
Répertoire de cet article :
4.1 Composants du système de fichiers
4.2 La structure complète du système de fichiers
4.3 Bloc de données
Bases de l'inode 4.4
Inode 4.5 en profondeur
4.6 Principes des opérations sur les fichiers dans un système de fichiers unique
4.7 Association de systèmes multi-fichiers
4.8 Fonction de journalisation du système de fichiers ext3
4.9 Système de fichiers ext4
4.10 ext Inconvénients du système de fichiers de classe
4.11 Système de fichiers virtuel VFS
Partitionnez le disque et la partition divise physiquement le disque en cylindres. Après avoir divisé la partition, vous devez la formater puis la monter avant de pouvoir l'utiliser (les autres méthodes ne sont pas prises en compte). Le processus de formatage d'une partition consiste en fait à créer un système de fichiers.
Il existe de nombreux types de systèmes de fichiers, tels que ext2/ext3/ext4 utilisé par défaut sur CentOS 5 et CentOS 6, xfs utilisé par défaut sur CentOS 7, NTFS sur Windows, système de fichiers de type CD ISO9660, Système de fichiers hybride HFS sur MAC, système de fichiers réseau NFS, btrfs développé par Oracle et FAT/FAT32 à l'ancienne, etc.
Cet article présentera le système de fichiers de la famille ext de manière très complète et détaillée. Il existe ext2/ext3/ext4. Ext3 est une version améliorée d'ext2 avec des journaux qui ont apporté de nombreuses améliorations par rapport à ext3. Bien que les systèmes de fichiers tels que xfs/btrfs soient différents, ils ne diffèrent que par leurs méthodes d'implémentation, ainsi que par leurs propres caractéristiques.
Les IO de lecture et d'écriture du disque dur sont un secteur 512 à la fois Octets. Si vous souhaitez lire et écrire un grand nombre de fichiers, utiliser des secteurs comme unités sera certainement très lent et consommera des performances. Par conséquent, Linux utilise le « bloc » comme unité de lecture et d'écriture via le système de fichiers. contrôle. Sur les systèmes de fichiers actuels, la taille des blocs est généralement de 1 024 octets (1 Ko) ou 2 048 octets (2 Ko) ou 4 096 octets (4 Ko). Par exemple, lorsqu'un ou plusieurs blocs doivent être lus, le gestionnaire d'E/S du système de fichiers informe le contrôleur de disque quels blocs de données doivent être lus. Le contrôleur de disque dur lit ces blocs par secteurs, puis transfère ces secteurs via le. contrôleur de disque dur. Les données sont réassemblées et renvoyées à l’ordinateur.
L'émergence du bloc améliore considérablement les performances de lecture et d'écriture au niveau du système de fichiers et réduit considérablement la fragmentation. Mais son effet secondaire est qu’il peut entraîner une perte d’espace. Étant donné que le système de fichiers utilise des blocs comme unités de lecture et d'écriture, même si le fichier stocké ne fait que 1 Ko, il occupera un bloc et l'espace restant sera complètement gaspillé. Pour certains besoins professionnels, un grand nombre de petits fichiers peuvent être stockés, ce qui gaspillera beaucoup d'espace.
Bien qu'il présente des inconvénients, ses avantages sont assez évidents à l'ère actuelle de capacité de disque dur bon marché et de recherche de performances, l'utilisation du bloc est un must.
Que se passera-t-il si un fichier stocké prend un grand nombre de lectures de blocs ? Si la taille du bloc est de 1 Ko, le simple stockage d'un fichier de 10 Mo nécessite 10 240 blocs, et ces blocs sont susceptibles d'être discontinus dans leur emplacement (non adjacents). Lors de la lecture du fichier, devons-nous analyser l'intégralité du fichier d'avant en arrière ? du système de fichiers, puis découvrir quels blocs appartiennent à ce fichier ? Évidemment, vous ne devriez pas faire cela, car c'est trop lent et idiot. Pensez-y encore, lire un fichier qui n'occupe qu'un seul bloc, est-ce fini après avoir lu un seul bloc ? Non, il analyse toujours tous les blocs de l'ensemble du système de fichiers, car il ne sait pas quand il est analysé, et il ne sait pas si le fichier est complet après l'analyse et n'a pas besoin d'analyser d'autres blocs.
De plus, chaque fichier possède des attributs (tels que les autorisations, la taille, l'horodatage, etc.). Où sont stockées les métadonnées de ces classes d'attributs ? Se pourrait-il que la partie données du fichier soit également stockée sous forme de blocs ? Si un fichier occupe plusieurs blocs, chaque bloc appartenant au fichier doit-il stocker des métadonnées de fichier ? Mais si le système de fichiers ne stocke pas de métadonnées dans chaque bloc, comment peut-il savoir si un certain bloc appartient au fichier ? Mais évidemment, stocker une copie des métadonnées dans chaque bloc de données est une perte d’espace.
Les concepteurs de systèmes de fichiers savent certainement que cette méthode de stockage n'est pas idéale, ils doivent donc optimiser la méthode de stockage. Comment optimiser ? La solution à ce problème similaire consiste à utiliser un index pour trouver les données correspondantes en parcourant l'index, et l'index peut stocker une partie des données.
Dans le système de fichiers, la technologie d'indexation est incarnée sous la forme d'un nœud d'index. Une partie des données stockées sur le nœud d'index sont les métadonnées d'attribut du fichier et d'autres petites quantités d'informations. D'une manière générale, l'espace occupé par un index est beaucoup plus petit que celui des données du fichier qu'il indexe. Son analyse est beaucoup plus rapide que l'analyse de l'intégralité des données, sinon l'index n'a aucune signification. Cela résout tous les problèmes précédents.
Dans la terminologie des systèmes de fichiers, un nœud d'index est appelé un inode. Les informations de métadonnées telles que le numéro d'inode, le type de fichier, les autorisations, le propriétaire du fichier, la taille, l'horodatage, etc. sont stockées dans l'inode. Le plus important est que le pointeur vers le bloc appartenant au fichier soit également stocké, de sorte que lors de la lecture. l'inode, vous pouvez trouver le bloc appartenant au fichier, puis lire ces blocs et obtenir les données du fichier. Puisqu'une sorte de pointeur sera introduit plus tard, pour faciliter la dénomination et la distinction, pour le moment, le pointeur pointant vers le bloc de données de fichier dans cet enregistrement d'inode est appelé un pointeur de bloc.
Généralement, la taille de l'inode est de 128 octets ou 256 octets, ce qui est beaucoup plus petit que les données du fichier calculées en Mo ou en Go. Cependant, vous devez également savoir que la taille d'un fichier peut être plus petite que l'inode. taille, par exemple, uniquement Un fichier occupant 1 octet.
Lors du stockage des données sur le disque dur, le système de fichiers doit savoir quels blocs sont libres et quels blocs sont occupés. La méthode la plus stupide est bien sûr de scanner d'avant en arrière, de stocker une partie du bloc libre lorsqu'il le rencontre et de continuer à scanner jusqu'à ce que toutes les données soient stockées.
Bien sûr, vous pouvez également envisager d'utiliser des index comme méthode d'optimisation, mais un système de fichiers 1G a un total de blocs de 1 Ko de 1024*1024=1048576. Ce n'est que 1G. Et s'il s'agit de 100G, 500G. ou même plus ? Le nombre et l'espace occupés par la simple utilisation des index seront également énormes. À ce moment-là, une méthode d'optimisation de niveau supérieur apparaît : l'utilisation de bitmaps en bloc (les bitmaps sont appelés bmaps).
Le bitmap utilise uniquement 0 et 1 pour identifier si le bloc correspondant est libre ou occupé. Les positions de 0 et 1 dans le bitmap correspondent à la position du bloc. le deuxième chiffre des unités marque le deuxième bloc, et ainsi de suite jusqu'à ce que tous les blocs soient marqués.
Considérez pourquoi les bitmaps en bloc sont plus optimaux. Il y a 8 bits dans 1 octet dans le bitmap, qui peuvent identifier 8 blocs. Pour un système de fichiers avec une taille de bloc de 1 Ko et une capacité de 1 Go, le nombre de blocs est de 1024*1024, donc 1024*1024 bits sont utilisés dans le bitmap, soit un total de 1024*1024/8=131072 octets=128 Ko, qui est 1G. Le fichier n'a besoin que de 128 blocs sous forme de bitmaps pour compléter la correspondance individuelle. En scannant plus de 100 blocs, vous pouvez savoir quels blocs sont gratuits et la vitesse est grandement améliorée.
Mais veuillez noter que l'optimisation bmap vise l'optimisation de l'écriture, car seule l'écriture nécessite de trouver le bloc libre et d'allouer le bloc libre. Pour la lecture, tant que l'emplacement du bloc est trouvé via l'inode, le CPU peut calculer rapidement l'adresse du bloc sur le disque physique. La vitesse de calcul du CPU est extrêmement rapide. presque négligeable, donc la vitesse de lecture est fondamentalement On pense qu'elle est affectée par les performances du disque dur lui-même et n'a rien à voir avec le système de fichiers.
Bien que bmap ait grandement optimisé l'analyse, il a toujours son goulot d'étranglement : et si le système de fichiers faisait 100 Go ? Un système de fichiers 100G utilise 128*100=12800 blocs de 1 Ko, ce qui occupe 12,5 Mo d'espace. Imaginez simplement qu'il faudra un certain temps pour analyser complètement 12 800 blocs susceptibles d'être discontinus. Bien que ce soit rapide, il ne peut pas supporter l'énorme surcharge liée à l'analyse à chaque fois qu'un fichier est stocké.
Il faut donc l'optimiser à nouveau. Comment optimiser ? En bref, le système de fichiers est divisé en groupes de blocs. L'introduction des groupes de blocs sera donnée plus tard.
Passons en revue les informations relatives aux inodes : l'inode stocke le numéro d'inode, les métadonnées d'attribut de fichier et le pointeur vers le bloc occupé par le fichier ; chaque inode occupe 128 mots ; section ou 256 octets.
Maintenant, il y a un autre problème. Il peut y avoir d'innombrables fichiers dans un système de fichiers, et chaque fichier correspond à un inode de seulement 128 octets doit-il occuper un bloc séparé pour le stockage ? C'est une telle perte d'espace.
Une meilleure façon est donc de combiner plusieurs inodes et de les stocker dans un bloc. Pour un inode de 128 octets, un bloc stocke 8 inodes. Pour un inode de 256 octets, un bloc stocke 4 inodes. Cela garantit que chaque bloc stockant un inode n'est pas gaspillé.
Sur le système de fichiers ext, ces blocs qui stockent physiquement les inodes sont combinés pour former logiquement une table d'inodes pour enregistrer tous les inodes.
