

Comment mongoDB implémente-t-il la pagination ?

Cet article présente principalement en détail les deux méthodes de mongoDB pour implémenter la pagination Il a une certaine valeur de référence. Les amis intéressés peuvent s'y référer
La pagination de MongoDB. requête utilise les trois fonctions tableau de limit(), skip() et sort() pour effectuer une requête de pagination.
Ce qui suit sont mes données de test
db.test.find().sort({"age":1});

La première méthode
Interrogez les données de la première page : db.test.find().sort({"age":1}).limit(2); 🎜>


La deuxième méthode
Interroger les données de la première page : db.test.find().sort({"age":1}).limit( 2);
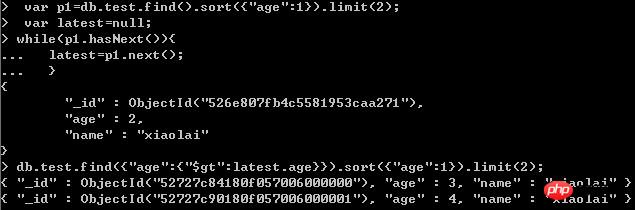
Skip saute trop d'enregistrements et l'efficacité est un peu faibleAprès un examen attentif, la deuxième méthode est. en effet ne convient pas au saut de page et n'est pas efficace non plus
Pour les données massives, nous devons effectuer un traitement spécial
Il existe les deux méthodes suivantes
<.>La première méthodeLimiter le nombre de pages de pagination, similaire au traitement de pagination de Baidu, qui ne fait que affiche les sept cents enregistrements précédents, comme celui-ci. Il n'est pas nécessaire de prendre en compte les problèmes de performances. Après tout, la plupart des gens se contentent de se tourner vers les dix premières pages et de trouver ce dont ils ont besoin 
Nous pouvons le faire en supposant qu'il soit trié en fonction. pour identifier, nous pouvons suivre l'identifiant. Le numéro de série de la page où se trouve l'identifiant est stocké dans redis/MemberCached,
comme ceci, en supposant que chaque page contient 10 enregistrements page d'identification1 12 1. . . 101112122. . . . 20 2De cette façon, lorsque nous vérifions la première page, nous pouvons récupérer directement dix éléments de données En supposant qu'il y ait 100 millions d'éléments de données, un enregistrement L'identifiant occupe 4 octets. Les autres informations occupent un octet et un enregistrement occupe 5 octets 1 0000 0000 *5/(1024*1024)=476MBCette approche utilise généralement l'espace pour le temps. La majeure partie du temps de requête de la base de données est consacrée à la connexion à la base de données. Le mettre dans le cache peut considérablement accélérer la requête.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment distinguer les vraies et fausses boîtes à chaussures de chaussures Nike (maîtrisez une astuce pour les identifier facilement)
Sep 02, 2024 pm 04:11 PM
Comment distinguer les vraies et fausses boîtes à chaussures de chaussures Nike (maîtrisez une astuce pour les identifier facilement)
Sep 02, 2024 pm 04:11 PM
En tant que marque de sport de renommée mondiale, les chaussures Nike ont attiré beaucoup d'attention. Cependant, il existe également un grand nombre de produits contrefaits sur le marché, notamment de fausses boîtes à chaussures Nike. Distinguer les véritables boîtes à chaussures des fausses est crucial pour protéger les droits et les intérêts des consommateurs. Cet article vous fournira quelques méthodes simples et efficaces pour vous aider à faire la distinction entre les vraies et les fausses boîtes à chaussures. 1 : Titre de l'emballage extérieur En observant l'emballage extérieur des boîtes à chaussures Nike, vous pouvez découvrir de nombreuses différences subtiles. Les véritables boîtes à chaussures Nike contiennent généralement des matériaux en papier de haute qualité, doux au toucher et sans odeur âcre évidente. Les polices et les logos des boîtes à chaussures authentiques sont généralement clairs et détaillés, et il n'y a pas de flou ni d'incohérence de couleur. 2 : titre de marquage à chaud du logo. Le logo sur les boîtes à chaussures Nike est généralement imprimé à chaud. La partie de marquage à chaud sur la boîte à chaussures authentique s'affichera.
 Comment configurer l'expansion automatique de MongoDB sur Debian
Apr 02, 2025 am 07:36 AM
Comment configurer l'expansion automatique de MongoDB sur Debian
Apr 02, 2025 am 07:36 AM
Cet article présente comment configurer MongoDB sur Debian System pour réaliser une expansion automatique. Les étapes principales incluent la configuration de l'ensemble de répliques MongoDB et de la surveillance de l'espace disque. 1. Installation de MongoDB Tout d'abord, assurez-vous que MongoDB est installé sur le système Debian. Installez à l'aide de la commande suivante: SudoaptupDaSudoaptInstall-myongoDB-Org 2. Configuration de la réplique MongoDB Ensemble de répliques MongoDB assure la haute disponibilité et la redondance des données, ce qui est la base de la réalisation d'une expansion de capacité automatique. Démarrer le service MongoDB: Sudosystemctlstartmongodsudosys
 Comment gérer le jitter vidéo (conseils pratiques pour vous aider à éliminer le jitter vidéo)
Sep 02, 2024 pm 03:53 PM
Comment gérer le jitter vidéo (conseils pratiques pour vous aider à éliminer le jitter vidéo)
Sep 02, 2024 pm 03:53 PM
