

Environnement de test MySQL
Le tableau de test est le suivant
create table test_table2 ( id int auto_increment primary key, pay_id int, pay_time datetime, other_col varchar(100) )
Construire Une procédure stockée insère des données de test. La caractéristique des données de test est que pay_id est répétable. Ici, lorsque la procédure stockée est traitée et que 3 millions de données sont insérées dans une boucle, un pay_id répété est inséré tous les 100 éléments de. data.Le champ d'heure est aléatoire dans une certaine plage
CREATE DEFINER=`root`@`%` PROCEDURE `test_insert`(IN `loopcount` INT) LANGUAGE SQLNOT DETERMINISTICCONTAINS SQL SQL SECURITY DEFINER COMMENT ''BEGINdeclare cnt int;set cnt = 0;while cnt< loopcount doinsert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());if (cnt mod 100 = 0) theninsert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());end if;set cnt = cnt + 1; end while;END
Exécuter l'appel test_insert(3000000); Insérer 303 000 lignes de données
 <🎜. >
<🎜. >
Cette méthode d'écriture est en effet moins efficace lorsque la quantité de données est importante, et aucun index n'est nécessaire
<🎜. >
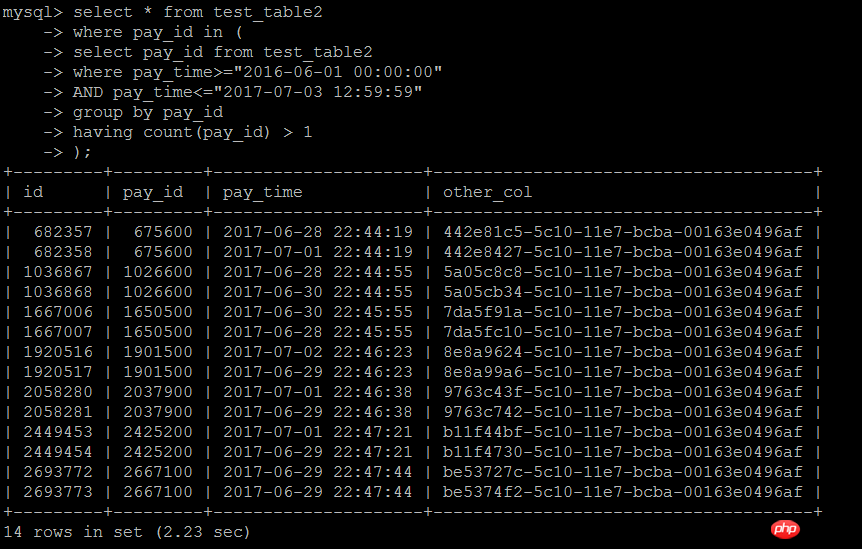
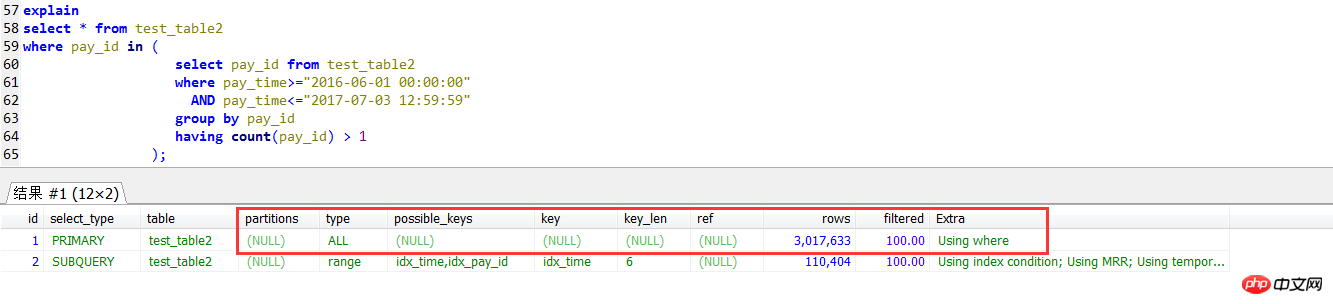
select * from test_table2 force index(idx_pay_id)where pay_id in ( select pay_id from test_table2 where pay_time>="2016-06-01 00:00:00" AND pay_time<="2017-07-03 12:59:59" group by pay_id having count(pay_id) > 1);
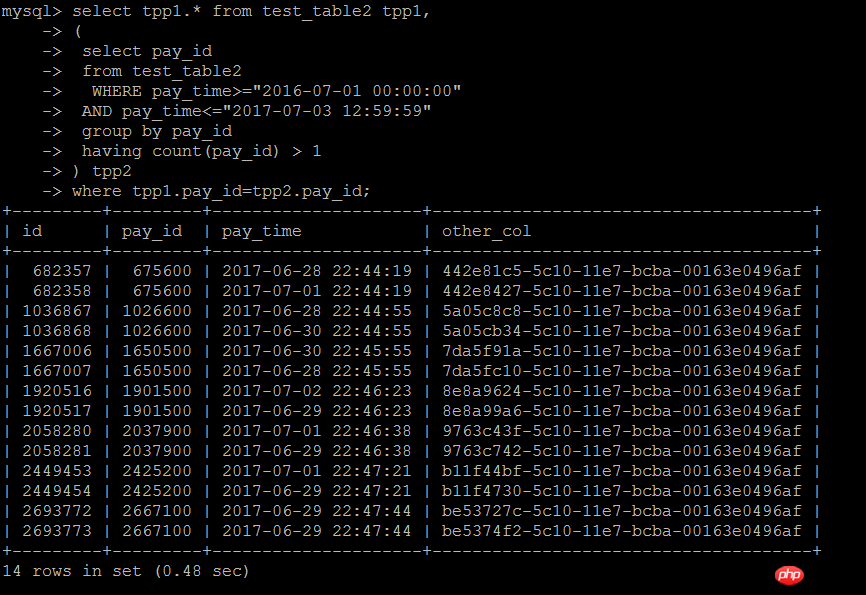
 La deuxième façon d'écrire est de se joindre à la sous-requête de cette façon. d'écriture est équivalente à la méthode d'écriture de sous-requête IN ci-dessus. Le test suivant a révélé que l'efficacité est effectivement bonne. Beaucoup d'améliorations
