
 développement back-end
Tutoriel Python
Scrapy capture des exemples de reportages universitaires
développement back-end
Tutoriel Python
Scrapy capture des exemples de reportages universitaires
Scrapy capture des exemples de reportages universitaires

Récupérez toutes les demandes d'actualité sur le site officiel de l'École d'administration publique de l'Université du Sichuan ().
Processus expérimental
1. Déterminez la cible d'exploration.
2. .
3. Règles d'exploration « Écrire/Déboguer ».
4. Obtenir les données d'exploration
1. Déterminer la cible d'exploration
La cible que nous devons explorer cette fois est le Sichuan. Toutes les actualités et informations sur l'École de politique publique et de gestion de l'Université. Nous devons donc connaître la structure de mise en page du site officiel de l'École de politique publique et de gestion.
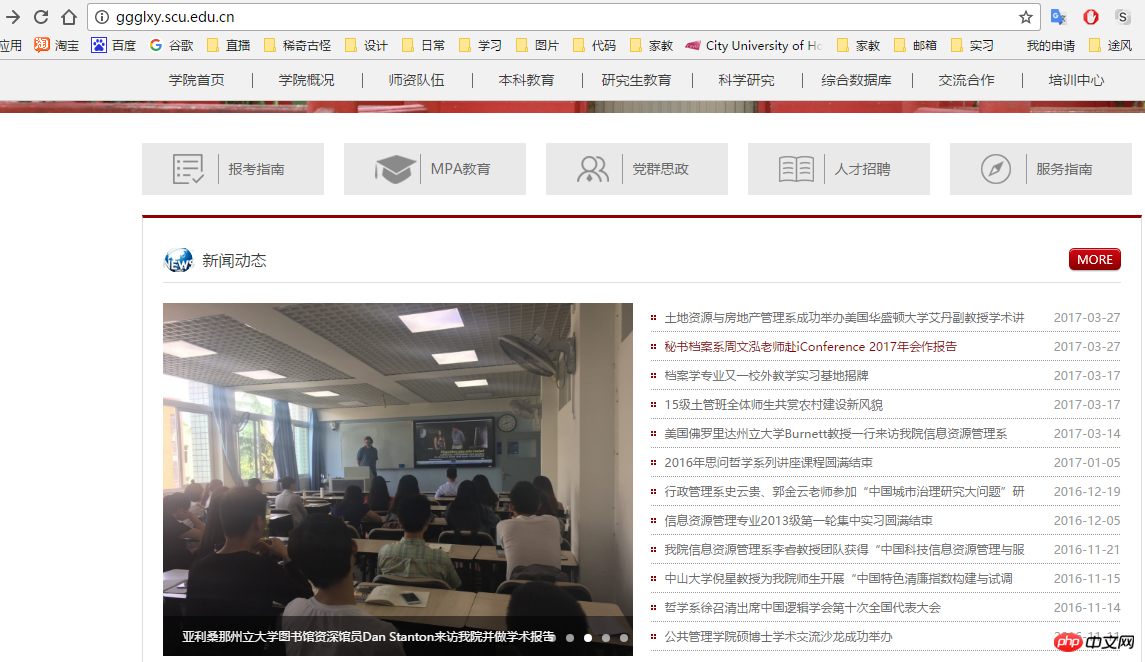
<.>WeChat screenshot_20170515223045.png

Paste_Image .png
Nous avons vu la rubrique actualités spécifique, mais cela ne correspond évidemment pas à notre exploration Besoins : la page Web d'actualités actuelle ne peut explorer que l'heure, le titre et l'URL de l'actualité, mais elle ne peut pas capturer le contenu de l'actualité. Nous devons donc accéder à la page de détails de l'actualité pour capturer le contenu spécifique de l'actualité
2. Formuler des règles d'exploration
Grâce à l'analyse de la première partie, nous penserons que si nous voulons récupérer les informations spécifiques d'une actualité, nous devons cliquer sur la page d'actualité pour entrer. la page de détails de l'actualité pour récupérer le contenu spécifique de l'actualité. Cliquons sur une actualité pour l'essayer
 Paste_Image.png
Paste_Image.pngNous avons constaté cela. nous pouvons récupérer les données dont nous avons besoin directement à partir de la page de détails de l'actualité : titre, heure, contenu.URL.
D'accord, nous avons maintenant une idée claire desaisir une actualité. Mais comment. explorer tout le contenu de l'actualité ?
Ce n'est évidemment pas difficile pour nous
Donc, pour organiser nos pensées, nous pouvons penser à une règle d'exploration évidente :
3. Règles d'exploration « Écriture/Débogage »
Afin de réduire au maximum la granularité du débogage du robot. combinera les modules d'écriture et de débogage.
Dans le robot d'exploration, je mettrai en œuvre les points fonctionnels suivants :3. Explorez toutes les actualités via une boucle. Les points de connaissance correspondants de
sont. :
1. Explorer les données de base sous une page.
2. Explorer deux fois les données analysées.3. Explorer toutes les données de la page Web via une boucle.3.1 Grimpez tous les liens d'actualités sous la colonne d'actualités sur une seule page
Sans plus tarder, commençons maintenant.