Par exemple, chaque famille doit enregistrer les informations d'enregistrement du ménage auprès du commissariat de police. L'enregistrement du ménage peut être utilisé pour connaître l'adresse du domicile, et le commissariat de chaque ville ou rue intègre tous les enregistrements de ménage dans la ville ou. rue Lorsque vous souhaitez trouver l'adresse d'un certain foyer, vous pouvez la trouver rapidement au poste de police. La table des inodes est le commissariat de police ici. Son contenu est présenté ci-dessous.
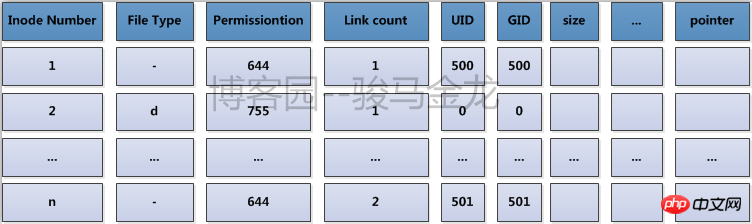
En fait, une fois le système de fichiers créé, tous les numéros d'inode ont été alloués et enregistrés dans la table des inodes, sauf que la ligne où le numéro d'inode est utilisé est Là contient également des informations de métadonnées sur les attributs de fichier et des informations sur l'emplacement des blocs, et le numéro d'inode inutilisé n'a qu'un numéro d'inode et aucune autre information.
Si vous y réfléchissez attentivement, vous constaterez qu'un système de fichiers volumineux occupera toujours un grand nombre de blocs pour stocker les inodes. Cela nécessite également beaucoup de temps système pour trouver l'un des enregistrements d'inodes, même si. ils ont été formés. Une table logique, mais elle ne peut pas gérer une table trop grande et contenant trop d'enregistrements. Ainsi, la façon de trouver rapidement l'inode doit également être optimisée. La méthode d'optimisation consiste à diviser les blocs du système de fichiers en groupes. Chaque groupe contient la plage de la table des inodes, le bmap, etc.
Comme mentionné précédemment, bmap est un bitmap de bloc, qui est utilisé pour identifier quels blocs du système de fichiers sont libres et quels blocs sont occupés.
Il en va de même pour les inodes. Lors du stockage de fichiers (tout sous Linux est un fichier), vous devez lui attribuer un numéro d'inode. Cependant, après le formatage et la création du système de fichiers, tous les numéros d'inodes sont prédéfinis et stockés dans la table des inodes. Une question se pose donc : quel numéro d'inode doit être attribué au fichier ? Comment savoir si un certain numéro d'inode a été attribué ?
Puisqu'il s'agit de "si il est occupé", utiliser un bitmap est la meilleure solution, tout comme bmap enregistre l'occupation du bloc. Le bitmap qui identifie si le numéro d'inode est alloué est appelé inodemap ou imap en abrégé. A ce stade, pour attribuer un numéro d'inode à un fichier, il suffit de scanner l'imap pour savoir quel numéro d'inode est libre.
imap a les mêmes problèmes qui doivent être résolus comme bmap et inode table : si le système de fichiers est relativement volumineux, imap lui-même sera très volumineux, et chaque fois qu'un fichier est stocké, il doit être analysé, ce qui entraînera une efficacité insuffisante. De même, la méthode d'optimisation consiste à diviser les blocs occupés par le système de fichiers en groupes de blocs, et chaque groupe de blocs a sa propre plage imap.
La méthode d'optimisation mentionnée ci-dessus consiste à diviser les blocs occupés par le système de fichiers en groupes de blocs pour résoudre le problème que bmap, inode table et imap sont trop grande. Grande question.
La division au niveau physique consiste à diviser le disque en plusieurs partitions basées sur des cylindres, c'est-à-dire plusieurs systèmes de fichiers ; la division au niveau logique consiste à diviser le système de fichiers en groupes de blocs. Chaque système de fichiers contient plusieurs groupes de blocs, et chaque groupe de blocs contient plusieurs zones de métadonnées et zones de données : la zone de métadonnées est la zone où sont stockés bmap, table d'inodes, imap, etc. . Notez que les groupes de blocs sont un concept logique, ils ne sont donc pas réellement divisés en colonnes, secteurs, pistes, etc. sur le disque.
Les groupes de blocs ont été divisés après la création du système de fichiers, c'est-à-dire les blocs occupés par des informations telles que la zone de métadonnées bmap, la table des inodes Et imap Et les blocs occupés par la zone de données ont été divisés. Alors, comment le système de fichiers sait-il combien de blocs contient une zone de métadonnées de bloc et combien de blocs contient la zone de données ?
Il suffit de déterminer une seule donnée - la taille de chaque bloc, puis de calculer comment diviser le groupe de blocs en fonction de la norme selon laquelle bmap ne peut occuper qu'un seul bloc complet bloc. Si le système de fichiers est très petit et que tous les bmaps ne peuvent pas occuper un bloc au total, alors le bloc bmap ne peut être que libéré.
La taille de chaque bloc peut être spécifiée manuellement lors de la création du système de fichiers, et il existe une valeur par défaut si elle n'est pas spécifiée.
Si la taille actuelle du bloc est de 1 Ko, un bmap qui occupe complètement un bloc peut identifier 1024*8 = 8192 blocs (bien sûr, ces 8192 blocs représentent un total de 8192 zones de données et zones de métadonnées, car les métadonnées zone Le bloc alloué doit également être identifié par bmap). Chaque bloc fait 1 Ko et chaque groupe de blocs fait 8 192 Ko ou 8 Mo. Pour créer un système de fichiers 1G, vous devez diviser 1024/8 = 128 groupes de blocs. Et s'il s'agit d'un système de fichiers 1,1G ? 128+12,8=128+13=141 groupes de blocs.
Le nombre de blocs dans chaque groupe a été divisé, mais combien de numéros d'inodes sont définis pour chaque groupe ? Combien de blocs la table des inodes occupe-t-elle ? Cela doit être déterminé par le système, car l'indicateur décrivant "combien de blocs dans la zone de données se voient attribuer un numéro d'inode" nous est inconnu par défaut. Bien entendu, cet indicateur ou pourcentage peut également être spécifié manuellement lors de la création d'un fichier. système. Voir "profondeur d'inode" ci-dessous.
En utilisant dumpe2fs, vous pouvez afficher toutes les informations du système de fichiers de la classe ext. Bien sûr, bmap corrige un bloc pour chaque groupe de blocs et n'a pas besoin d'être affiché. imap est plus petit que bmap, il n'en prend donc que 1. bloc et n’a pas besoin d’être affiché.
L'image ci-dessous montre une partie des informations d'un système de fichiers. Derrière ces informations se trouvent les informations de chaque groupe de blocs.
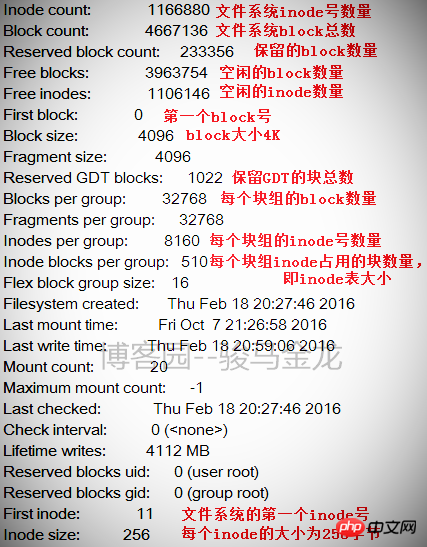
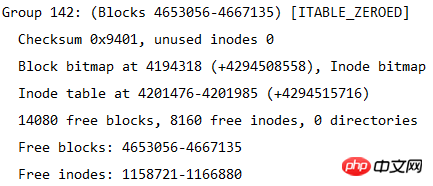
La taille du système de fichiers peut être calculée à partir de ce tableau. Le système de fichiers a un total de 4667136 blocs, et chaque taille de bloc est de 4K, donc la taille du système de fichiers. est 4667136*4/1024/1024=17,8 Go.
Vous pouvez également calculer combien de groupes de blocs sont divisés, car le nombre de blocs dans chaque groupe de blocs est de 32 768, donc le nombre de groupes de blocs est de 4667136/32768 = 142,4, soit 143 groupes de blocs. Puisque les groupes de blocs sont numérotés à partir de 0, le dernier numéro de groupe de blocs est le groupe 142. Comme le montre la figure ci-dessous, vous trouverez les informations du dernier groupe de blocs.
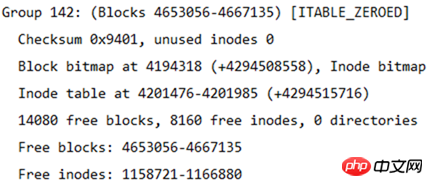
Mettez le bmap, la table d'inodes, l'imap et la zone de données décrit ci-dessus Les concepts de blocs et de groupes de blocs sont combinés pour former un système de fichiers. Bien entendu, il ne s'agit pas d'un système de fichiers complet. Le système de fichiers complet est présenté ci-dessous.
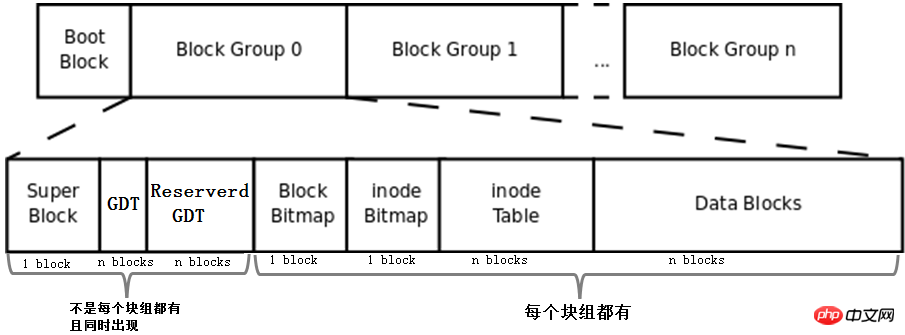
Tout d'abord, les concepts de Boot Block, Super Block, GDT et Reserve GDT sont ajoutés à cette image. Ils seront présentés séparément ci-dessous.
Ensuite, le chiffre indique le nombre de blocs occupés par chaque partie du groupe de blocs, à l'exception du superbloc, du bmap et de l'imap, qui peuvent être déterminés comme occupant 1 bloc, les autres parties ne peuvent pas déterminer combien. blocs qu’ils occupent.
Enfin, la figure indique que Superblock, GDT et Reserved GDT apparaissent en même temps et n'existent pas nécessairement dans chaque groupe de blocs. Elle indique également que bmap, imap, table d'inodes et blocs de données sont dans chaque bloc. groupe.