La deuxième façon d'écrire est de se joindre à la sous-requête de cette façon. d'écriture est équivalente à la méthode d'écriture de sous-requête IN ci-dessus. Le test suivant a révélé que l'efficacité est effectivement bonne. Beaucoup d'améliorations
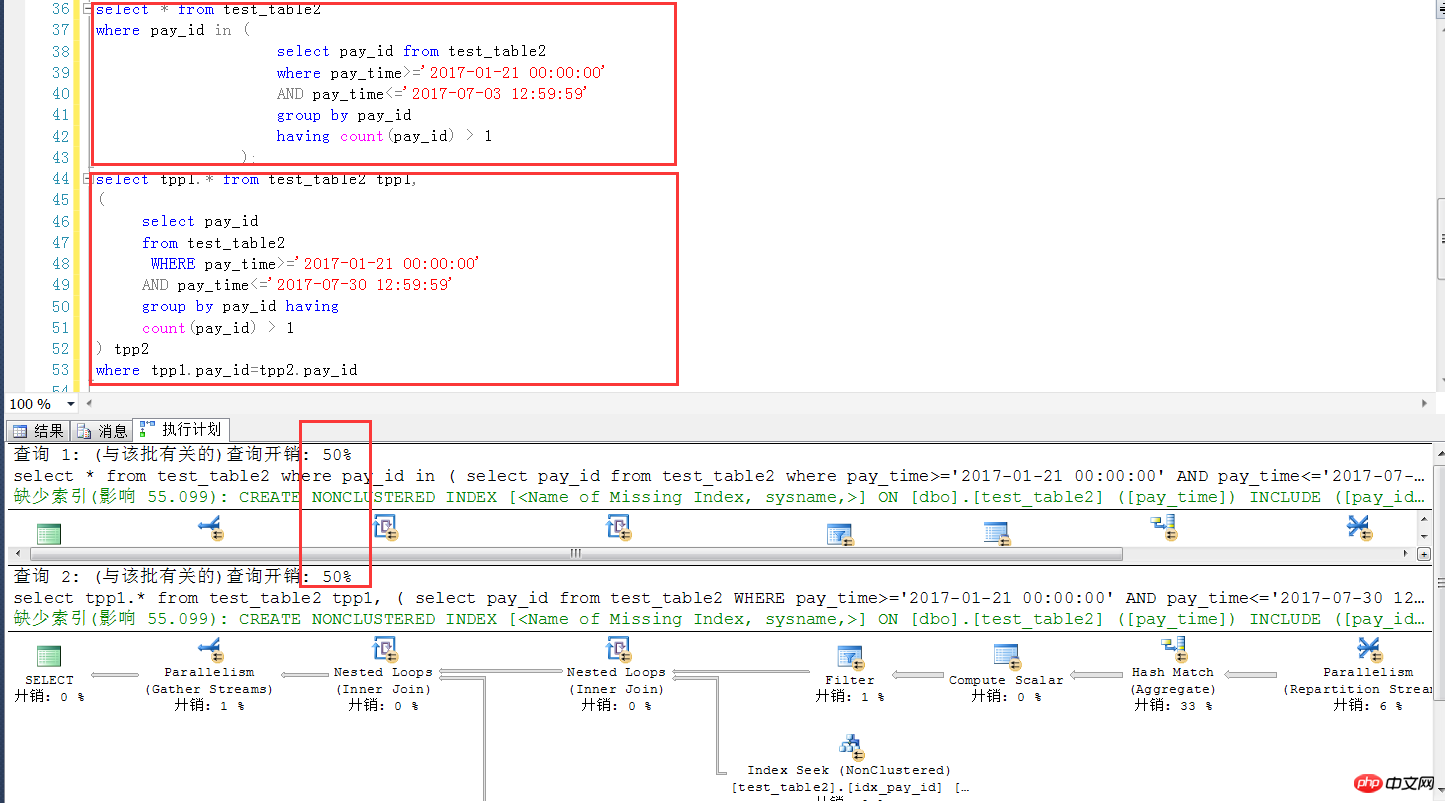
select tpp1.* from test_table2 tpp1,
( select pay_id
from test_table2
WHERE pay_time>="2016-07-01 00:00:00"
AND pay_time<="2017-07-03 12:59:59"
group by pay_id
having count(pay_id) > 1) tpp2
where tpp1.pay_id=tpp2.pay_id
 Dans le plan d'exécution de la sous-requête, recherchez la requête externe. Il s'agit d'une méthode d'analyse de table complète. L'index sur pay_id n'est pas utilisé.
Dans le plan d'exécution de la sous-requête, recherchez la requête externe. Il s'agit d'une méthode d'analyse de table complète. L'index sur pay_id n'est pas utilisé.
