

Beautiful Soup analyse tout ce que vous lui donnez et effectue la traversée de l'arbre pour vous. Cela fait référence à la visite de chaque nœud de l'arborescence une et une seule fois le long d'un certain itinéraire de recherche).
Nous appelons souvent la bibliothèque BeautifulSoup bs4. Pour importer la bibliothèque : from bs4 import BeautifulSoup. Parmi eux, import BeautifulSoup utilise principalement la classe BeautifulSoup dans bs4.
analyseur de bibliothèque bs4
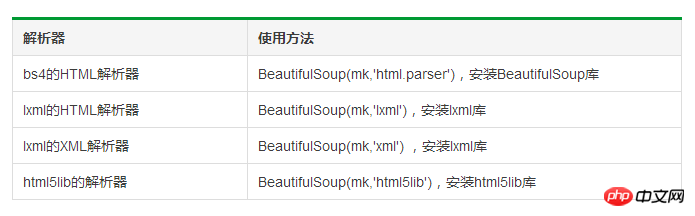 Éléments de base de la classe BeautifulSoup
Éléments de base de la classe BeautifulSoup
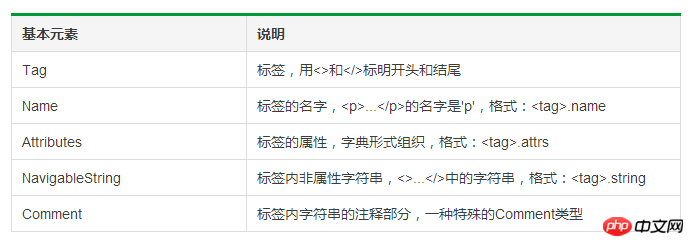
1 import requests 2 from bs4 import BeautifulSoup 3 4 res = requests.get('') 5 soup = BeautifulSoup(res.text,'lxml') 6 print(soup.a) 7 # 任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。 8 9 print(soup.a.name)10 # 每个<tag>都有自己的名字,可以通过<tag>.name获取,字符串类型11 12 print(soup.a.attrs)13 print(soup.a.attrs['class'])14 # 一个<tag>可能有一个或多个属性,是字典类型15 16 print(soup.a.string)17 # <tag>.string可以取到标签内非属性字符串18 19 soup1 = BeautifulSoup('<p><!--这里是注释--></p>','lxml')20 print(soup1.p.string)21 print(type(soup1.p.string))22 # comment是一种特殊类型,也可以通过<tag>.string取到a
{'href' : '', 'class' : [ 'non -login']} ['no-login']
Connexion
Voici le commentaire
Parcours du contenu HTML de la bibliothèque bs4
HTML Le structure de base de
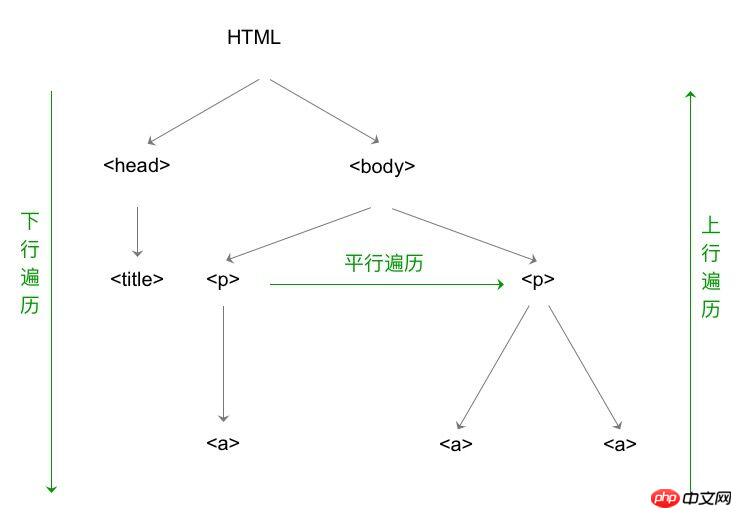 Parcours vers le bas de l'arbre de balises
Parcours vers le bas de l'arbre de balises
Parmi eux, le type BeautifulSoup est le nœud racine de l'arborescence des balises.
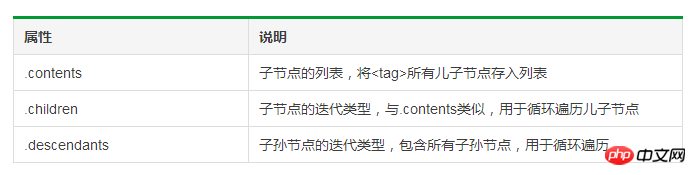
1 # 遍历儿子节点2 for child in soup.body.children:3 print(child.name)4 5 # 遍历子孙节点6 for child in soup.body.descendants:7 print(child.name)

1 # 遍历所有先辈节点时,包括soup本身,所以要if...else...判断2 for parent in soup.a.parents:3 if parent is None:4 print(parent)5 else:6 print(parent.name)
div
div
body
html
[document]
Parcours parallèle de l'arbre de balises
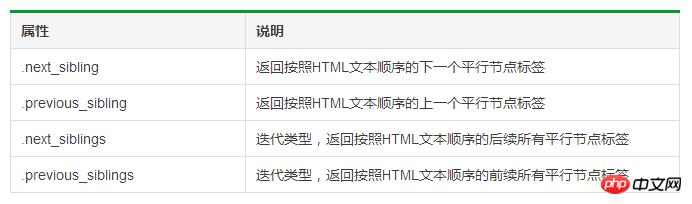
1 # 遍历后续节点2 for sibling in soup.a.next_sibling:3 print(sibling)4 5 # 遍历前续节点6 for sibling in soup.a.previous_sibling:7 print(sibling)
La méthode prettify() peut rendre le format de code plus standard, représenté par soup.prettify(). Dans PyCharm, utilisez print(soup.prettify()) pour afficher.
Environnement d'exploitation : Mac, Python 3.6, PyCharm 2016.2Référence : cours MOOC de l'université chinoise "Python Web Crawler and Information Extraction"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