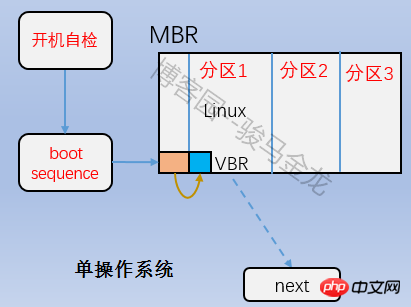
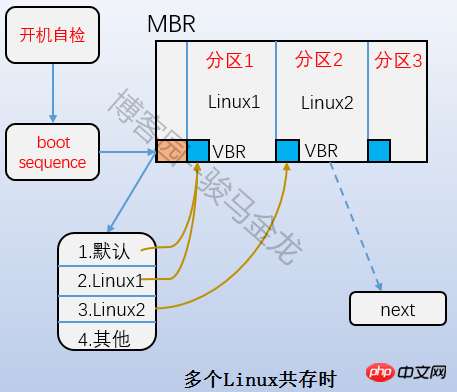
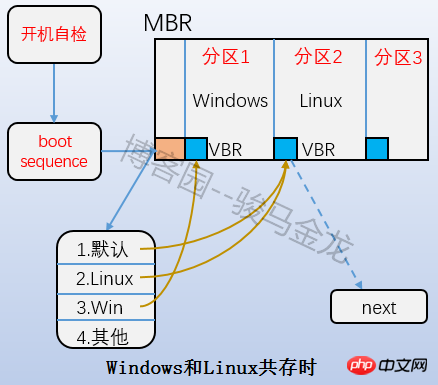
est la partie Boot Block dans la figure ci-dessus, également appelée secteur de démarrage. Il est situé dans le premier bloc de la partition et occupe 1 024 octets. Toutes les partitions ne disposent pas de ce secteur de démarrage. Le chargeur de démarrage y est également stocké. Ce chargeur de démarrage devient VBR. Il existe une relation échelonnée entre le chargeur de démarrage ici et le chargeur de démarrage sur le mbr. Lors du démarrage, chargez d'abord le chargeur de démarrage dans le mbr, puis localisez le secteur de démarrage de la partition où se trouve le système d'exploitation pour charger le chargeur de démarrage ici. S'il existe plusieurs systèmes, après avoir chargé le chargeur de démarrage dans le mbr, le menu du système d'exploitation sera répertorié et chaque système d'exploitation du menu pointe vers le secteur de démarrage de la partition où il se trouve. La relation entre eux est illustrée dans la figure ci-dessous.
Puisqu'un système de fichiers est divisé en plusieurs groupes de blocs, alors comment le système de fichiers sait-il combien de groupes de blocs sont divisés ? Combien de blocs, combien de numéros d'inodes et autres informations chaque groupe de blocs possède-t-il ? De plus, les informations d'attribut du système de fichiers lui-même, telles que divers horodatages, le nombre total de blocs et le nombre de blocs libres, le nombre total et le nombre d'inodes libres, si le système de fichiers actuel est normal, lorsqu'il est auto- un test est requis, etc., où sont-ils stockés ?
Il ne fait aucun doute que ces informations doivent être stockées dans le bloc. Le stockage de ces informations occupe 1 024 Ko, un bloc est donc également requis. Ce bloc est appelé superbloc et son numéro de bloc peut être 0 ou 1. Si la taille du bloc est de 1024 Ko, le bloc de démarrage occupe exactement un bloc. Le numéro de bloc est 0, donc le numéro du superbloc est 1 si la taille du bloc est supérieure à 1024 Ko, le bloc de démarrage et le super bloc sont co- situé dans un bloc. Ce numéro de bloc est 0. En bref, les positions de début et de fin du superbloc sont les deuxièmes 1024 (1024-2047) octets.
Ce que vous utilisez la commande df pour lire, c'est le superbloc de chaque système de fichiers, ses statistiques sont donc très rapides. Au contraire, utiliser la commande du pour visualiser l'espace utilisé d'un répertoire plus grand est très lent car il est inévitable de parcourir tous les fichiers du répertoire entier.
[root@xuexi ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on/dev/sda3 ext4 18G 1.7G 15G 11% /tmpfs tmpfs 491M 0 491M 0% /dev/shm/dev/sda1 ext4 190M 32M 149M 18% /boot
Le superbloc est crucial pour le système de fichiers. La perte ou l'endommagement du superbloc entraînera certainement des dommages au système de fichiers. Par conséquent, l'ancien système de fichiers sauvegarde le super bloc dans chaque groupe de blocs, mais c'est une perte d'espace, donc le système de fichiers ext2 enregistre le super bloc uniquement dans les groupes de blocs 0, 1 et 3, 5 et 7 groupes de blocs de puissance. . Bloquer les informations, telles que Group9, Group25, etc. Bien que de nombreux superblocs soient enregistrés, le système de fichiers utilise uniquement les informations de superbloc du premier groupe de blocs, Groupe0, pour obtenir les attributs du système de fichiers. Ce n'est que lorsque le superbloc du Groupe0 est endommagé ou perdu qu'il trouvera le superbloc de sauvegarde suivant et le copiera. Group0. pour restaurer le système de fichiers.
L'image ci-dessous montre les informations de superbloc d'un système de fichiers ext4. Tous les systèmes de fichiers de la famille ext peuvent être obtenus en utilisant dumpe2fs -h.

Étant donné que le système de fichiers est divisé en groupes de blocs, les informations et les éléments d'attribut de chaque groupe de blocs Où sont stockées les données ?
Chaque information de groupe de blocs dans le système de fichiers ext est décrite à l'aide de 32 octets. Ces 32 octets sont appelés descripteurs de groupe de blocs. Les descripteurs de groupe de blocs de tous les groupes de blocs forment la table de descripteurs de groupe de blocs GDT (table de descripteurs de groupe). .
Bien que chaque groupe de blocs nécessite un descripteur de groupe de blocs pour enregistrer les informations du groupe de blocs et les métadonnées d'attribut, tous les groupes de blocs ne stockent pas un descripteur de groupe de blocs. La méthode de stockage du système de fichiers ext consiste à former un GDT et à stocker le GDT dans certains groupes de blocs. Le groupe de blocs stockant le GDT est le même que le bloc stockant le superbloc et le superbloc de sauvegarde. un certain groupe de blocs en même temps dans un groupe de blocs.
Si un système de fichiers avec une taille de bloc de 4 Ko est divisé en 143 groupes de blocs et que chaque descripteur de groupe de blocs fait 32 octets, alors GDT nécessite 143*32=4576 octets, ou deux blocs, pour stocker. Les informations sur les groupes de blocs de tous les groupes de blocs sont enregistrées dans ces deux blocs GDT, et les GDT dans les groupes de blocs stockant GDT sont exactement les mêmes.
L'image ci-dessous est l'information d'un descripteur de groupe de blocs (obtenu via dumpe2fs).
Réservez GDT pour une expansion future du système de fichiers afin d'éviter un trop grand nombre de groupes de blocs après l'expansion, provoquant un blocage Le descripteur de groupe dépasse les blocs stockant actuellement le GDT. Gardez GDT et GDT apparaissent toujours en même temps, et bien sûr, ils apparaissent en même temps en tant que superbloc.
Par exemple, les 143 premiers groupes de blocs utilisent 2 blocs pour stocker GDT, mais à ce moment, le deuxième bloc a encore beaucoup d'espace libre. Lorsque la capacité est étendue dans une certaine mesure, les 2 blocs peuvent. n'enregistrez plus le descripteur de groupe de blocs, vous devez alors allouer un ou plusieurs blocs GDT réservés pour stocker les descripteurs de groupe de blocs excédentaires.
En raison du bloc GDT nouvellement ajouté, ce bloc GDT doit être ajouté à chaque groupe de blocs qui stocke GDT en même temps. Par conséquent, si le GDT et le GDT réservés sont stockés dans le même groupe de blocs, le réservé. GDT peut être directement transformé. Sauvegardez le GDT sans utiliser de méthodes de copie inefficaces sur chaque groupe de blocs contenant le GDT.
De même, le GDT nouvellement ajouté doit modifier les attributs du système de fichiers dans le superbloc de chaque groupe de blocs, donc combiner le superbloc et le GDT/GDT réservé peut améliorer l'efficacité.
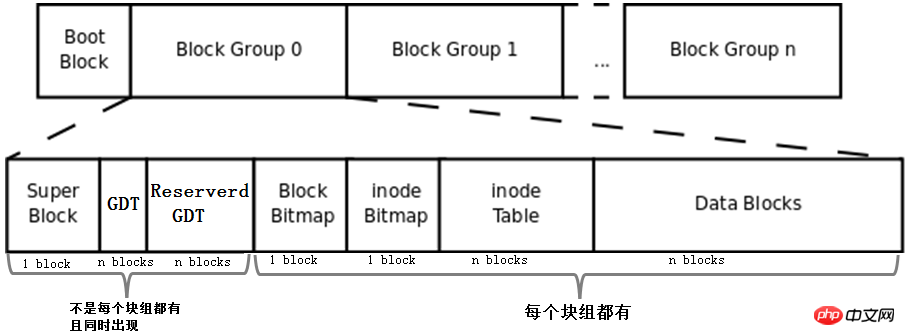
Comme le montre l'image ci-dessus, toutes les autres parties, à l'exception des blocs de données, ont été expliquées. Le bloc de données est un bloc qui stocke directement des données, mais en fait ce n'est pas si simple.
Le bloc occupé par les données est trouvé par le pointeur de bloc dans l'enregistrement inode correspondant au fichier. Le contenu stocké dans le bloc de données est différent selon les types de fichiers. Voici comment les différents types de fichiers sont stockés sous Linux.
Pour les fichiers normaux, les données du fichier sont normalement stockées dans des blocs de données.
Pour un répertoire, les noms de répertoire de tous les fichiers et sous-répertoires de premier niveau sous le répertoire sont stockés dans des blocs de données.
Le nom du fichier n'est pas stocké dans son propre inode, mais dans le bloc de données du répertoire dans lequel il se trouve.
Pour les liens symboliques, si le nom du chemin cible est court, il est enregistré directement dans l'inode pour une recherche plus rapide. Si le nom du chemin cible est long, un bloc de données est enregistré. alloué pour le sauvegarder.
Les fichiers spéciaux tels que les fichiers de périphérique, les FIFO et les sockets n'ont pas de blocs de données. Le numéro de périphérique majeur et le numéro de périphérique mineur du fichier de périphérique sont stockés dans l'inode.