Testez et réussissez !
import scrapyclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
<. 🎜>Écriture du code
Après intégration dans le code d'origine, il y a :#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):item = GgglxyItem()item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()item['href'] = responseitem['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")item['content'] = data[0].xpath('string(.)').extract()[0]
yield itemimport scrapyfrom ggglxy.items import GgglxyItemclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())#调用新闻抓取方法yield scrapy.Request(url, callback=self.parse_dir_contents)#进入新闻详情页的抓取方法 def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]yield item
A ce moment, nous ajoutons une boucle :
NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUM
yield scrapy.Request(next_url, callback=self.parse)import scrapyfrom ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())yield scrapy.Request(URL, callback=self.parse_dir_contents)global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield item
抓到的数量为191,但是我们看官网发现有193条新闻,少了两条.
为啥呢?我们注意到log的error有两条:
定位问题:原来发现,学院的新闻栏目还有两条隐藏的二级栏目:
比如:

对应的URL为

URL都长的不一样,难怪抓不到了!
那么我们还得为这两条二级栏目的URL设定专门的规则,只需要加入判断是否为二级栏目:
if URL.find('type') != -1: yield scrapy.Request(URL, callback=self.parse)
组装原函数:
import scrapy
from ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())if URL.find('type') != -1:yield scrapy.Request(URL, callback=self.parse)yield scrapy.Request(URL, callback=self.parse_dir_contents)
global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield item测试:

