,对它有点耳闻的人,第一反应可能都是爬虫~
这两天看了点python的皮毛知识,忍不住想写一个简单的爬虫练练手,JUST DO IT
准备工作
要制作数据抓取的爬虫,对请求的源页面结构需要有特定分析,只有分析正确了,才能更好更快的爬到我们想要的内容。
浏览器访问570973/,右键“查看源代码”,初步只想取一些简单的数据(文章标题、作者、发布时间等),在HTML源码中找到相关数据的部分:
1)标题(url):
2) Auteur : Affiche itwriter
3) Heure de sortie : Publié le 06/06/2017 14:53
4) ID de l'actualité actuelle : Bien sûr, si vous souhaitez suivre l'exemple, la structure des liens "article précédent" et "article suivant" est très importante mais j'ai trouvé un problème avec les deux balises content , est rendu via js, que dois-je faire ? Essayez de trouver des informations (python exécute js et autres), mais pour les novices en python, cela peut être un peu en avance et je prévois de trouver une autre solution. Bien que ces deux liens soient rendus via js, en théorie, la raison pour laquelle js peut restituer le contenu devrait être en lançant une requête et en obtenant la réponse. Ensuite, est-il possible de surveiller la page Web ? processus de chargement pour voir quelles informations utiles il y a ? Je voudrais saluer les navigateurs tels que Chrome/Firefox. Developer Tools/Network peut voir clairement l'état de la demande et de la réponse de toutes les ressources. Leurs adresses de demande sont :
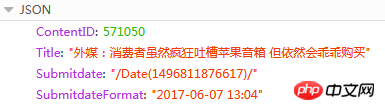
1) ID de l'actualité précédente : 2) ID de l'actualité suivante : Le contenu de la réponse est JSON
Ici, ContentID est ce dont nous avons besoin. En fonction de cette valeur, nous pouvons connaître l'article précédent ou suivant de l'URL d'actualité en cours, car. l'adresse de la page des communiqués de presse a un format fixe :{{ContentID}}
Outils
1) python 3.6 (installer pip en même temps et ajouter des variables d'environnement)
2) PyCharm 2017.1.33) Bibliothèque Python tierce (installation : cmd -> nom d'installation pip)
a) pyperclip : utilisé pour lire et écrire le presse-papiers
b) requêtes : une bibliothèque HTTP basée sur urllib et utilisant le protocole open source sous licence Apache2. C'est plus pratique que urllib et peut nous faire économiser beaucoup de travail
code source
Personnellement, je pense que les codes sont très basiques et faciles à comprendre (après tout, les novices ne peuvent pas écrire de code avancé. Si vous avez des questions ou des suggestions, n'hésitez pas à me le faire savoir
Exécutez
Enregistrez le code source ci-dessus dans D:/get_cnblogs_news.py, sous Windows platform Ouvrez l'outil de ligne de commande cmd :
Saisissez la commande : py.exe D:/get_cnblogs_news.py Saisissez
Analyse : Pas besoin d'expliquer py.exe, le deuxième paramètre est le python fichier de script , le troisième paramètre est la page source qui doit être explorée (il y a une autre considération dans le code. Si vous copiez cette URL dans le presse-papiers du système, vous pouvez l'exécuter directement : py.exe D:/get_cnblogs_news.py
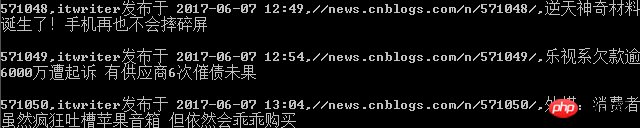
Interface de sortie de ligne de commande (impression)
Contenu enregistré dans un fichier csv

Livre ou matériel d'apprentissage Python recommandé pour les débutants :
1) Le tutoriel Python de Liao Xuefeng, très basique et facile à comprendre :
2 ) Démarrez rapidement avec la programmation Python pour automatiser un travail fastidieux.pdf
L'article n'est qu'un journal pour apprendre Python. S’il y a quelque chose de trompeur, veuillez le critiquer et le corriger (non, s’il vous plaît, ne pas vaporiser), je serais honoré si cela vous aidait.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Une formation efficace des modèles Pytorch sur les systèmes CentOS nécessite des étapes, et cet article fournira des guides détaillés. 1. Préparation de l'environnement: Installation de Python et de dépendance: le système CentOS préinstalle généralement Python, mais la version peut être plus ancienne. Il est recommandé d'utiliser YUM ou DNF pour installer Python 3 et Mettez PIP: sudoyuMupDatePython3 (ou sudodnfupdatepython3), pip3install-upradepip. CUDA et CUDNN (accélération GPU): Si vous utilisez Nvidiagpu, vous devez installer Cudatool
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Lors de la sélection d'une version Pytorch sous CentOS, les facteurs clés suivants doivent être pris en compte: 1. CUDA Version Compatibilité GPU Prise en charge: si vous avez NVIDIA GPU et que vous souhaitez utiliser l'accélération GPU, vous devez choisir Pytorch qui prend en charge la version CUDA correspondante. Vous pouvez afficher la version CUDA prise en charge en exécutant la commande nvidia-SMI. Version CPU: Si vous n'avez pas de GPU ou que vous ne souhaitez pas utiliser de GPU, vous pouvez choisir une version CPU de Pytorch. 2. Version Python Pytorch
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
 Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
CENTOS L'installation de Nginx nécessite de suivre les étapes suivantes: Installation de dépendances telles que les outils de développement, le devet PCRE et l'OpenSSL. Téléchargez le package de code source Nginx, dézippez-le et compilez-le et installez-le, et spécifiez le chemin d'installation AS / USR / LOCAL / NGINX. Créez des utilisateurs et des groupes d'utilisateurs de Nginx et définissez les autorisations. Modifiez le fichier de configuration nginx.conf et configurez le port d'écoute et le nom de domaine / adresse IP. Démarrez le service Nginx. Les erreurs communes doivent être prêtées à prêter attention, telles que les problèmes de dépendance, les conflits de port et les erreurs de fichiers de configuration. L'optimisation des performances doit être ajustée en fonction de la situation spécifique, comme l'activation du cache et l'ajustement du nombre de processus de travail.