Le stockage des fichiers normaux ne sera pas expliqué. Les méthodes de stockage des fichiers spéciaux seront expliquées ci-dessous.
Pour les fichiers répertoire, l'enregistrement inode stocke le numéro inode du répertoire, les métadonnées d'attribut du répertoire et le pointeur de bloc du fichier répertoire. Ici, aucune information n'est stockée sur le nom de fichier du répertoire.
La méthode de stockage de son bloc de données est celle indiquée dans la figure ci-dessous.
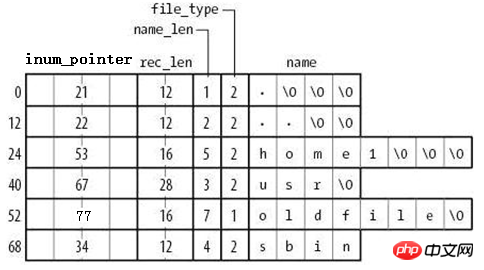
由图可知,在目录文件的数据块中存储了其下的文件名、目录名、目录本身的相对名称"."和上级目录的相对名称"..",还存储了指向inode table中这些文件名对应的inode号的指针(并非直接存储inode号码)、目录项长度rec_len、文件名长度name_len和文件类型file_type。注意到除了文件本身的inode记录了文件类型,其所在的目录的数据块也记录了文件类型。由于rec_len只能是4的倍数,所以需要使用"\0"来填充name_len不够凑满4倍数的部分。至于rec_len具体是什么,只需知道它是一种偏移即可。
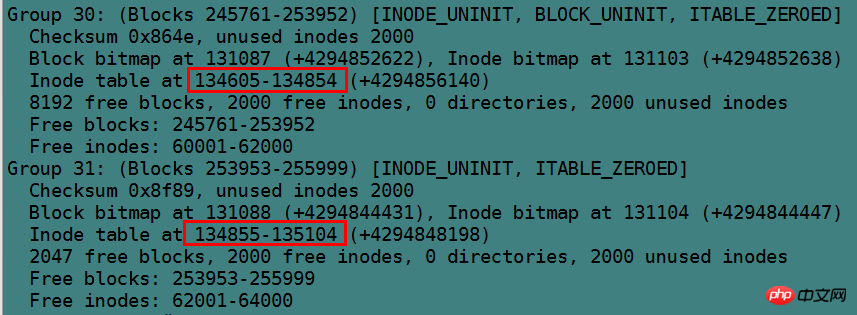
目录的data block中并没有直接存储目录中文件的inode号,它存储的是指向inode table中对应文件inode号的指针,暂且称之为inode指针(至此,已经知道了两种指针:一种是inode table中每个inode记录指向其对应data block的block指针,一个此处的inode指针)。一个很有说服力的例子,在目录只有读而没有执行权限的时候,使用"ls -l"是无法获取到其内文件inode号的,这就表明没有直接存储inode号。实际上,因为在创建文件系统的时候,inode号就已经全部划分好并在每个块组的inode table中存放好,inode table在块组中是有具体位置的,如果使用dumpe2fs查看文件系统,会发现每个块组的inode table占用的block数量是完全相同的,如下图是某分区上其中两个块组的信息,它们都占用249个block。
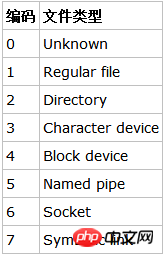
除了inode指针,目录的data block中还使用数字格式记录了文件类型,数字格式和文件类型的对应关系如下图。
注意到目录的data block中前两行存储的是目录本身的相对名称"."和上级目录的相对名称"..",它们实际上是目录本身的硬链接和上级目录的硬链接。硬链接的本质后面说明。
由此也就容易理解目录权限的特殊之处了。目录文件的读权限(r)和写权限(w),都是针对目录文件的数据块本身。由于目录文件内只有文件名、文件类型和inode指针,所以如果只有读权限,只能获取文件名和文件类型信息,无法获取其他信息,尽管目录的data block中也记录着文件的inode指针,但定位指针是需要x权限的,因为其它信息都储存在文件自身对应的inode中,而要读取文件inode信息需要有目录文件的执行权限通过inode指针定位到文件对应的inode记录上。以下是没有目录x权限时的查询状态,可以看到除了文件名和文件类型,其余的全是"?"。
[lisi4@xuexi tmp]$ ll -i d ls: cannot access d/hehe: Permission denied ls: cannot access d/haha: Permission denied total 0? d????????? ? ? ? ? ? haha? -????????? ? ? ? ? ? hehe
注意,xfs文件系统和ext文件系统不一样,它连文件类型都无法获取。
符号链接即为软链接,类似于Windows操作系统中的快捷方式,它的作用是指向原文件或目录。
软链接之所以也被称为特殊文件的原因是:它一般情况下不占用data block,仅仅通过它对应的inode记录就能将其信息描述完成;符号链接的大小是其指向目标路径占用的字符个数,例如某个符号链接的指向方式为"rmt --> ../sbin/rmt",则其文件大小为11字节;只有当符号链接指向的目标的路径名较长(60个字节)时文件系统才会划分一个data block给它;它的权限如何也不重要,因它只是一个指向原文件的"工具",最终决定是否能读写执行的权限由原文件决定,所以很可能ls -l查看到的符号链接权限为777。
注意,软链接的block指针存储的是目标文件名。也就是说,链接文件的一切都依赖于其目标文件名。这就解释了为什么/mnt的软链接/tmp/mnt在/mnt挂载文件系统后,通过软链接就能进入/mnt所挂载的文件系统。究其原因,还是因为其目标文件名"/mnt"并没有改变。
例如以下筛选出了/etc/下的符号链接,注意观察它们的权限和它们占用的空间大小。
[root@xuexi ~]# ll /etc/ | grep '^l'lrwxrwxrwx. 1 root root 56 Feb 18 2016 favicon.png -> /usr/share/icons/hicolor/16x16/apps/system-logo-icon.png lrwxrwxrwx. 1 root root 22 Feb 18 2016 grub.conf -> ../boot/grub/grub.conf lrwxrwxrwx. 1 root root 11 Feb 18 2016 init.d -> rc.d/init.d lrwxrwxrwx. 1 root root 7 Feb 18 2016 rc -> rc.d/rc lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc0.d -> rc.d/rc0.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc1.d -> rc.d/rc1.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc2.d -> rc.d/rc2.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc3.d -> rc.d/rc3.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc4.d -> rc.d/rc4.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc5.d -> rc.d/rc5.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc6.d -> rc.d/rc6.d lrwxrwxrwx. 1 root root 13 Feb 18 2016 rc.local -> rc.d/rc.local lrwxrwxrwx. 1 root root 15 Feb 18 2016 rc.sysinit -> rc.d/rc.sysinit lrwxrwxrwx. 1 root root 14 Feb 18 2016 redhat-release -> centos-release lrwxrwxrwx. 1 root root 11 Apr 10 2016 rmt -> ../sbin/rmt lrwxrwxrwx. 1 root root 14 Feb 18 2016 system-release -> centos-release
关于这3种文件类型的文件只需要通过inode就能完全保存它们的信息,它们不占用任何数据块,所以它们是特殊文件。
设备文件的主设备号和次设备号也保存在inode中。以下是/dev/下的部分设备信息。注意到它们的第5列和第6列信息,它们分别是主设备号和次设备号,主设备号标识每一种设备的类型,次设备号标识同种设备类型的不同编号;也注意到这些信息中没有大小的信息,因为设备文件不占用数据块所以没有大小的概念。
[root@xuexi ~]# ll /dev | tailcrw-rw---- 1 vcsa tty 7, 129 Oct 7 21:26 vcsa1 crw-rw---- 1 vcsa tty 7, 130 Oct 7 21:27 vcsa2 crw-rw---- 1 vcsa tty 7, 131 Oct 7 21:27 vcsa3 crw-rw---- 1 vcsa tty 7, 132 Oct 7 21:27 vcsa4 crw-rw---- 1 vcsa tty 7, 133 Oct 7 21:27 vcsa5 crw-rw---- 1 vcsa tty 7, 134 Oct 7 21:27 vcsa6 crw-rw---- 1 root root 10, 63 Oct 7 21:26 vga_arbiter crw------- 1 root root 10, 57 Oct 7 21:26 vmci crw-rw-rw- 1 root root 10, 56 Oct 7 21:27 vsock crw-rw-rw- 1 root root 1, 5 Oct 7 21:26 zero
每个文件都有一个inode,在将inode关联到文件后系统将通过inode号来识别文件,而不是文件名。并且访问文件时将先找到inode,通过inode中记录的block位置找到该文件。
虽然每个文件都有一个inode,但是存在一种可能:多个文件的inode相同,也就即inode号、元数据、block位置都相同,这是一种什么样的情况呢?能够想象这些inode相同的文件使用的都是同一条inode记录,所以代表的都是同一个文件,这些文件所在目录的data block中的inode指针目的地都是一样的,只不过各指针对应的文件名互不相同而已。这种inode相同的文件在Linux中被称为"硬链接"。
硬链接文件的inode都相同,每个文件都有一个"硬链接数"的属性,使用ls -l的第二列就是被硬链接数,它表示的就是该文件有几个硬链接。
[root@xuexi ~]# ls -l total 48drwxr-xr-x 5 root root 4096 Oct 15 18:07 700-rw-------. 1 root root 1082 Feb 18 2016 anaconda-ks.cfg-rw-r--r-- 1 root root 399 Apr 29 2016 Identity.pub-rw-r--r--. 1 root root 21783 Feb 18 2016 install.log-rw-r--r--. 1 root root 6240 Feb 18 2016 install.log.syslog
例如下图描述的是dir1目录中的文件name1及其硬链接dir2/name2,右边分别是它们的inode和datablock。这里也看出了硬链接文件之间唯一不同的就是其所在目录中的记录不同。注意下图中有一列Link Count就是标记硬链接数的属性。

每创建一个文件的硬链接,实质上是多一个指向该inode记录的inode指针,并且硬链接数加1。
删除文件的实质是删除该文件所在目录data block中的对应的inode指针,所以也是减少硬链接次数,由于block指针是存储在inode中的,所以不是真的删除数据,如果仍有其他指针指向该inode,那么该文件的block指针仍然是可用的。当硬链接次数为1时再删除文件就是真的删除文件了,此时inode记录中block指针也将被删除。
不能跨分区创建硬链接,因为不同文件系统的inode号可能会相同,如果允许创建硬链接,复制到另一个分区时inode可能会和此分区已使用的inode号冲突。
硬链接只能对文件创建,无法对目录创建硬链接。之所以无法对目录创建硬链接,是因为文件系统已经把每个目录的硬链接创建好了,它们就是相对路径中的"."和"..",分别标识当前目录的硬链接和上级目录的硬链接。每一个目录中都会包含这两个硬链接,它包含了两个信息:(1)一个没有子目录的目录文件的硬链接数是2,其一是目录本身,其二是".";(2)一个包含子目录的目录文件,其硬链接数是2+子目录数,因为每个子目录都关联一个父目录的硬链接".."。很多人在计算目录的硬链接数时认为由于包含了"."和"..",所以空目录的硬链接数是2,这是错误的,因为".."不是本目录的硬链接。另外,还有一个特殊的目录应该纳入考虑,即"/"目录,它自身是一个文件系统的入口,是自引用(下文中会解释自引用)的,所以"/"目录下的"."和".."的inode号相同,硬链接数除去其内的子目录后应该为3,但结果是2,不知为何?