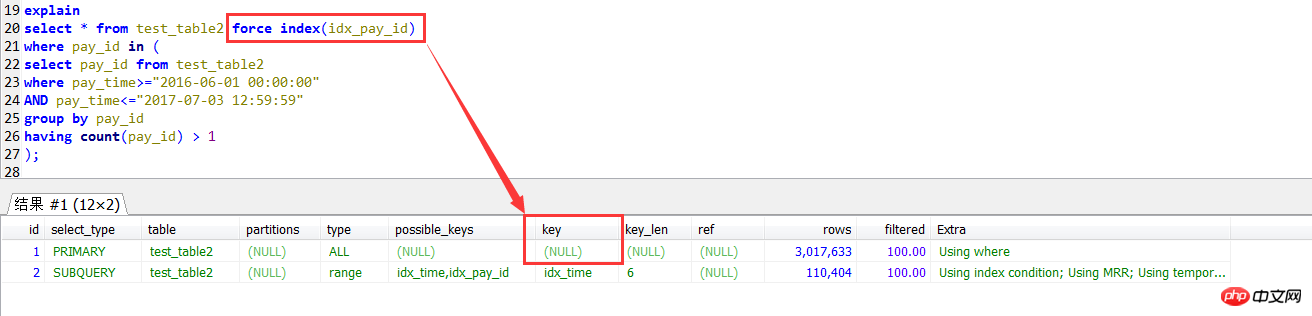
Plus tard, j'ai voulu utiliser l'indexation forcée pour la première méthode de requête. Bien qu'aucune erreur n'ait été signalée, j'ai trouvé que c'était le cas. était inutile du tout 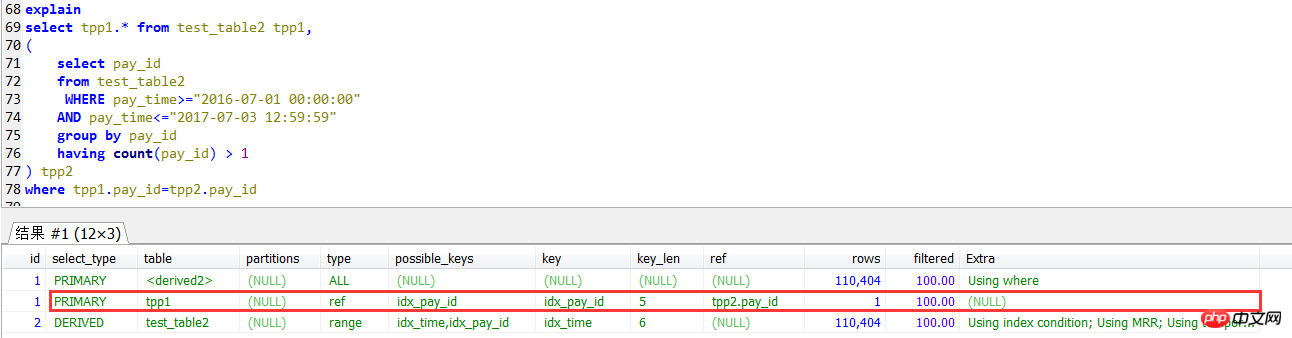
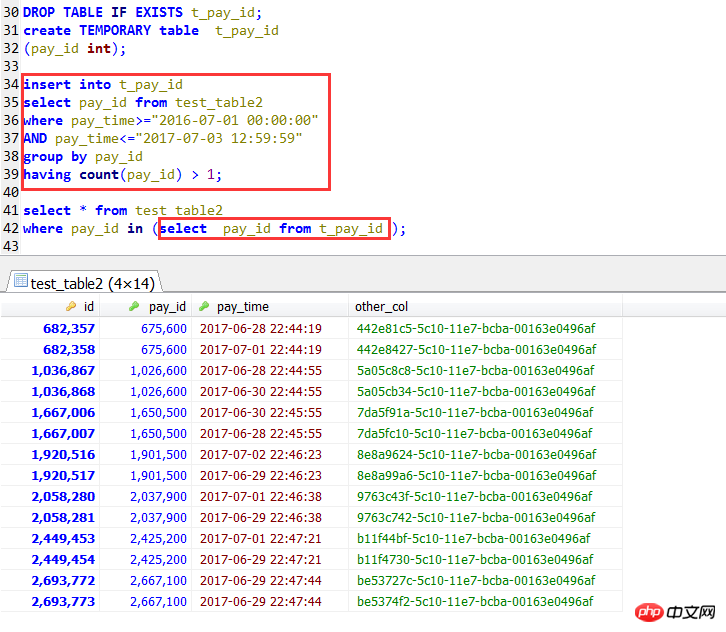
Si la sous-requête est une valeur directe, l'index peut être utilisé normalement.
On peut voir que la prise en charge par MySQL des sous-requêtes IN n'est en effet pas très bonne.

Ce qui suit est le script d'environnement de test dans sqlserver.
 Résumé : Dans les données MySQL, à partir de la version 5.7.18, les sous-requêtes IN doivent toujours être utilisées avec prudence
Résumé : Dans les données MySQL, à partir de la version 5.7.18, les sous-requêtes IN doivent toujours être utilisées avec prudence
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



