

Configurer python 2.7
bs4
requestsInstaller à l'aide de pip pour installer sudo pip install bs4
demandes d'installation sudo pip
Expliquez brièvement l'utilisation de bs4 Parce qu'il explore des pages Web, je vais présenter find et find_all
La différence entre find et find_all est. que les éléments renvoyés sont différents. find renvoie la première balise correspondante et le contenu de la balise
find_all renvoie une liste
Par exemple, nous écrivons un test.html pour tester la différence entre find et find_all. Le contenu est :
<html> <head> </head> <body> <div id="one"><a></a></div> <div id="two"><a href="#">abc</a></div> <div id="three"><a href="#">three a</a><a href="#">three a</a><a href="#">three a</a></div> <div id="four"><a href="#">four<p>four p</p><p>four p</p><p>four p</p> a</a></div> </body> </html>
<br/>
Ensuite, le code de test.py est :
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('div') print s.find_all('div') print "------------------------------" print s.find('div',id='one') print s.find_all('div',id='one') print "------------------------------" print s.find('div',id="two") print s.find_all('div',id="two") print "------------------------------" print s.find('div',id="three") print s.find_all('div',id="three") print "------------------------------" print s.find('div',id="four") print s.find_all('div',id="four") print "------------------------------"
<br/>
Après l'exécution, nous pouvons voir le résultat. Lors de l'obtention de la balise spécifiée, il n'y a pas beaucoup de différence entre les deux. Lors de l'obtention d'un groupe de balises, la différence entre les deux sera affichée. .
 <br/>
<br/>Il faut donc faire attention à ce que l'on veut en l'utilisant, sinon une erreur apparaîtra <br/> L'étape suivante consiste à obtenir les informations de la page Web via des demandes, je ne comprends pas très bien pourquoi d'autres écrivent sur ce que j'ai entendu et d'autres choses
J'ai directement accédé à la page Web, j'ai obtenu les pages Web de deuxième niveau de plusieurs catégories sur la prose. com via la méthode get, puis j'ai réussi un test de groupe pour explorer toutes les pages Web
def get_html():
url = ""
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel'] for doc in two_html:
i=1 if doc=='sanwen':print "running sanwen -----------------------------" if doc=='shige':print "running shige ------------------------------" if doc=='zawen':print 'running zawen -------------------------------' if doc=='suibi':print 'running suibi -------------------------------' if doc=='rizhi':print 'running ruzhi -------------------------------' if doc=='nove':print 'running xiaoxiaoshuo -------------------------' while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)if res.status_code==200:
soup(res.text)
i+=i
<br/>
Dans cette partie du code, je n'ai pas traitez le res.status_code qui n'est pas 200. Le problème qui en résulte est que l'erreur ne sera pas affichée et que le contenu analysé sera perdu. Ensuite, j'ai analysé la page Web de Sanwen.net et j'ai découvert qu'il s'agissait de www.sanwen.net/rizhi/&p=1
La valeur maximale de p est 10. Je ne comprends pas la dernière fois que j'ai exploré le disque, c'était 100 pages, je l'analyserai plus tard. Récupérez ensuite le contenu de chaque page via la méthode get. <br/>Après avoir obtenu le contenu de chaque page, il s'agit d'analyser l'auteur et le titre. Le code est comme ça
def soup(html_text):
s = BeautifulSoup(html_text,'lxml')
link = s.find('div',class_='categorylist').find_all('li') for i in link:if i!=s.find('li',class_='page'):
title = i.find_all('a')[1]
author = i.find_all('a')[2].text
url = title.attrs['href']
sign = re.compile(r'(//)|/')
match = sign.search(title.text)
file_name = title.text if match:
file_name = sign.sub('a',str(title.text))
<br/>
Là. C'est une triche lors de l'obtention du titre, je voudrais vous demander pourquoi vous ajoutez des barres obliques dans le titre de votre prose, non seulement une mais aussi deux. Ce problème a directement provoqué une erreur dans le nom du fichier lorsque j'ai écrit le fichier. plus tard, j'ai donc écrit une expression régulière et je vous la donnerai. Changez de carrière. <br/>La dernière étape consiste à obtenir le contenu en prose. Grâce à l'analyse de chaque page, obtenir l'adresse de l'article, puis obtenir directement le contenu, à l'origine, je voulais l'obtenir un par un directement en changeant l'adresse de la page web, ce qui évite des ennuis.
def get_content(url):
res = requests.get(''+url) if res.status_code==200:
soup = BeautifulSoup(res.text,'lxml')
contents = soup.find('div',class_='content').find_all('p')
content = ''for i in contents:
content+=i.text+'\n'return content
<br/>
Enfin, écrivez le fichier et enregistrez-le ok
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n')
f.write(author+'\n')
content=get_content(url)
f.write(content)
f.close()
Trois fonctions sont utilisées pour obtenir de la prose sur Prose.com, mais il y a un problème est que je ne sais pas pourquoi de la prose est perdue. Je ne peux obtenir qu'environ 400 articles. les articles de Prose.com, mais c'est le cas. Je l'ai eu page par page. J'espère que quelqu'un pourra m'aider avec cette question. Peut-être devrions-nous rendre la page Web inaccessible. Bien sûr, je pense que cela a quelque chose à voir avec le réseau cassé dans mon dortoir
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n')
f.write(author+'\n')
content=get_content(url)
f.write(content)
f.close()
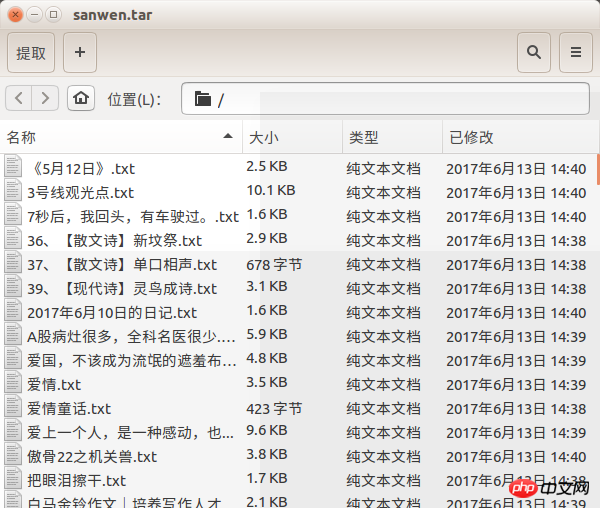
J'ai presque oublié. à propos du rendu

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