[root@xuexi ~]# ln /tmp /mydataln: `/tmp': hard link not allowed for directory
为什么文件系统自己创建好了目录的硬链接就不允许人为创建呢?从"."和".."的用法上考虑,如果当前目录为/usr,我们可以使用"./local"来表示/usr/local,但是如果我们人为创建了/usr目录的硬链接/tmp/husr,难道我们也要使用"/tmp/husr/local"来表示/usr/local吗?这其实已经是软链接的作用了。若要将其认为是硬链接的功能,这必将导致硬链接维护的混乱。
不过,通过mount工具的"--bind"选项,可以将一个目录挂载到另一个目录下,实现伪"硬链接",它们的内容和inode号是完全相同的。
硬链接的创建方法:ln file_target link_name。
软链接就是字符链接,链接文件默认指的就是字符文件,使用"l"表示其类型。
软链接在功能上等价与Windows系统中的快捷方式,它指向原文件,原文件损坏或消失,软链接文件就损坏。可以认为软链接inode记录中的指针内容是目标路径的字符串。
创建方式:ln –s file_target softlink_name
查看软链接的值:readlink softlink_name
在设置软链接的时候,target虽然不要求是绝对路径,但建议给绝对路径。是否还记得软链接文件的大小?它是根据软链接所指向路径的字符数计算的,例如某个符号链接的指向方式为"rmt --> ../sbin/rmt",它的文件大小为11字节,也就是说只要建立了软链接后,软链接的指向路径是不会改变的,仍然是"../sbin/rmt"。如果此时移动软链接文件本身,它的指向是不会改变的,仍然是11个字符的"../sbin/rmt",但此时该软链接父目录下可能根本就不存在/sbin/rmt,也就是说此时该软链接是一个被破坏的软链接。
inode大小为128字节的倍数,最小为128字节。它有默认值大小,它的默认值由/etc/mke2fs.conf文件中指定。不同的文件系统默认值可能不同。
[root@xuexi ~]# cat /etc/mke2fs.conf
[defaults]
base_features = sparse_super,filetype,resize_inode,dir_index,ext_attr
enable_periodic_fsck = 1blocksize = 4096inode_size = 256inode_ratio = 16384[fs_types]
ext3 = {
features = has_journal
}
ext4 = {
features = has_journal,extent,huge_file,flex_bg,uninit_bg,dir_nlink,extra_isize
inode_size = 256}同样观察到这个文件中还记录了blocksize的默认值和inode分配比率inode_ratio。inode_ratio=16384表示每16384个字节即16KB就分配一个inode号,由于默认blocksize=4KB,所以每4个block就分配一个inode号。当然分配的这些inode号只是预分配,并不真的代表会全部使用,毕竟每个文件才会分配一个inode号。但是分配的inode自身会占用block,而且其自身大小256字节还不算小,所以inode号的浪费代表着空间的浪费。
既然知道了inode分配比率,就能计算出每个块组分配多少个inode号,也就能计算出inode table占用多少个block。
如果文件系统中大量存储电影等大文件,inode号就浪费很多,inode占用的空间也浪费很多。但是没办法,文件系统又不知道你这个文件系统是用来存什么样的数据,多大的数据,多少数据。
当然inodesize、inode分配比例、blocksize都可以在创建文件系统的时候人为指定。
Ext预留了一些inode做特殊特性使用,如下:某些可能并非总是准确,具体的inode号对应什么文件可以使用"find / -inum NUM"查看。
Ext4的特殊inode
Inode号 用途
0 不存在0号inode
1 虚拟文件系统,如/proc和/sys
2 根目录
3 ACL索引
4 ACL数据
5 Boot loader
6 未删除的目录
7 预留的块组描述符inode
8 日志inode
11 第一个非预留的inode,通常是lost+found目录
所以在ext4文件系统的dumpe2fs信息中,能观察到fisrt inode号可能为11也可能为12。
并且注意到"/"的inode号为2,这个特性在文件访问时会用上。
需要注意的是,每个文件系统都会分配自己的inode号,不同文件系统之间是可能会出现使用相同inode号文件的。例如:
[root@xuexi ~]# find / -ignore_readdir_race -inum 2 -ls 2 4 dr-xr-xr-x 22 root root 4096 Jun 9 09:56 / 2 2 dr-xr-xr-x 5 root root 1024 Feb 25 11:53 /boot 2 0 c--------- 1 root root Jun 7 02:13 /dev/pts/ptmx 2 0 -rw-r--r-- 1 root root 0 Jun 6 18:13 /proc/sys/fs/binfmt_misc/status 2 0 drwxr-xr-x 3 root root 0 Jun 6 18:13 /sys/fs
Comme le montrent les résultats, en plus du numéro d'inode racine étant 2, il existe également plusieurs fichiers dont le numéro d'inode est également 2. Ils appartiennent tous à des systèmes de fichiers indépendants, et certains sont des systèmes de fichiers virtuels, tels que /proc et /sys.
Comme mentionné précédemment, le pointeur de blocs est enregistré dans l'inode, mais le nombre de pointeurs pouvant être enregistrés dans un enregistrement d'inode est limitée, sinon la taille de l'inode (128 octets ou 256 octets) sera dépassée.
Dans les systèmes de fichiers ext2 et ext3, il ne peut y avoir que jusqu'à 15 pointeurs dans un inode, et chaque pointeur est représenté par i_block[n].
Les 12 premiers pointeurs i_block[0] vers i_block[11] sont des pointeurs d'adressage direct, chaque pointeur pointe vers un bloc dans la zone de données. Comme indiqué ci-dessous.
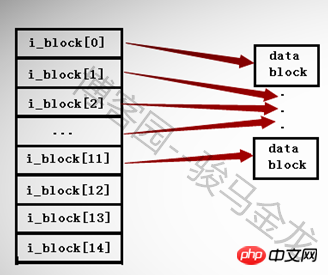
Le 13ème pointeur i_block[12] est un pointeur d'adressage indirect de premier niveau, qui pointe vers un bloc qui stocke toujours des pointeurs, c'est-à-dire i_block[13] -- > Bloc de pointeur --> bloc de données.
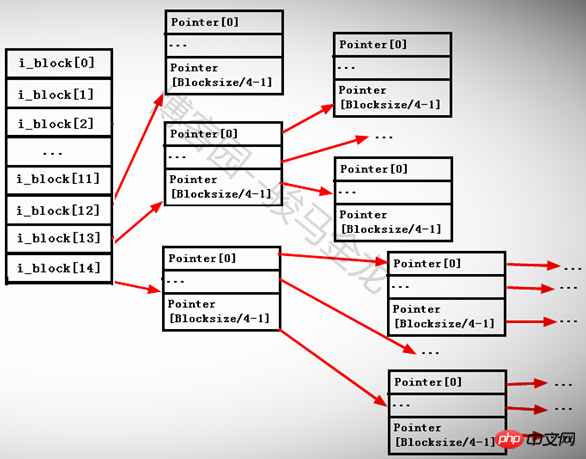
Le 14ème pointeur i_block[13] est un pointeur d'adressage indirect secondaire. Il pointe vers un bloc qui stocke toujours des pointeurs, mais les pointeurs de ce bloc continuent de pointer vers d'autres blocs qui stockent des pointeurs, c'est-à-dire i_block. [ 13] ---> Pointerblock1 --->
Le 15ème pointeur i_block[14] est un pointeur d'adressage indirect de troisième niveau. Il pointe vers un bloc qui stocke toujours des pointeurs. Il y a deux pointeurs pointant vers ce bloc de pointeur. Autrement dit, i_block[13] -->
Étant donné que la taille de chaque pointeur est de 4 octets, le nombre de pointeurs que chaque bloc de pointeur peut stocker est BlockSize/4byte. Par exemple, si la taille du bloc est de 4 Ko, alors un bloc peut stocker 4096/4=1024 pointeurs.
Comme indiqué ci-dessous.
Pourquoi les pointeurs indirects et directs sont-ils divisés ? Si les 15 pointeurs d'un inode sont des pointeurs directs et si la taille de chaque bloc est de 1 Ko, alors les 15 pointeurs ne peuvent pointer que vers 15 blocs, soit une taille de 15 Ko. Puisque chaque fichier correspond à un numéro d'inode, cela limite la taille. taille de chaque bloc. La taille maximale d'un fichier est de 15*1=15 Ko, ce qui est évidemment déraisonnable.
Si vous stockez un fichier de plus de 15 Ko mais pas trop, il occupera le pointeur indirect de premier niveau i_block[12]. À ce stade, le nombre de pointeurs pouvant être stockés est de 1024/4+. 12 = 268, donc 268 Ko peuvent être stockés dans le fichier.
Si vous stockez un fichier de plus de 268 Ko mais pas trop, il continuera à occuper le pointeur secondaire i_block[13]. À ce stade, le nombre de pointeurs pouvant être stockés est de [1024/4] ^2+1024/4+ 12=65804, il peut donc stocker des fichiers d'environ 65804 Ko=64 Mo.
Si le fichier stocké est supérieur à 64 Mo, continuez à utiliser le pointeur indirect à trois niveaux i_block[14], et le nombre de pointeurs stockés est [1024/4]^3+[1024/4] ^2+[1024/ 4]+12=16843020 pointeurs, il peut donc stocker des fichiers d'environ 16843020 Ko = 16 Go.
Et si blocksize=4KB ? Ensuite, la taille maximale du fichier pouvant être stocké est de ([4096/4]^3+[4096/4]^2+[4096/4]+12)*4/1024/1024/1024=environ 4T.
Bien entendu, ce qui est calculé de cette manière n'est pas nécessairement la taille maximale du fichier pouvant être stocké. Il est également soumis à une autre condition. Les calculs ici indiquent simplement comment un fichier volumineux est traité et alloué.