Les tremblements sont un problème courant lors du tournage ou du visionnage de vidéos, qui affectent l'expérience visuelle et réduisent la qualité de la vidéo. Cet article présentera quelques conseils pratiques pour vous aider à résoudre les problèmes de gigue vidéo et à rendre vos vidéos plus stables et plus fluides. 1. Utilisez la technologie de stabilisation pour éliminer le tremblement de la vidéo L'utilisation d'un dispositif de stabilisation est l'un des moyens les plus simples et les plus efficaces pour résoudre le problème du tremblement de la vidéo. Les stabilisateurs peuvent réduire la gigue causée par les tremblements de la main ou d'autres facteurs en équilibrant et en stabilisant la caméra. 2. Introduction à la technologie logicielle de stabilisation vidéo La technologie logicielle de stabilisation vidéo élimine la gigue en ajustant la vidéo en post-traitement. Cette technologie peut fournir une meilleure stabilisation vidéo en suivant les images clés, en appliquant des algorithmes de stabilisation d'image, etc. 3. Détection de gigue vidéo et réparation automatique
 Comment assurer la haute disponibilité de MongoDB sur Debian
Apr 02, 2025 am 07:21 AM
Comment assurer la haute disponibilité de MongoDB sur Debian
Apr 02, 2025 am 07:21 AM
Cet article décrit comment construire une base de données MongoDB hautement disponible sur un système Debian. Nous explorerons plusieurs façons de garantir que la sécurité des données et les services continueront de fonctionner. Stratégie clé: réplicaset: réplicaset: Utilisez des répliques pour obtenir la redondance des données et le basculement automatique. Lorsqu'un nœud maître échoue, l'ensemble de répliques élise automatiquement un nouveau nœud maître pour assurer la disponibilité continue du service. Sauvegarde et récupération des données: utilisez régulièrement la commande Mongodump pour sauvegarder la base de données et formuler des stratégies de récupération efficaces pour faire face au risque de perte de données. Surveillance et alarmes: déploier les outils de surveillance (tels que Prometheus, Grafana) pour surveiller l'état de course de MongoDB en temps réel, et
 Comment rendre vos dépôts bancaires plus rentables (stratégie d'économie d'argent révélée)
Aug 21, 2024 pm 04:21 PM
Comment rendre vos dépôts bancaires plus rentables (stratégie d'économie d'argent révélée)
Aug 21, 2024 pm 04:21 PM
Dans la société moderne, nous sommes tous indissociables des comptes bancaires, et économiser de l’argent est l’interaction la plus fondamentale entre nous et les banques. Cependant, de nombreuses personnes ont des doutes et des confusions quant à la manière de rentabiliser leur épargne. Cet article vous fournira des conseils pratiques en matière d’économie d’argent pour vous aider à augmenter la valeur de votre épargne. Paragraphe 1 Plan financier : Un plan pour la croissance future de votre patrimoine L'élaboration d'un plan financier constitue la base d'une gestion et d'une croissance efficaces de votre épargne. Identifiez vos objectifs financiers, à court et à long terme. Développez un plan d’épargne spécifique basé sur ces objectifs, en définissant le moment, le montant et la méthode de dépôt requis pour chaque objectif. Révisez et ajustez régulièrement votre plan pour l’adapter aux conditions économiques changeantes et aux besoins personnels. Paragraphe 2 Choisir un compte d'épargne à intérêt élevé : augmenter le rendement des dépôts Choisir un taux d'intérêt élevé
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Mise à jour majeure de Pi Coin: PI Bank arrive!
Mar 03, 2025 pm 06:18 PM
Mise à jour majeure de Pi Coin: PI Bank arrive!
Mar 03, 2025 pm 06:18 PM
Pinetwork est sur le point de lancer Pibank, une plate-forme bancaire mobile révolutionnaire! Pinetwork a publié aujourd'hui une mise à jour majeure sur Elmahrosa (face) Pimisrbank, appelée Pibank, qui intègre parfaitement les services bancaires traditionnels avec des fonctions de crypto-monnaie de pignon (prend en charge l'échange entre les Fiat Currency tels que le Dollar, l'Euro, Usdt, Usdc, Ripiah avec des crypto-monnaies. Quel est le charme de Pibank? Découvrons! Les principales fonctions de Pibank: gestion unique des comptes bancaires et des actifs de crypto-monnaie. Soutenez les transactions en temps réel et adoptez les biospécies
 Comment chiffrer les données dans Debian MongoDB
Apr 12, 2025 pm 08:03 PM
Comment chiffrer les données dans Debian MongoDB
Apr 12, 2025 pm 08:03 PM
Le chiffrement de la base de données MongoDB sur un système Debian nécessite de suivre les étapes suivantes: Étape 1: Installez d'abord MongoDB, assurez-vous que votre système Debian a installé MongoDB. Sinon, veuillez vous référer au document officiel MongoDB pour l'installation: https://docs.mongodb.com/manual/tutorial/install-mongodb-on-debian/step 2: générer le fichier de clé de cryptage Créer un fichier contenant la clé de chiffrement et définir les permissions correctes: ddif = / dev / urandof = / etc / mongodb-keyfilebs = 512
