
Je viens d'entrer en contact avec Python récemment. Je recherche quelques petites tâches pour mettre en pratique mes compétences. J'espère pouvoir continuer à exercer ma capacité de résolution de problèmes dans la pratique. Ce petit robot est issu d'un cours sur MOOC. Ce que j'enregistre ici, ce sont les problèmes et les solutions que j'ai rencontrés au cours de mon processus d'apprentissage, ainsi que mes réflexions en dehors du robot.
La petite tâche cette fois est d'écrire un petit robot. La raison la plus importante pour laquelle j'ai choisi de pratiquer cela est que le Big Data est trop chaud, tout comme la météo actuelle à Wuhan. Les données sont au « big data » ce que les armes sont aux soldats, et les briques et les tuiles aux immeubles de grande hauteur. Sans données, le « big data » n’est qu’un nuage dans le ciel, impossible à mettre en pratique. D'où viennent les données ? Il y a deux façons, l’une est de le prendre à soi-même, l’autre est de le prendre aux autres. Inutile de dire que l’autre façon est de prendre les choses des autres, et cet « autre » fait référence à Internet.
Tout d'abord, vous devez comprendre le robot d'exploration : Un programme ou un script (de l'Encyclopédie Baidu) qui capture automatiquement les informations du World Wide Web selon certaines règles . Comme son nom l'indique, vous devez visiter la page, puis enregistrer le contenu sur la page, puis filtrer le contenu qui vous intéresse de la page enregistrée, puis le stocker séparément. Dans la vraie vie, nous faisons souvent ce genre de chose : lors d'un après-midi ennuyeux, nous saisissons une adresse dans le navigateur pour accéder à la page, puis rencontrons un article ou un paragraphe qui nous intéresse, le sélectionnons, puis le copions et le collons dans un mot. document. . Si nous faisons ce qui précède pour une page et le faisons pour des millions de pages, alors vos données deviendront de plus en plus volumineuses. Nous appelons ce processus « collecte de données ».
L'avantage des robots d'exploration est : l'automatisation et le traitement par lots. Il y aura un malentendu ici. Avant d'entrer en contact avec les robots, je pensais que les robots pouvaient explorer des choses que je "ne pouvais pas voir".
Ce qui suit est l'architecture et le processus d'exploration de ce robot
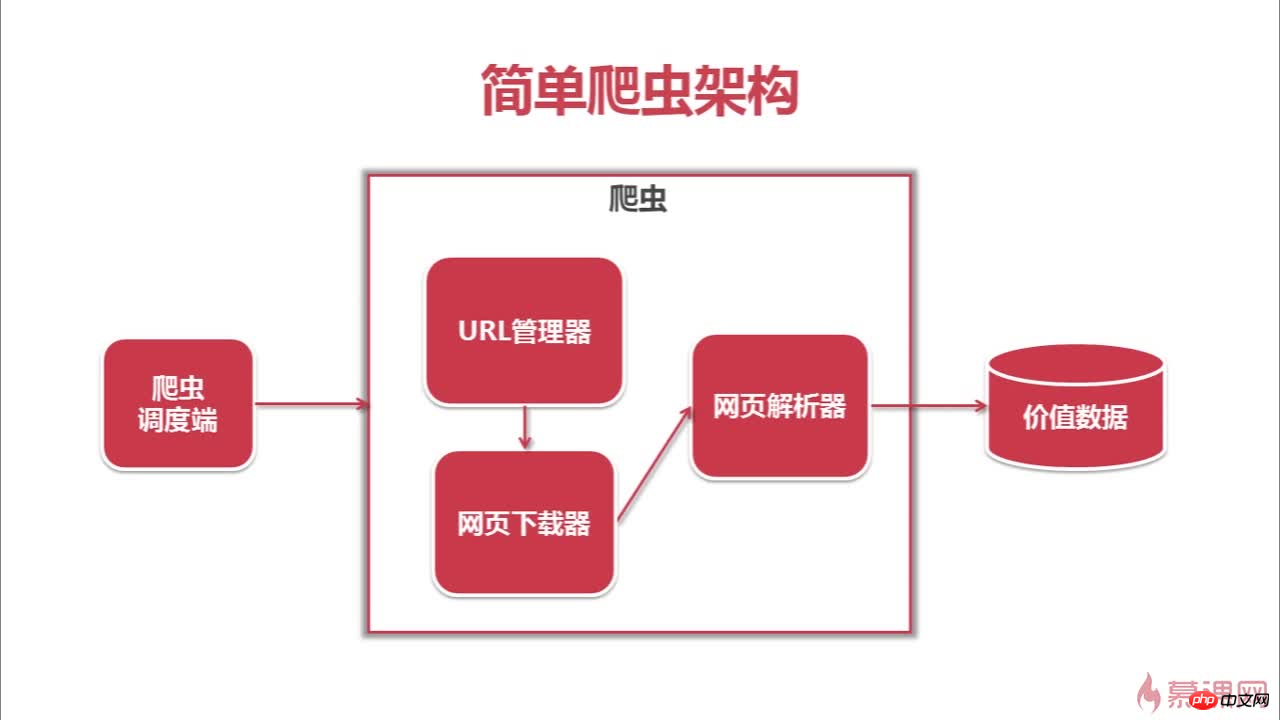
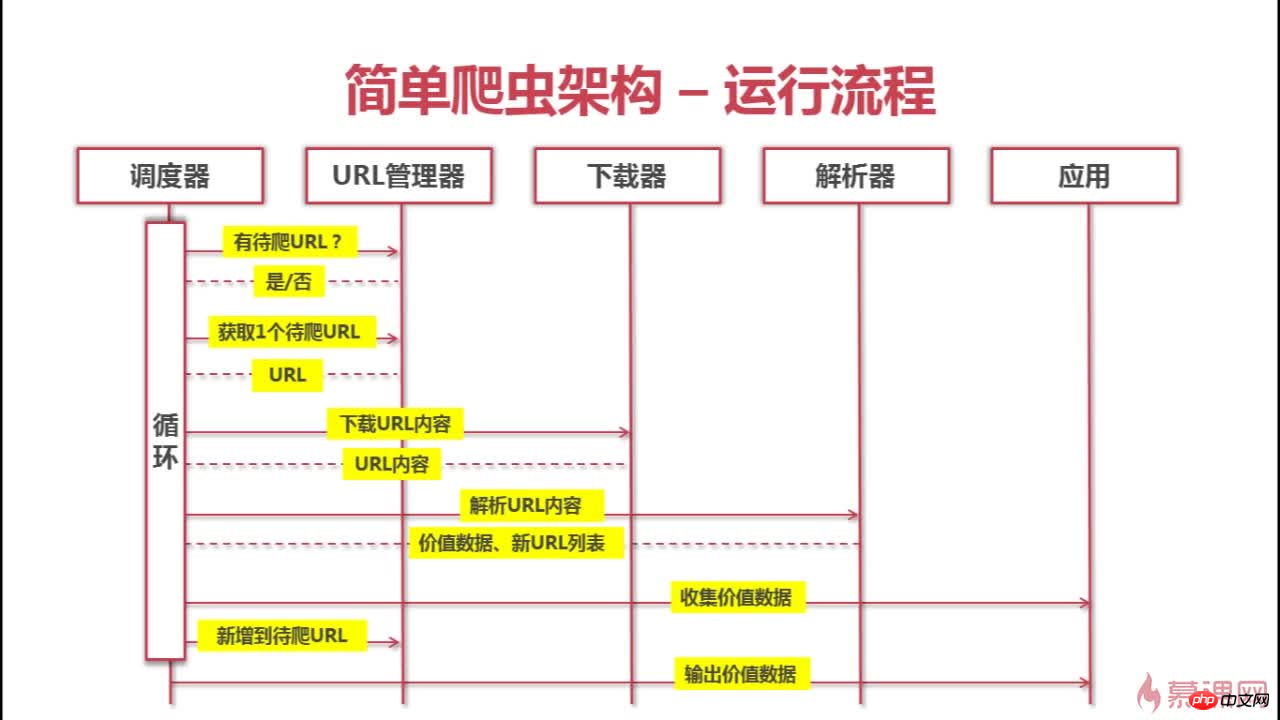
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