En fait, lorsque vous voyez les valeurs calculées ici, vous savez que l'efficacité d'accès de ext2 et ext3 pour les très gros fichiers est faible. Ils doivent vérifier trop de pointeurs, surtout lorsque la taille de bloc est de 4 Ko. . Ext4 a été optimisé pour ce point. Ext4 utilise la gestion des extensions pour remplacer le mappage de blocs d'ext2 et ext3, ce qui améliore considérablement l'efficacité et réduit la fragmentation.
Comment effectuer des opérations telles que la suppression, la copie, le renommage et le déplacement sous Linux Et ? Et comment le retrouver lorsque vous accédez au fichier ? En fait, tant que vous comprenez les différents termes introduits dans l’article précédent et leurs fonctions, il est facile de connaître les principes des opérations sur les fichiers.
Remarque : ce qui est expliqué dans cette section concerne le comportement sous un seul système de fichiers. Pour savoir comment utiliser plusieurs systèmes de fichiers, veuillez consulter la section suivante : Association de systèmes multi-fichiers.
Quelles étapes sont effectuées à l'intérieur du système lors de l'exécution de la commande "cat /var/log/messages" ? L'exécution réussie de cette commande implique des processus complexes tels que la recherche de la commande cat, l'évaluation des autorisations, ainsi que la recherche et l'évaluation des autorisations du fichier de messages. Ici, nous expliquons uniquement comment trouver le fichier /var/log/messages qui est répertorié et lié au contenu de cette section.
Recherchez les blocs où se trouve la table de descripteur de groupe de blocs du système de fichiers racine, lisez le GDT (déjà en mémoire) pour trouver le numéro de bloc de la table d'inodes.
Parce que GDT est toujours dans le même groupe de blocs que le superbloc, et que le superbloc est toujours dans le 1024ème au 2047ème octet de la partition, il est donc facile de connaître le premier Le groupe de blocs où se trouve GDT et les blocs que GDT occupe dans ce groupe de blocs.
En fait, GDT est déjà dans la mémoire. Lorsque le système est démarré, il sera monté dans le système de fichiers racine. Lors du montage, tous les GDT ont été mis en mémoire.
Localisez l'inode de la racine "/" dans le bloc de la table des inodes et trouvez le bloc de données pointé par "/".
Comme mentionné précédemment, le système de fichiers ext réserve certains numéros d'inode, parmi lesquels le numéro d'inode "/" est 2, de sorte que le fichier du répertoire racine peut être directement localisé en fonction sur le numéro d'inode du bloc de données.
Le nom du répertoire var et le pointeur vers l'inode du fichier du répertoire var sont enregistrés dans le bloc de données de "/", et l'enregistrement de l'inode est trouvé. est stocké dans l'enregistrement inode, donc le bloc de données du fichier répertoire var est trouvé.
Vous pouvez trouver l'enregistrement inode du répertoire var via le pointeur inode du répertoire var. Cependant, pendant le processus de positionnement du pointeur, vous devez également connaître le bloc. groupe et emplacement de l'enregistrement d'inode, donc GDT doit être lu De même, GDT a été mis en cache en mémoire.
Le nom du répertoire de journaux et son pointeur d'inode sont enregistrés dans le bloc de données de var. Grâce à ce pointeur, le groupe de blocs et la table d'inode où se trouve l'inode sont localisés. , et selon l'enregistrement inode trouve le bloc de données du journal.
Le nom du fichier de messages et le pointeur d'inode correspondant sont enregistrés dans le bloc de données du fichier de répertoire de journaux. Grâce à ce pointeur, le groupe de blocs et l'emplacement de. les inodes sont localisés. table inode et recherchez le bloc de données de messages basé sur l'enregistrement inode.
Lisez enfin le datablock correspondant aux messages.
C'est plus facile à comprendre après avoir simplifié la partie GDT des étapes ci-dessus. Comme suit : Recherchez GDT--> Recherchez l'inode de "/"--> Recherchez le bloc de données de /, lisez l'inode de var--> Trouvez le bloc de données de var, lisez l'inode de log-- > Rechercher les données du journal Le bloc lit l'inode des messages -> Rechercher les blocs de données des messages et les lire.
Notez qu'il s'agit d'une opération qui ne traverse pas le système de fichiers.
Les fichiers supprimés sont divisés en fichiers ordinaires et fichiers de répertoire Si vous connaissez les principes de suppression de ces deux types de fichiers, vous saurez comment supprimer d'autres types de fichiers spéciaux. .
Pour supprimer des fichiers ordinaires : recherchez l'inode et le bloc de données du fichier (recherchez-le selon la méthode de la section précédente) ; inconnu dans imap Utiliser ; marquer le numéro de bloc correspondant au bloc de données dans le bmap comme inutilisé ; supprimer la ligne d'enregistrement où se trouve le nom du fichier dans le bloc de données du répertoire où il se trouve. Si l'enregistrement est supprimé, le pointeur. à l'Inode sera perdu.
Pour supprimer des fichiers de répertoire : recherchez l'inode et le bloc de données de tous les fichiers, sous-répertoires et sous-fichiers du répertoire ; marquez ces numéros d'inode comme inutilisés dans imap ; modifiez les numéros d'inode occupés par ces fichiers dans bmap. le numéro est marqué comme inutilisé ; supprimez la ligne d'enregistrement où se trouve le nom du répertoire dans le bloc de données du répertoire parent du répertoire. Il convient de noter que la suppression des enregistrements dans le bloc de données du répertoire parent est la dernière étape. Si cette étape est effectuée à l'avance, une erreur de répertoire non vide sera signalée car des fichiers sont encore occupés dans le répertoire.
Le renommage des fichiers est divisé en renommage dans le même répertoire et renommage dans différents répertoires. Renommer dans différents répertoires est en fait le processus de déplacement de fichiers, voir ci-dessous.
L'action de renommer un fichier dans le même répertoire consiste uniquement à modifier le nom de fichier enregistré dans le bloc de données du répertoire, et n'est pas un processus de suppression et de reconstruction .
S'il y a un conflit de nom de fichier lors du changement de nom (le nom du fichier existe déjà dans le répertoire), il vous sera demandé si vous souhaitez l'écraser. Le processus d'écrasement consiste à écraser les enregistrements des fichiers en conflit dans le bloc de données du répertoire. Par exemple, il y a a.txt et a.log sous /tmp/. Si vous renommez a.txt en a.log, vous serez invité à écraser les enregistrements concernant a.log dans les données. Le bloc de /tmp sera écrasé. À ce moment, son pointeur pointe vers l'inode de a.txt.
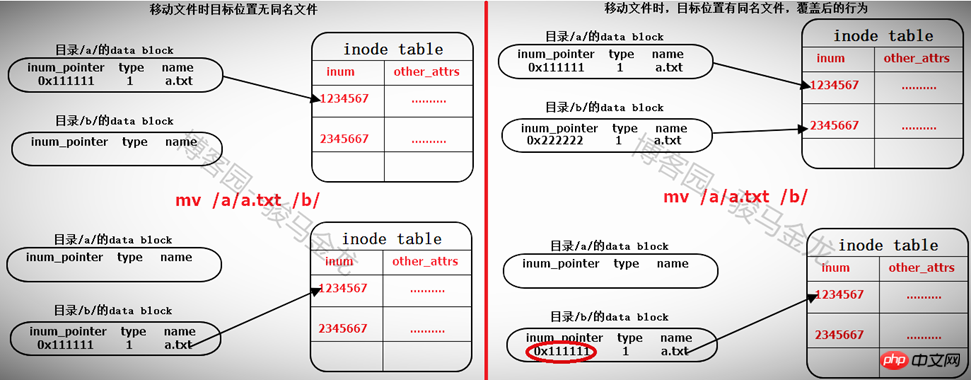
Déplacer des fichiers
Déplacer des fichiers sous le même système de fichiers modifie en fait le bloc de données du répertoire où se trouve la cible Le fichier est localisé. Ajoutez-y une ligne qui pointe vers le pointeur d'inode du fichier à déplacer dans la table d'inodes. S'il existe un fichier portant le même nom dans le chemin cible, vous serez invité à l'écraser. En fait, l'enregistrement du fichier en conflit dans le bloc de données du répertoire est écrasé, car le pointeur d'enregistrement d'inode du fichier du même nom est Overwrite, donc le bloc de données du fichier ne peut plus être trouvé, ce qui signifie que le fichier est marqué pour suppression (s’il existe plusieurs liens physiques, c’est une autre affaire).
Le déplacement de fichiers au sein d'un même système de fichiers est donc très rapide. Il ajoute ou écrase uniquement un enregistrement dans le bloc de données du répertoire où il se trouve. Par conséquent, lors du déplacement d’un fichier, le numéro d’inode du fichier ne changera pas.
Pour se déplacer dans différents systèmes de fichiers, cela équivaut à copier d'abord puis à supprimer. Voir ci-dessous.
对于文件存储
(1).读取GDT,找到各个(或部分)块组imap中未使用的inode号,并为待存储文件分配inode号;
(2).在inode table中完善该inode号所在行的记录;
(3).在目录的data block中添加一条该文件的相关记录;
(4).将数据填充到data block中。
注意,填充到data block中的时候会调用block分配器:一次分配4KB大小的block数量,当填充完4KB的data block后会继续调用block分配器分配4KB的block,然后循环直到填充完所有数据。也就是说,如果存储一个100M的文件需要调用block分配器100*1024/4=25600次。
另一方面,在block分配器分配block时,block分配器并不知道真正有多少block要分配,只是每次需要分配时就分配,在每存储一个data block前,就去bmap中标记一次该block已使用,它无法实现一次标记多个bmap位。这一点在ext4中进行了优化。
(5)填充完之后,去inode table中更新该文件inode记录中指向data block的寻址指针。
对于复制,完全就是另一种方式的存储文件。步骤和存储文件的步骤一样。
在单个文件系统中的文件操作和多文件系统中的操作有所不同。本文将对此做出非常详细的说明。
这里要明确的是,任何一个文件系统要在Linux上能正常使用,必须挂载在某个已经挂载好的文件系统中的某个目录下,例如/dev/cdrom挂载在/mnt上,/mnt目录本身是在"/"文件系统下的。而且任意文件系统的一级挂载点必须是在根文件系统的某个目录下,因为只有"/"是自引用的。这里要说明挂载点的级别和自引用的概念。
假如/dev/sdb1挂载在/mydata上,/dev/cdrom挂载在/mydata/cdrom上,那么/mydata就是一级挂载点,此时/mydata已经是文件系统/dev/sdb1的入口了,而/dev/cdrom所挂载的目录/mydata/cdrom是文件系统/dev/sdb1中的某个目录,那么/mydata/cdrom就是二级挂载点。一级挂载点必须在根文件系统下,所以可简述为:文件系统2挂载在文件系统1中的某个目录下,而文件系统1又挂载在根文件系统中的某个目录下。
再解释自引用。首先要说的是,自引用的只能是文件系统,而文件系统表现形式是一个目录,所以自引用是指该目录的data block中,"."和".."的记录中的inode指针都指向inode table中同一个inode记录,所以它们inode号是相同的,即互为硬链接。而根文件系统是唯一可以自引用的文件系统。
[root@xuexi /]# ll -ai /total 102 2 dr-xr-xr-x. 22 root root 4096 Jun 6 18:13 . 2 dr-xr-xr-x. 22 root root 4096 Jun 6 18:13 ..