我们发现,抓取的数据由以前的193条增加到了238条,log里面也没有error了,说明我们的抓取规则OK!
4.获得抓取数据
<code class="haxe"> scrapy crawl <span class="hljs-keyword">new<span class="hljs-type">s_info_2 -o <span class="hljs-number">0016.json</span></span></span></code><br/><br/>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Scrapy implémente l'exploration et l'analyse des articles du compte public WeChat
Jun 22, 2023 am 09:41 AM
Scrapy implémente l'exploration et l'analyse des articles du compte public WeChat
Jun 22, 2023 am 09:41 AM
Scrapy met en œuvre l'exploration d'articles et l'analyse des comptes publics WeChat. WeChat est une application de médias sociaux populaire ces dernières années, et les comptes publics qui y sont exploités jouent également un rôle très important. Comme nous le savons tous, les comptes publics WeChat sont un océan d’informations et de connaissances, car chaque compte public peut publier des articles, des messages graphiques et d’autres informations. Ces informations peuvent être largement utilisées dans de nombreux domaines, tels que les reportages médiatiques, la recherche universitaire, etc. Ainsi, cet article expliquera comment utiliser le framework Scrapy pour explorer et analyser les articles du compte public WeChat. Scr
 Analyse de cas Scrapy : Comment explorer les informations de l'entreprise sur LinkedIn
Jun 23, 2023 am 10:04 AM
Analyse de cas Scrapy : Comment explorer les informations de l'entreprise sur LinkedIn
Jun 23, 2023 am 10:04 AM
Scrapy est un framework d'exploration basé sur Python qui peut obtenir rapidement et facilement des informations pertinentes sur Internet. Dans cet article, nous utiliserons un cas Scrapy pour analyser en détail comment explorer les informations d'une entreprise sur LinkedIn. Déterminer l'URL cible Tout d'abord, nous devons indiquer clairement que notre cible est les informations de l'entreprise sur LinkedIn. Par conséquent, nous devons trouver l’URL de la page d’informations sur l’entreprise LinkedIn. Ouvrez le site Web LinkedIn, saisissez le nom de l'entreprise dans le champ de recherche et
 Méthode d'implémentation de chargement asynchrone Scrapy basée sur Ajax
Jun 22, 2023 pm 11:09 PM
Méthode d'implémentation de chargement asynchrone Scrapy basée sur Ajax
Jun 22, 2023 pm 11:09 PM
Scrapy est un framework d'exploration Python open source qui peut obtenir rapidement et efficacement des données à partir de sites Web. Cependant, de nombreux sites Web utilisent la technologie de chargement asynchrone Ajax, ce qui empêche Scrapy d'obtenir directement des données. Cet article présentera la méthode d'implémentation de Scrapy basée sur le chargement asynchrone Ajax. 1. Principe de chargement asynchrone Ajax Chargement asynchrone Ajax : Dans la méthode de chargement de page traditionnelle, une fois que le navigateur a envoyé une requête au serveur, il doit attendre que le serveur renvoie une réponse et charge la page entière avant de passer à l'étape suivante.
 Conseils d'optimisation Scrapy : Comment réduire l'exploration des URL en double et améliorer l'efficacité
Jun 22, 2023 pm 01:57 PM
Conseils d'optimisation Scrapy : Comment réduire l'exploration des URL en double et améliorer l'efficacité
Jun 22, 2023 pm 01:57 PM
Scrapy est un puissant framework d'exploration Python qui peut être utilisé pour obtenir de grandes quantités de données sur Internet. Cependant, lors du développement de Scrapy, nous rencontrons souvent le problème de l'exploration des URL en double, ce qui fait perdre beaucoup de temps et de ressources et affecte l'efficacité. Cet article présentera quelques techniques d'optimisation de Scrapy pour réduire l'exploration des URL en double et améliorer l'efficacité des robots d'exploration Scrapy. 1. Utilisez les attributs start_urls et Allowed_domains dans le robot d'exploration Scrapy pour
 Comment ouvrir du contenu d'actualités et d'intérêt sur Windows 10
Jan 13, 2024 pm 05:54 PM
Comment ouvrir du contenu d'actualités et d'intérêt sur Windows 10
Jan 13, 2024 pm 05:54 PM
Pour les utilisateurs profondément amoureux du système d'exploitation Windows 10, ils doivent avoir remarqué la fonction de recommandation d'informations et d'intérêts présentée dans le coin inférieur droit de leur bureau. Cette fonctionnalité vous montrera toutes sortes d'informations intéressantes au bon moment. Cependant, certains utilisateurs peuvent la trouver trop lourde et choisir de la désactiver, tandis que d'autres préfèrent la laisser activée. À l’heure actuelle, vous pouvez suivre les étapes détaillées suivantes pour ajuster facilement ces paramètres à tout moment et en tout lieu. Comment ouvrir les actualités et les centres d'intérêt dans Win10 1. Appuyez d'abord sur win+R, puis entrez « winver » et appuyez sur Entrée. Vous pouvez ensuite vérifier les informations de version de votre ordinateur pour confirmer s'il s'agit de la version 21h1. 2. Faites un clic droit sur la barre des tâches et sélectionnez "Informations et intérêts" 3. Ici
 Exemple de récupération d'informations Instagram à l'aide de PHP
Jun 13, 2023 pm 06:26 PM
Exemple de récupération d'informations Instagram à l'aide de PHP
Jun 13, 2023 pm 06:26 PM
Instagram est aujourd’hui l’un des réseaux sociaux les plus populaires, avec des centaines de millions d’utilisateurs actifs. Les utilisateurs téléchargent des milliards de photos et de vidéos, et ces données sont très précieuses pour de nombreuses entreprises et particuliers. Par conséquent, dans de nombreux cas, il est nécessaire d’utiliser un programme pour récupérer automatiquement les données Instagram. Cet article expliquera comment utiliser PHP pour capturer des données Instagram et fournira des exemples de mise en œuvre. Installer l'extension cURL pour PHP cURL est un outil utilisé dans divers
 Utilisation de Selenium et PhantomJS dans le robot Scrapy
Jun 22, 2023 pm 06:03 PM
Utilisation de Selenium et PhantomJS dans le robot Scrapy
Jun 22, 2023 pm 06:03 PM
Utilisation de Selenium et PhantomJSScrapy dans le robot d'exploration Scrapy Scrapy est un excellent framework de robot d'exploration Web sous Python et a été largement utilisé dans la collecte et le traitement de données dans divers domaines. Dans la mise en œuvre du robot, il est parfois nécessaire de simuler les opérations du navigateur pour obtenir le contenu présenté par certains sites Web. Dans ce cas, Selenium et PhantomJS sont nécessaires. Selenium simule les opérations humaines sur le navigateur, nous permettant d'automatiser les tests d'applications Web
 Utilisation approfondie de Scrapy : Comment explorer les données HTML, XML et JSON ?
Jun 22, 2023 pm 05:58 PM
Utilisation approfondie de Scrapy : Comment explorer les données HTML, XML et JSON ?
Jun 22, 2023 pm 05:58 PM
Scrapy est un puissant framework de robot d'exploration Python qui peut nous aider à obtenir des données sur Internet de manière rapide et flexible. Dans le processus d'exploration proprement dit, nous rencontrons souvent divers formats de données tels que HTML, XML et JSON. Dans cet article, nous présenterons comment utiliser Scrapy pour explorer respectivement ces trois formats de données. 1. Explorez les données HTML et créez un projet Scrapy. Tout d'abord, nous devons créer un projet Scrapy. Ouvrez la ligne de commande et entrez la commande suivante : scrapys