由此也能解释cd /.和cd /..的结果都还是在根下,这是自引用最直接的表现形式。
[root@xuexi tmp]# cd /. [root@xuexi /]# [root@xuexi tmp]# cd /.. [root@xuexi /]#
但是有一个疑问,根目录下的"."和".."都是"/"目录的硬链接,所以除去根目录下目录数后的硬链接数位3,但实际却为2,不知道这是为何?
[root@server2 tmp]# a=$(ls -al / | grep "^d" |wc -l) [root@server2 tmp]# b=$(ls -l / | grep "^d" |wc -l) [root@server2 tmp]# echo $((a - b))2
挂载文件系统到某个目录下,例如"mount /dev/cdrom /mnt",挂载成功后/mnt目录中的文件全都暂时不可见了,且挂载后权限和所有者(如果指定允许普通用户挂载)等的都改变了,知道为什么吗?
下面就以通过"mount /dev/cdrom /mnt"为例,详细说明挂载过程中涉及的细节。
在将文件系统/dev/cdrom(此处暂且认为它是文件系统)挂载到挂载点/mnt之前,挂载点/mnt是根文件系统中的一个目录,"/"的data block中记录了/mnt的一些信息,其中包括inode指针inode_n,而在inode table中,/mnt对应的inode记录中又存储了block指针block_n,此时这两个指针还是普通的指针。
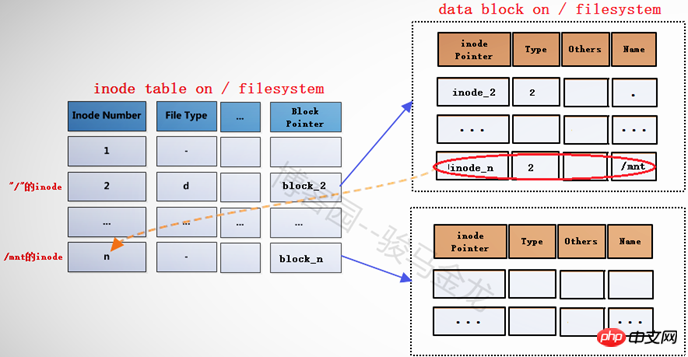
当文件系统/dev/cdrom挂载到/mnt上后,/mnt此时就已经成为另一个文件系统的入口了,因此它需要连接两边文件系统的inode和data block。但是如何连接呢?如下图。
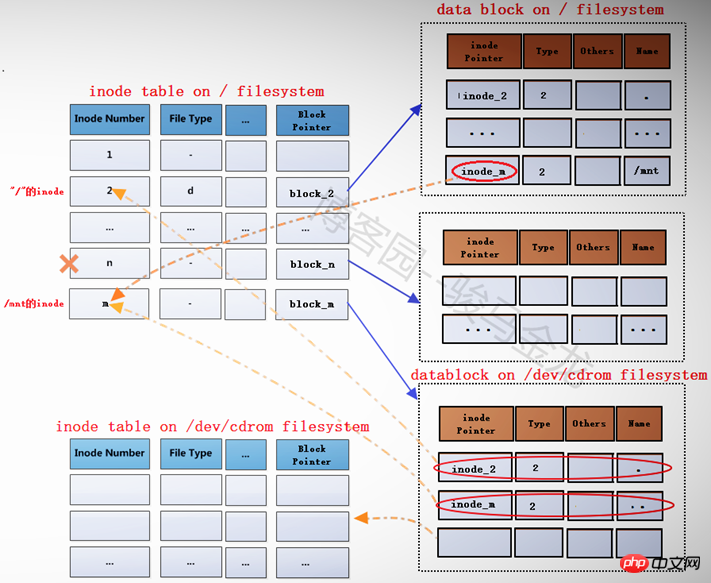
在根文件系统的inode table中,为/mnt重新分配一个inode记录m,该记录的block指针block_m指向文件系统/dev/cdrom中的data block。既然为/mnt分配了新的inode记录m,那么在"/"目录的data block中,也需要修改其inode指针为inode_m以指向m记录。同时,原来inode table中的inode记录n就被标记为暂时不可用。
block_m指向的是文件系统/dev/cdrom的data block,所以严格说起来,除了/mnt的元数据信息即inode记录m还在根文件系统上,/mnt的data block已经是在/dev/cdrom中的了。这就是挂载新文件系统后实现的跨文件系统,它将挂载点的元数据信息和数据信息分别存储在不同的文件系统上。
挂载完成后,将在/proc/self/{mounts,mountstats,mountinfo}这三个文件中写入挂载记录和相关的挂载信息,并会将/proc/self/mounts中的信息同步到/etc/mtab文件中,当然,如果挂载时加了-n参数,将不会同步到/etc/mtab。
而卸载文件系统,其实质是移除临时新建的inode记录(当然,在移除前会检查是否正在使用)及其指针,并将指针指回原来的inode记录,这样inode记录中的block指针也就同时生效而找回对应的data block了。由于卸载只是移除inode记录,所以使用挂载点和文件系统都可以实现卸载,因为它们是联系在一起的。
下面是分析或结论。
(1).挂载点挂载时的inode记录是新分配的。
# 挂载前挂载点/mnt的inode号
[root@server2 tmp]# ll -id /mnt100663447 drwxr-xr-x. 2 root root 6 Aug 12 2015 /mnt [root@server2 tmp]# mount /dev/cdrom /mnt
# 挂载后挂载点的inode号 [root@server2 tmp]# ll -id /mnt 1856 dr-xr-xr-x 8 root root 2048 Dec 10 2015 mnt
由此可以验证,inode号确实是重新分配的。
(2).挂载后,挂载点的内容将暂时不可见、不可用,卸载后文件又再次可见、可用。
# 在挂载前,向挂载点中创建几个文件 [root@server2 tmp]# touch /mnt/a.txt [root@server2 tmp]# mkdir /mnt/abcdir
# 挂载 [root@server2 tmp]# mount /dev/cdrom /mnt # 挂载后,挂载点中将找不到刚创建的文件 [root@server2 tmp]# ll /mnt total 636-r--r--r-- 1 root root 14 Dec 10 2015 CentOS_BuildTag dr-xr-xr-x 3 root root 2048 Dec 10 2015 EFI-r--r--r-- 1 root root 215 Dec 10 2015 EULA-r--r--r-- 1 root root 18009 Dec 10 2015 GPL dr-xr-xr-x 3 root root 2048 Dec 10 2015 images dr-xr-xr-x 2 root root 2048 Dec 10 2015 isolinux dr-xr-xr-x 2 root root 2048 Dec 10 2015 LiveOS dr-xr-xr-x 2 root root 612352 Dec 10 2015 Packages dr-xr-xr-x 2 root root 4096 Dec 10 2015 repodata-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-7-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-Testing-7-r--r--r-- 1 root root 2883 Dec 10 2015 TRANS.TBL # 卸载后,挂载点/mnt中的文件将再次可见 [root@server2 tmp]# umount /mnt [root@server2 tmp]# ll /mnt total 0drwxr-xr-x 2 root root 6 Jun 9 08:18 abcdir-rw-r--r-- 1 root root 0 Jun 9 08:18 a.txt
La raison pour laquelle cela se produit est qu'une fois le système de fichiers monté, l'enregistrement d'inode d'origine du point de montage est temporairement marqué comme indisponible. La clé est qu'il n'y a pas de pointeur d'inode pointant vers l'enregistrement d'inode. Après la désinstallation du système de fichiers, l'enregistrement d'inode d'origine du point de montage est réactivé et le pointeur d'inode de mnt dans le répertoire "/" pointe à nouveau vers l'enregistrement d'inode.
(3). Après le montage, les métadonnées et le bloc de données du point de montage sont stockés sur différents systèmes de fichiers.
(4). Même une fois le point de montage monté, il appartient toujours au fichier du système de fichiers source.
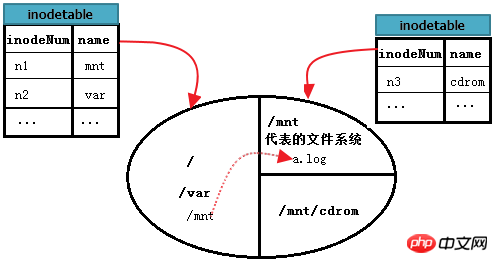
Supposons que le cercle dans l'image ci-dessous représente un disque dur divisé en 3 zones, c'est-à-dire 3 systèmes de fichiers. Parmi eux, root est le système de fichiers racine, /mnt est l'entrée d'un autre système de fichiers A, le système de fichiers A est monté sur /mnt, /mnt/cdrom est également l'entrée du système de fichiers B et le système de fichiers B est monté sur /mnt/cdrom supérieur. Chaque système de fichiers gère certaines tables d'inodes. On suppose que la table d'inodes dans la figure est une table de collection de tables d'inodes dans tous les groupes de blocs de chaque système de fichiers.

Comment lire /var/log/messages ? Il s'agit d'une lecture de fichiers dans le même système de fichiers que "/", qui a été expliquée en détail dans le système de fichiers unique précédent.
Mais comment lire /mnt/a.log dans le système de fichiers A ? Tout d'abord, recherchez l'enregistrement d'inode de /mnt à partir du système de fichiers racine. Il s'agit d'une recherche dans un seul système de fichiers ; puis localisez le bloc de données de /mnt en fonction du pointeur de bloc de cet enregistrement d'inode. système de fichiers A ; Ensuite, lisez l'enregistrement a.log à partir du bloc de données de /mnt et localisez enfin l'enregistrement d'inode correspondant à a.log dans la table d'inodes du système de fichiers A en fonction du pointeur d'inode de a.log ; recherchez un à partir du pointeur de bloc de cet enregistrement de journal d'inode. À ce stade, le contenu du fichier /mnt/a.log peut être lu.
L'image ci-dessous peut décrire le processus ci-dessus plus complètement.
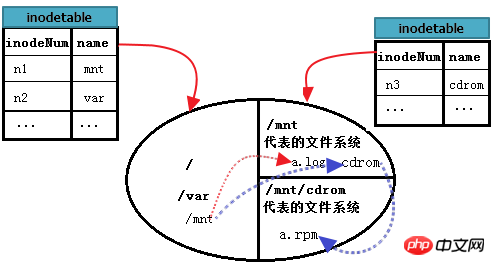
Alors comment lire /mnt/cdrom/a.rpm dans /mnt/cdrom ? Le point de montage du système de fichiers B représenté ici par cdrom se trouve sous /mnt, il reste donc une étape supplémentaire. Recherchez d'abord "/", puis recherchez mnt à la racine, entrez dans le système de fichiers mnt, recherchez le bloc de données du cdrom, puis entrez cdrom pour trouver a.rpm. En d’autres termes, l’emplacement où sont stockés les fichiers du répertoire mnt est la racine, l’emplacement où les fichiers du répertoire cdrom sont stockés est mnt et enfin l’emplacement où est stocké a.rpm est cdrom.
Continuez à améliorer l'image ci-dessus. comme suit.
Par rapport au système de fichiers ext2, ext3 a un journal supplémentaire fonction.
Dans le système de fichiers ext2, il n'y a que deux zones : la zone de données et la zone de métadonnées. En cas de panne de courant soudaine lors du remplissage des données dans le bloc de données, la cohérence des données et l'état du système de fichiers seront vérifiés au prochain démarrage. Cette vérification et cette réparation peuvent prendre beaucoup de temps, voire ne pas être réparées. après le contrôle. La raison pour laquelle cela se produit est qu'après une perte soudaine d'alimentation du système de fichiers, il ne sait pas où commence et se termine le bloc du dernier fichier stocké, il analysera donc l'intégralité du système de fichiers pour l'exclure (peut-être qu'il est vérifié de cette façon ).
Lors de la création d'un système de fichiers ext3, celui-ci sera divisé en trois zones : la zone de données, la zone de journal et la zone de métadonnées. Chaque fois que des données sont stockées, les activités de la zone de métadonnées dans ext2 sont d'abord effectuées dans la zone de journalisation. Ce n'est que lorsque le fichier est marqué comme validé que les données de la zone de journal sont transférées vers la zone de métadonnées. En cas de panne de courant soudaine lors du stockage de fichiers, la prochaine fois que vous vérifierez et réparerez le système de fichiers, il vous suffira de vérifier les enregistrements dans la zone de journal, de marquer le bloc de données correspondant au bmap comme inutilisé et de marquer le numéro d'inode. comme inutilisé, de sorte que vous n'avez pas besoin d'analyser l'intégralité du fichier. Le système prend beaucoup de temps.
Bien qu'ext3 ait une zone de journalisation de plus qu'ext2, qui convertit la zone de métadonnées, les performances d'ext3 sont légèrement inférieures à celles d'ext2, en particulier lors de l'écriture de nombreux petits fichiers. Cependant, en raison d'autres optimisations d'ext3, il n'y a presque aucun écart de performances entre ext3 et ext2.
Rappelant les formats de stockage précédents des systèmes de fichiers ext2 et ext3, il utilise des blocs comme unités de stockage, et chaque bloc utilise des bits bmap sont utilisés pour marquer s'ils sont libres. Bien que l'efficacité soit améliorée en optimisant la méthode de division des groupes de blocs, bmap est toujours utilisé à l'intérieur d'un groupe de blocs pour marquer les blocs du groupe de blocs. Pour un fichier volumineux, numériser l’intégralité du bmap sera un projet énorme. De plus, en termes d'adressage d'inodes, ext2/3 utilise des méthodes d'adressage direct et indirect. Pour les pointeurs indirects à trois niveaux, le nombre de pointeurs pouvant être parcourus est très, très énorme.
La plus grande caractéristique du système de fichiers ext4 est qu'il est géré en utilisant le concept d'étendue (étendue ou segment) basé sur ext3. Une étendue contient autant de blocs physiquement contigus que possible. L'adressage des inodes a également été amélioré à l'aide de l'arborescence des sections.
Par défaut, EXT4 n'utilise plus la méthode d'allocation de mappage de blocs d'EXT3, mais utilise à la place la méthode d'allocation d'étendue.
(1). Concernant les caractéristiques structurelles de EXT4
EXT4 est similaire à EXT3 dans sa structure globale. Les grandes directions d'allocation sont basées sur des groupes de blocs de même taille et l'allocation à l'intérieur. chaque groupe de blocs est fixe Nombre d'inodes, superbloc (ou sauvegarde) possible et GDT.
La structure des inodes d'EXT4 a été considérablement modifiée Afin d'ajouter de nouvelles informations, la taille a été augmentée de 128 octets d'EXT3 aux 256 octets par défaut. Dans le même temps, l'index d'adressage des inodes n'est plus utilisé. Le mode d'indexation "12 direct" d'EXT3 est "bloc d'adressage + 1 bloc d'adressage indirect de premier niveau + 1 bloc d'adressage indirect de deuxième niveau + 1 bloc d'adressage indirect de troisième niveau", et est remplacé par 4 flux de fragments d'étendue, chaque flux de fragments est set Le numéro du bloc de départ du fragment et le nombre de blocs consécutifs (il peut pointer directement vers la zone de données, ou il peut pointer vers la zone du bloc d'index).
Le flux de fragments est la zone verte dans le bloc de nœud d'index (bloc de nœud inde) dans la figure ci-dessous, chacun 15 octets, soit un total de 60 octets.
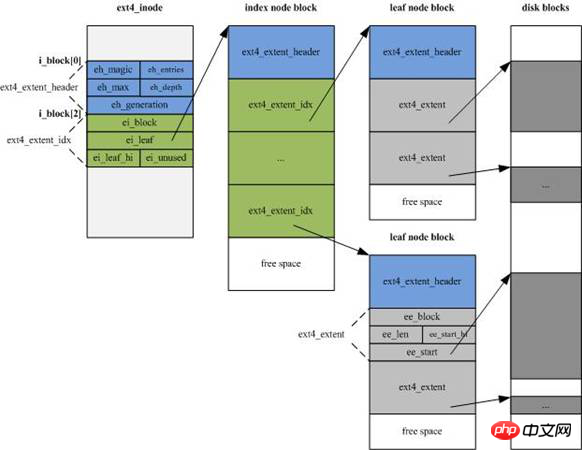
(2). EXT4 supprime les modifications structurelles des données.
Après la suppression des données, EXT4 libérera les bits d'espace bitmap du système de fichiers, mettra à jour la structure des répertoires et libérera les bits d'espace inode dans l'ordre.
(3). ext4 utilise l'allocation multi-blocs.
Lors du stockage des données, l'allocateur de bloc dans ext3 ne peut allouer que des blocs de 4 Ko à la fois, et bmap est marqué une fois avant que chaque bloc ne soit stocké. Si un fichier 1G est stocké et que la taille du bloc est de 4 Ko, alors l'allocateur de bloc sera appelé une fois après le stockage de chaque bloc, c'est-à-dire que le nombre d'appels est de 1024*1024/4 Ko = 262144 fois et le nombre de fois que bmap est marqué est également 1024*1024/4= 262 144 fois.
Dans ext4, l'allocation est basée sur des sections. Il est possible d'allouer un groupe de blocs consécutifs en appelant une fois l'allocateur de bloc, et de marquer d'un coup le bmap correspondant avant de stocker ce groupe de blocs. Cela améliore considérablement l’efficacité du stockage pour les fichiers volumineux.
Le plus gros inconvénient est qu'il divise tout ce qui doit être divisé lors de la création du système de fichiers. alloué directement lorsqu'il est utilisé, ce qui signifie qu'il ne prend pas en charge le partitionnement dynamique et l'allocation dynamique. Pour les partitions plus petites, la vitesse est correcte, mais pour un très gros disque, la vitesse est extrêmement lente. Par exemple, si vous formatez une baie de disques de plusieurs dizaines de téraoctets dans un système de fichiers ext4, vous risquez de perdre toute patience.
Outre la vitesse de formatage ultra lente, le système de fichiers ext4 est toujours très préférable. Bien entendu, les systèmes de fichiers développés par différentes sociétés ont leurs propres caractéristiques. Le plus important est de choisir le type de système de fichiers approprié en fonction de vos besoins.
Un système de fichiers peut être créé après le formatage de chaque partition. De nombreux systèmes de fichiers peuvent être reconnus sous Linux, donc comment. pour l'identifier ? De plus, lorsque nous exploitons les fichiers de la partition, nous n'avons pas précisé à quel système de fichiers il appartient. Comment nos utilisateurs peuvent-ils exploiter différents systèmes de fichiers de manière indiscriminée ? C'est ce que fait un système de fichiers virtuel.
Le système de fichiers virtuel fournit une interface commune permettant aux utilisateurs d'exploiter différents systèmes de fichiers, de sorte que les utilisateurs n'ont pas besoin de considérer le type de système de fichiers sur lequel se trouve le fichier lors de l'exécution d'un programme et le type d'appels système. doivent être utilisés. Fonctions système pour faire fonctionner le fichier. Avec le système de fichiers virtuel, il vous suffit d'appeler l'appel système de VFS pour tous les programmes qui doivent être exécutés, et VFS vous aidera à terminer les actions restantes.
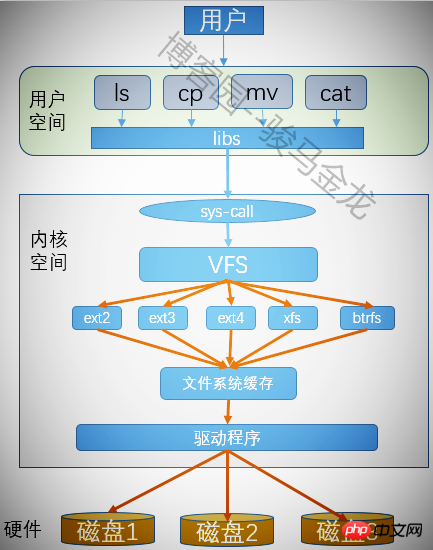
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Caractères tronqués commençant par ^quxjg$c
Caractères tronqués commençant par ^quxjg$c
 Comment ouvrir le fichier img
Comment ouvrir le fichier img
 Vous avez besoin de l'autorisation de l'administrateur pour apporter des modifications à ce fichier
Vous avez besoin de l'autorisation de l'administrateur pour apporter des modifications à ce fichier
 Quel est le format du document ?
Quel est le format du document ?
 Quel est le système Honor ?
Quel est le système Honor ?
 Qu'est-ce qu'un fichier TmP
Qu'est-ce qu'un fichier TmP
 Quel fichier est .exe
Quel fichier est .exe
 Quel est le principe et le mécanisme du dubbo
Quel est le principe et le mécanisme du dubbo








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



